科研
大语言模型综述
日期:2023-06-05访问量:大语言模型综述文章
自20世纪50年代图灵测试被提出以来,研究人员一直在探索和开发能够理解并掌握语言的人工智能技术。作为重要的研究方向之一,语言模型得到了学术界的广泛研究,从早期的统计语言模型和神经语言模型开始,发展到基于Transformer的预训练语言模型。
近年来,研究者们发现通过扩大预训练语言模型的参数量和数据量,大语言模型(Large Language Model)能够在效果显著提升的同时,展示出许多小模型不具备的特殊能力(如上下文学习能力、逐步推理能力等)。最近,作为代表性的大语言模型应用ChatGPT展现出了超强的人机对话能力和任务求解能力,对于整个AI研究社区带来了重大影响。
为此,中国人民大学高瓴人工智能学院教师和学生调研了大语言模型的最新研究进展和主要技术路径,形成本领域的综述文章一篇,引用或介绍了相关论文420余篇,目前以预印版形式上传到arXiv网站,期望能为各位研究人员和工程人员提供一定的技术参考。

论文链接:
https://arxiv.org/abs/2303.18223
(已更新到第四个版本,第五个版本将于周二上线,补充了GPT系列模型的演化过程)
GitHub项目链接:
https://github.com/RUCAIBox/LLMSurvey
自预印版本上线以来,这篇综述文章得到了广泛关注,我们根据收到的读者建议改进了部分内容,目前更新到了第四个版本,并且会持续更新。同时,为了方便阅读,我们也在GitHub上传了一个由“大模型翻译+人工修正”的中文翻译版本(由于时间所限,中文翻译版本还在陆续更迭校验中,请大家以英文版本为准)。
下面针对各章节进行内容概括介绍,详细内容请参阅我们的英文综述。
一、总览
