科研
大模型综述11月最新升级
日期:2023-11-30访问量:今年3月末,我们在arXiv网站发布了大语言模型综述文章《A Survey of Large Language Models》的第一个版本V1,该综述文章旨在系统地梳理大语言模型的研究进展与核心技术,讨论了大量的相关工作。自大语言模型综述的预印本上线以来,受到了不少读者的关注,我们在努力推动该综述文章的持续扩充与修订。

在发布V1版本后的8个月时间内,为了提升该综述的质量,我们在持续更新相关的内容,连续进行了多版的内容修订(版本号目前迭代到V13),论文篇幅从V1版本的51页、416篇参考文献,到V11版本的85页、610篇参考文献,到V12版本的97页、683篇参考文献,现在进一步扩增到V13版本的124页、946篇参考文献。继6月、9月发布于arXiv网站的大修版本V11、V12,V13版本是我们两个多月以来又一次进行大修的版本。
相较于V12版本,V13版本的大语言模型综述有以下新亮点:
1. 新增了对于Scaling law的深入讨论;
2. 新增了预训练数据调度的介绍以及从零准备大模型预训练数据的步骤和细节;
3. 新增了大模型增强长文本能力和解码策略的介绍;
4. 新增了指令微调数据最新工作的介绍和人类对齐中过程监督技术的介绍;
5. 完善了指令微调的实验分析,在量化章节新增了对指令微调模型进行量化的实验结果;
6. 调整了Utilization部分的内容组织,新增了自动提示优化章节和改进思维链提示技术的介绍;
7. 新增了关于大语言模型应用于研究社区不同方向(如多模态、智能体、知识图谱等)的介绍;
8. 增补了许多脉络梳理内容,以及大量最新工作介绍,添加或修改了大量配图、配表。
此外,我们综述的中文翻译版本目前的版本是V10,我们将加快翻译过程,使之与英文版本对齐:

论文链接:https://arxiv.org/abs/2303.18223
GitHub项目链接:https://github.com/RUCAIBox/LLMSurvey
中文翻译版本链接:https://github.com/RUCAIBox/LLMSurvey/blob/main/assets/LLM_Survey_Chinese.pdf
以下是综述部分章节的主要更新内容介绍,详细内容请参阅我们的英文综述。
1. 总览
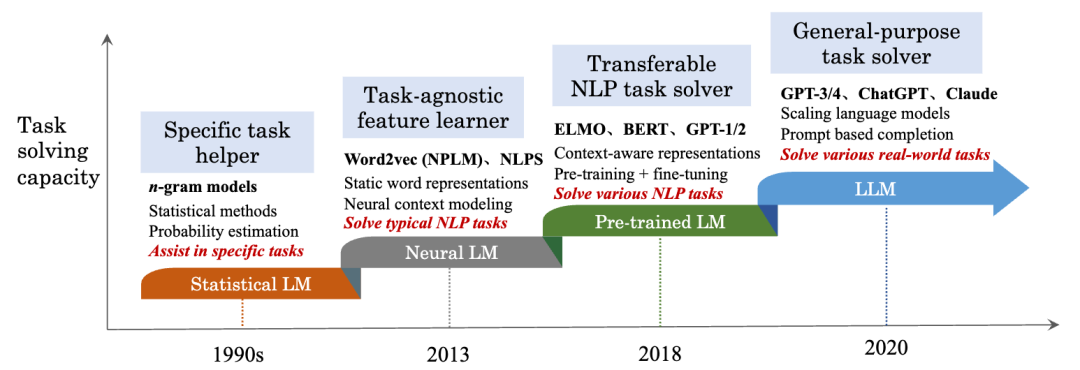
在Introduction章节,我们新增了对四代语言模型(统计语言模型、神经语言模型、预训练语言模型、大语言模型)的进化过程的介绍以及配图。对于语言模型的理解,可以从任务求解能力提升的角度去深入分析,这也是技术发展带来的重要思维范式上的变革。
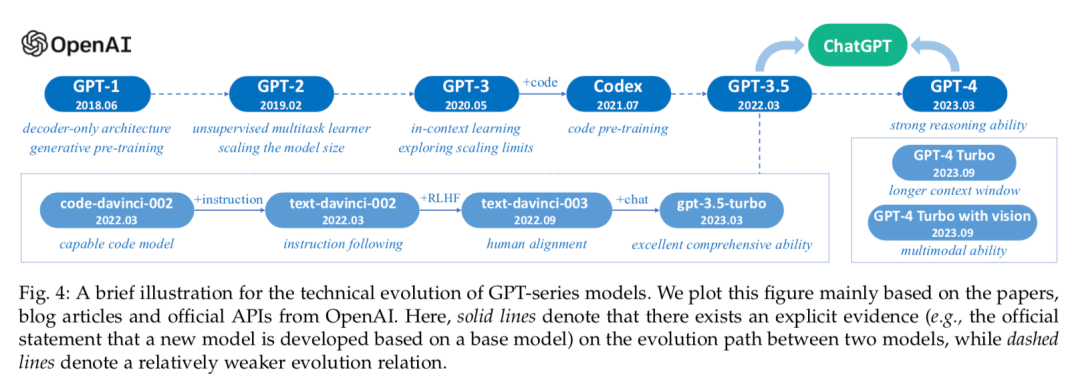
在Overview章节,我们新增了关于scaling law的深入讨论,主要是围绕predictable scaling和task-level predictability展开了相关介绍,并且介绍了scaling law与涌现能力间的一些讨论。同时,我们更新了GPT系列发展路径配图,加入了关于GPT-4v以及GPT-4 Turbo的文字介绍。