通常来说,大语言模型指的是那些在大规模文本语料上训练、包含百亿级别(或更多)参数的语言模型,例如GPT-3,PaLM,LLaMA等。目前的大语言模型采用与小模型类似的Transformer架构和预训练目标(如 Language Modeling),与小模型的主要区别在于增加模型大小、训练数据和计算资源。大语言模型的表现往往遵循扩展法则,但是对于某些能力,只有当语言模型规模达到某一程度才会显现,这些能力被称为“涌现能力”,代表性的涌现能力包括上下文学习、指令遵循、逐步推理等。目前,大语言模型取得如此巨大的成就,我们总结了五方面原因:
1)模型、数据和计算资源的扩展;
2)高效稳定的训练手段;
3)语言模型能力诱导;
4)对齐训练,将大语言模型与人类偏好对齐;
5)工具使用(潜在发展方向)。
二、大语言模型相关资源
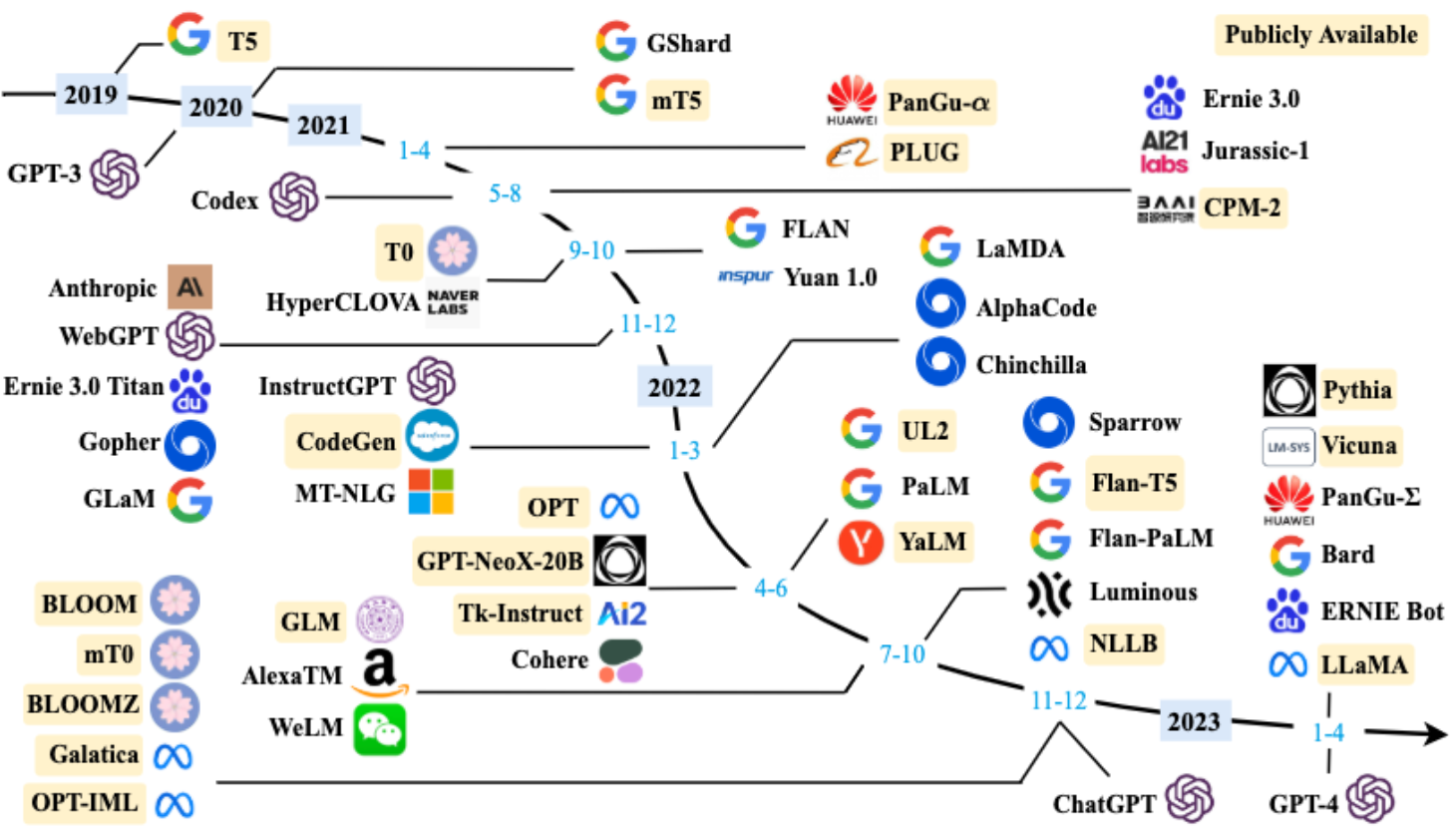
图1 大语言模型发展时间线
这一章的目的是为了帮助读者速览大规模语言模型的发展进程,概要了解模型的训练需求以及总结有助于训练的可用资源。我们简要总结了可以用于开发大语言模型的公开可用资源,包括模型检查点(model checkpoint)或公开接口(API),训练语料库以及代码库。
对于公开检查点的模型,我们根据模型参数量分成两大类,分别是百亿(10B)参数到千亿(100B)参数模型和大于千亿(100B)参数模型。在每一部分介绍时,我们根据模型的预训练语料、任务,或者评测给出研究不同能力时的推荐模型,并且根据模型原论文罗列了预训练硬件配置。
对于公开接口,我们重点介绍了OpenAI的GPT系列接口,包括GPT-3系列到当前的GPT-4系列,并简要介绍了部分接口之间的关系。
对于训练语料库,我们简要总结了一列常用于训练大语言模型的公开数据集。我们按照内容将这些数据集分成了六类:书籍类、CommonCrawl类、Reddit link类、维基百科类、代码类和其他。每一类我们都介绍了数据集的内容、大小以及被用于训练的模型。
对于代码库,我们搜集了一些用于训练的代码库,包括常用模型库和并行算法库。