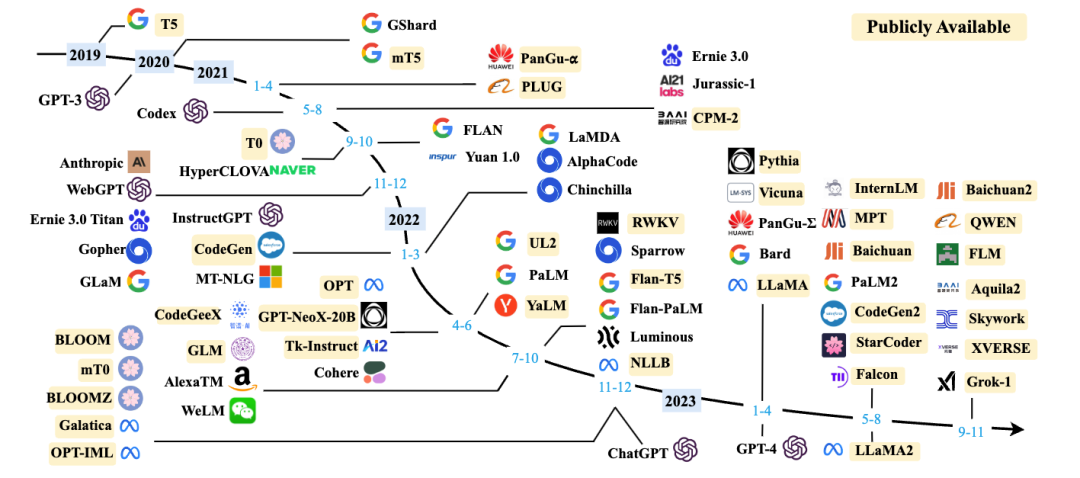
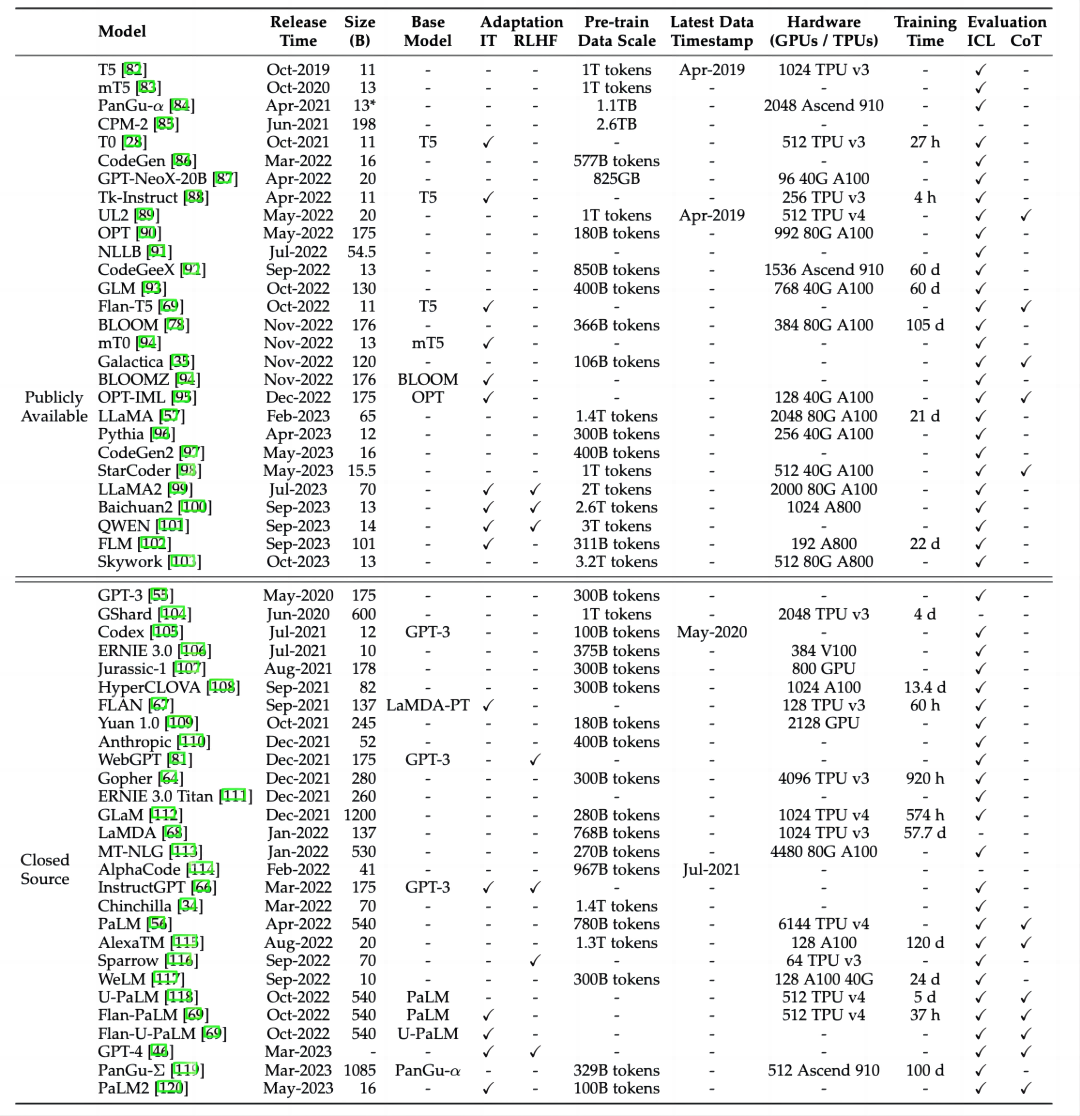
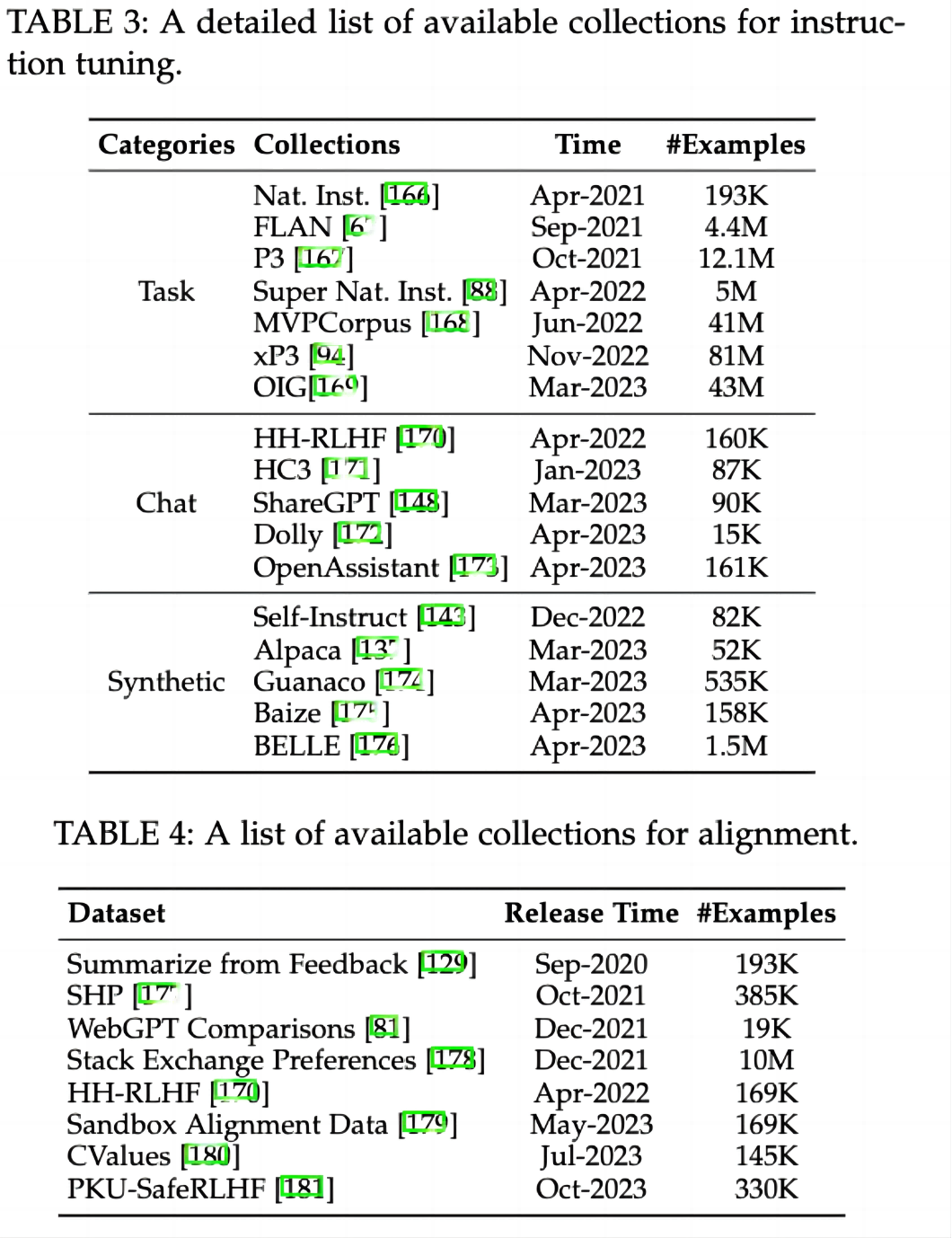
2. 大语言模型相关资源
我们对于最新符合条件的模型及API进行了补充,持续更新了现有的10B+的模型图和表格(如有遗漏,欢迎读者来信补充):
除此之外,我们还新增了指令微调和对齐的常用数据集介绍及相关表格:
3. 大语言模型预训练技术
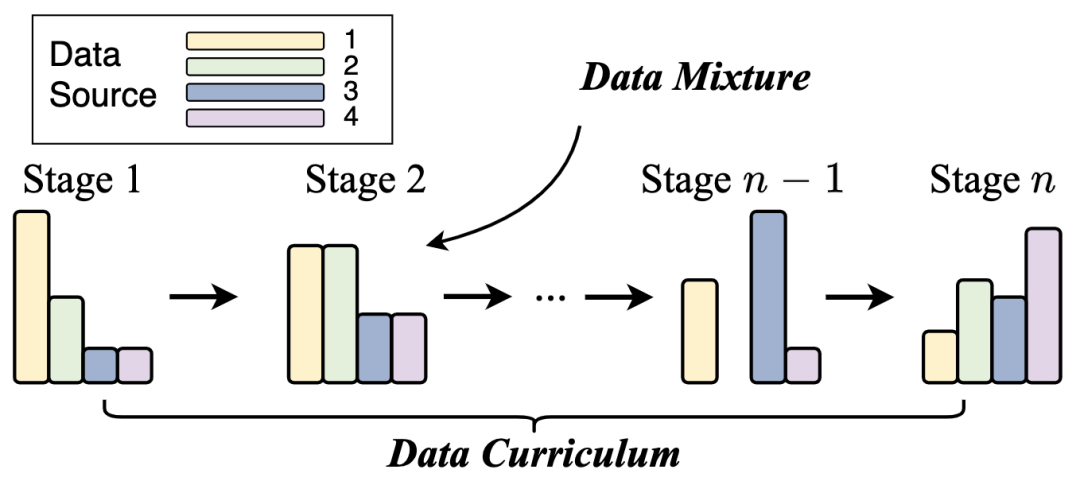
我们新增了数据调度(章节4.1.3),主要包含数据混合(Data Mixture)和数据课程(Data Curriculum)两部分。本章主要讨论,在预处理好多个来源的预训练数据后,要如何调整训练时不同来源数据的比例,以及这些不同来源数据用于训练的顺序,使得大模型在预训练阶段更快、更好地提升通用能力,或增强特定能力。具体而言,在数据混合部分,我们总结了设置好的数据混合的常见策略;在数据课程部分,我们则分析具体实例,讨论现有大模型如何利用数据课程提升其代码、数学、和长文本建模的能力。
在介绍预训练数据相关内容的最后,我们对预训练数据的准备进行总结(章节4.1.4)。本章节力求实用性,从数据收集、数据清洗和数据调度三方面串联从零准备大模型预训练数据的步骤和细节。
我们增加了长文本的子章节,针对面向长文本的位置编码拓展和上下文窗口适应进行了相关介绍。
此外,我们更新了解码策略章节,新增了近期的随机采样策略(例如对比采样);同时我们较为系统地介绍了解码环节中增量推理存在的“内存墙”问题,并介绍了减少数据传输(例如PagedAttention和Flash-Decoding)和优化解码算法(例如投机解码)两类策略。

4. 大语言模型适配技术
在指令微调部分中,我们新增了近期的指令微调研究工作,例如格式化日常聊天数据集的ShareGPT,格式化合成数据的WizardLM复杂化指令方法;我们也完善了关于指令微调需要少量数据还是大量数据的讨论。
在人类对齐部分中,我们新增了对过程监督技术的讨论。我们介绍了结果监督与过程监督对齐方法的区别、过程监督信号的收集与已有的相关数据集、过程监督信号的利用和模型的训练方法。
在内存高效模型适配(即量化)部分,我们新增了指令微调过后的模型(7B,13B)在16-bit,8-bit和4-bit量化下的实验结果。

5. 大语言模型使用技术
在大语言模型使用技术章节,我们大幅调整了Utilization一章的内容组织,新增了提示技术(Prompting)章节,其中的自动提示优化章节为本次新增内容,主要介绍离散提示优化(基于梯度、基于强化学习、基于编辑和基于大模型的方法)和连续提示优化(数据充足的提示学习和数据稀疏的提示迁移方法)。