三、大语言模型预训练技术
预训练是大语言模型能力的基础。当语言模型的参数量扩展到超千亿级别时,从头预训练一个大语言模型就成为一件十分困难且有挑战的事情。
(1)在数据层面,如何收集尽可能多的高质量语料对预训练模型的效果十分关键。本章从预训练语料的收集出发,主要探讨了数据的多种来源(如对话、代码等)和预处理(清洗与编码),并分析了预训练数据数量、质量、多样性等方面对模型效果的影响。
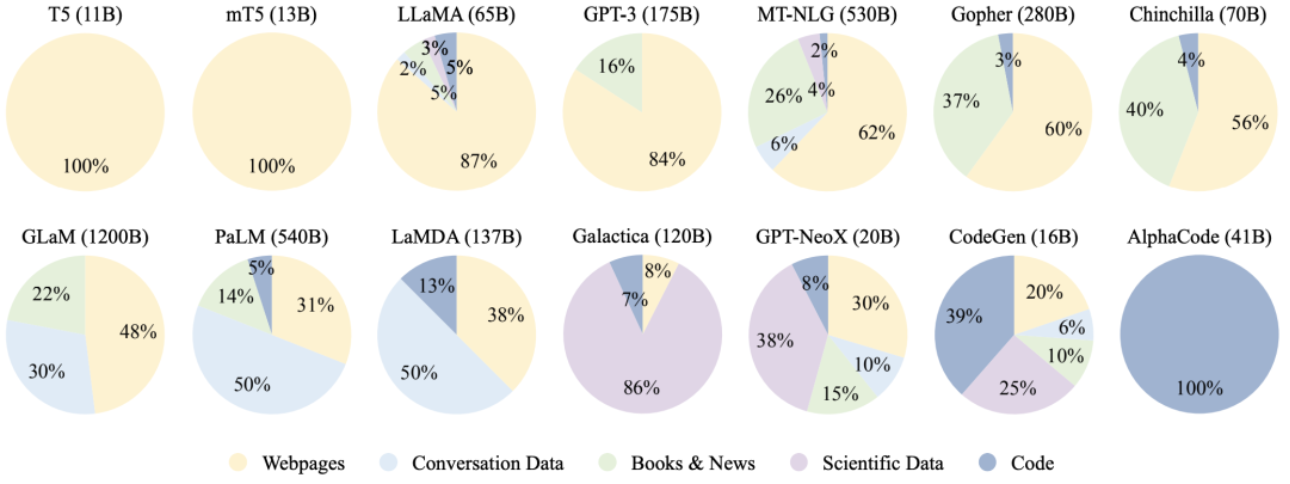
图2 现有大语言模型预训练数据中各种数据源的比例
(2)在模型层面,最引人关注的问题之一即是,为什么大语言模型往往采用 Decoder-Only 架构?本文从 Transformer 做语言模型的主干架构、具体模块和预训练任务三方面向读者们介绍如今大模型的常用方案,并在最后结合文献讨论大家选用 Decoder-Only 架构的原因。
(3)在训练层面,大参数量的模型非常难以优化。研究人员付出众多努力,提出了若干增加训练稳定性,及提升训练效率的方案。本章对 3D 并行、ZeRO 等被集成于 DeepSpeed 等代码库的相关训练技术进行归纳整理,并在最后对如何稳定、高效地预训练一个大语言模型给出建议。
四、大语言模型适配微调技术
预训练之后,“适配微调”(adaptation tuning)可以进一步增强大语言模型能力并满足人类偏好。本章主要介绍了两种适配微调技术:指令微调与对齐微调。
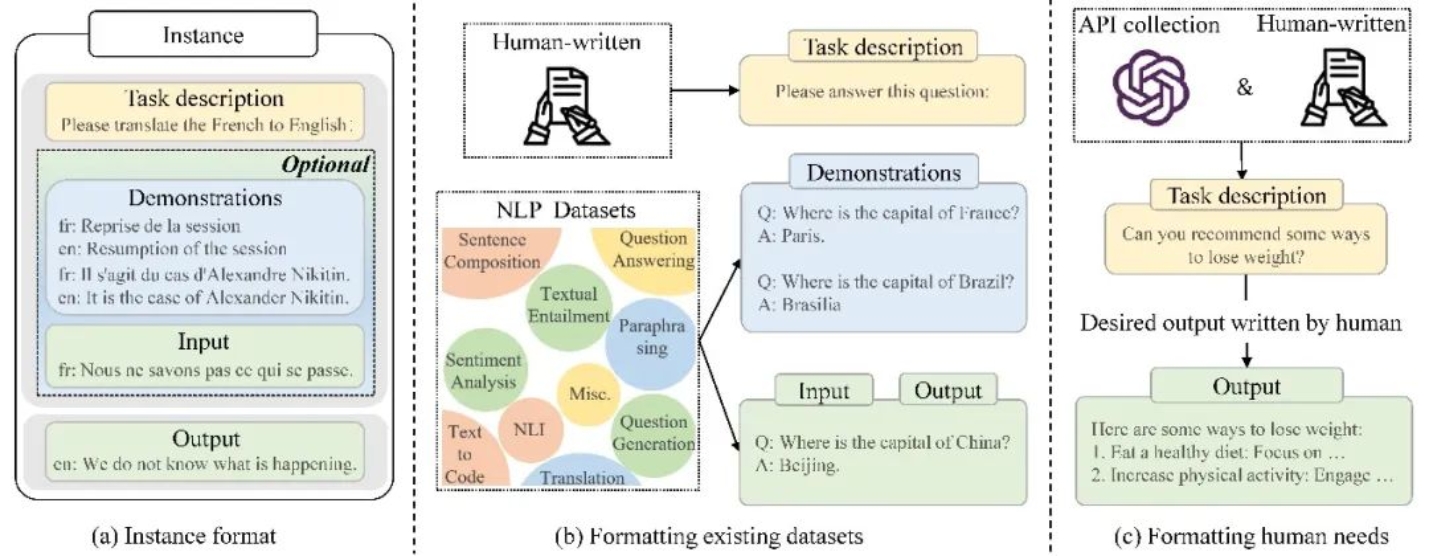
图3 指令格式实例示意图
●指令微调通过收集指令格式的实例(图3)来微调大模型,大大增强了模型遵循人类指令的能力,能够让模型更好地泛化到未知任务。我们展示了两种收集指令格式实例的方法,并讨论了任务数量、实例数量、实例设计等因素对指令微调效果的影响;同时,我们也总结了指令微调过程中常见的数据集合和训练细节,方便研究者训练自己的模型。