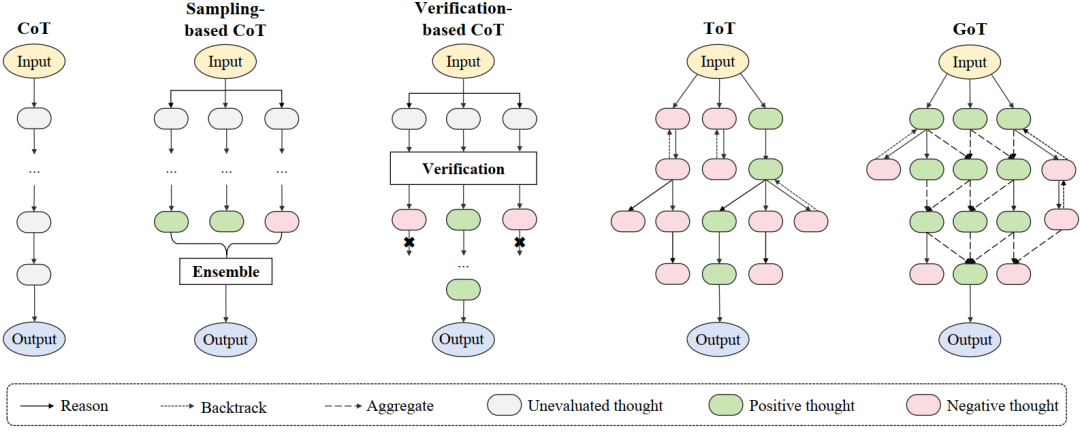
在思维链提示部分,我们新增了关于如何改进思维链提示技术的介绍,包括更优的提示设计、增强的思维链生成(基于采样和验证的方法)、以及推理结构的扩展(树、图),并且新增了多种提示技术的对比配图。
6. 大语言模型应用
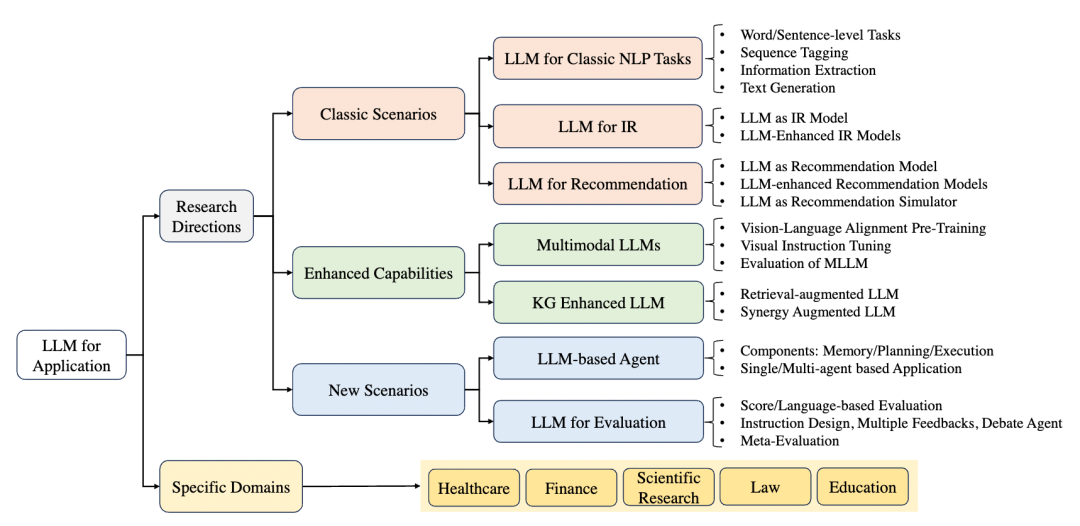
在大语言模型应用章节,我们新增了大语言模型对研究社区不同方向应用的介绍,包括大语言模型应用的典型场景(典型自然语言处理任务、信息检索、推荐系统)、能力强化(多模态、知识图谱)和新兴场景(智能体、自动化评测)。对于每个研究领域,我们讨论了大语言模型在该领域应用的背景、典型方法、影响、尚未解决的问题和未来的研究方向。这一部分也是本次重要更新的内容,也加入了我们对于这些研究方向的一些初步思考。
随后,我们也更新或重写了Conclusion章节的部分段落,对于未来研究重点进行了更好的梳理。
7. 综述定位
一篇高质量的长篇综述文章需要大量的时间投入,所参与的老师和学生为此付出了很多的时间。尽管我们已经尽力去完善这篇综述文章,但由于能力所限,难免存在不足和错误之处,仍有很大的改进空间。我们的最终目标是使这篇综述文章成为一个“know-how”的大模型技术指南手册,让大模型的秘密不再神秘、让技术细节不再被隐藏。尽管我们深知目前这篇综述离这个目标的距离还比较远,我们愿意在之后的版本中竭尽全力去改进。特别地,对于预训练、指令微调、提示工程的内在原理以及实战经验等方面,我们非常欢迎读者为我们贡献想法与建议,可以通过GitHub提交PR或者邮件联系我们的作者。对于所有被采纳的技术细节,我们都将在论文的致谢部分中“实名+实际贡献”进行致谢。
我们的综述文章自发布以来,收到了广泛网友的大量修改意见,在此一并表示感谢。也希望大家一如既往支持与关注我们的大模型综述文章,您们的点赞与反馈将是我们前行最大的动力。
8. 本次修订的参与学生名单
周昆(添加LLM for Classic NLP Task,新增图18)
李军毅(添加了自动提示优化方法的介绍)
唐天一(更新GPT发展路径图,更新解码策略章节,更新指令微调章节,添加量化实验)
王晓磊(添加 LLM-based Agent 章节,修改思维链提示章节)
侯宇蓬(添加数据调度的介绍,添加数据准备的总结,新增图8)
闵映乾(添加第三章少数模型、数据及相关介绍,更新表1,3,4、图2)
杨晨(更新表1,3,4、图2)
张北辰(添加LLM for Evaluation章节)
张君杰(添加LLM for Recommendation章节)
陈昱硕(更新解码策略章节,添加量化实验)
陈志朋(添加Process-Supervisied RLHF内容)
蒋锦昊(添加KGs for LLMs章节)
任瑞阳(添加LLM for IR章节)
汤昕宇(更新6.3节的结构和内容,新增图14,improved cot strategies章节)
刘沛羽(添加量化实验和分析)
董梓灿(添加4.2.4的long context章节)
都一凡(添加Multimodal large language model章节中的训练部分)
李依凡(添加Multimodal large language model章节中的评测部分)
刘子康(添加Multimodal large language model章节中的提升模型部分)
附:更新日志
第一章:新增图1,展示四代语言模型的进化过程;
第二章:新增对扩展法则的讨论,以及涌现能力与扩展法则的关系;新增了GPT-4v以及GPT-4 Turbo的介绍;
第三章:在图2和表格中新增最新的大语言模型,在3.1节中新增最新API的介绍,3.2节中新增常用于指令微调和对齐微调的数据集介绍,3.3节中新增若干库的介绍;
第四章:在4.1节中新增关于数据调度的讨论,包括数据混合和数据课程,新增4.2节中对数据准备的总结,4.3节中关于长上下文建模的讨论,4.4节中关于解码效率问题和最新解码策略的讨论;
第五章:新增5.1节中关于实例构建和调优策略的最新讨论,5.2节中关于过程监督的RLHF的最新讨论,以及在5.3节中对量化的LLaMA模型(7B和13B)的实证研究;
第六章:新增6.1节中关于提示优化的最新讨论,并更新6.3节中关于思维链提示的内容;第七章:新增7.1节中关于语言大模型在不同研究方向应用的最新讨论;
第八章:修订了几个方面的内容。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox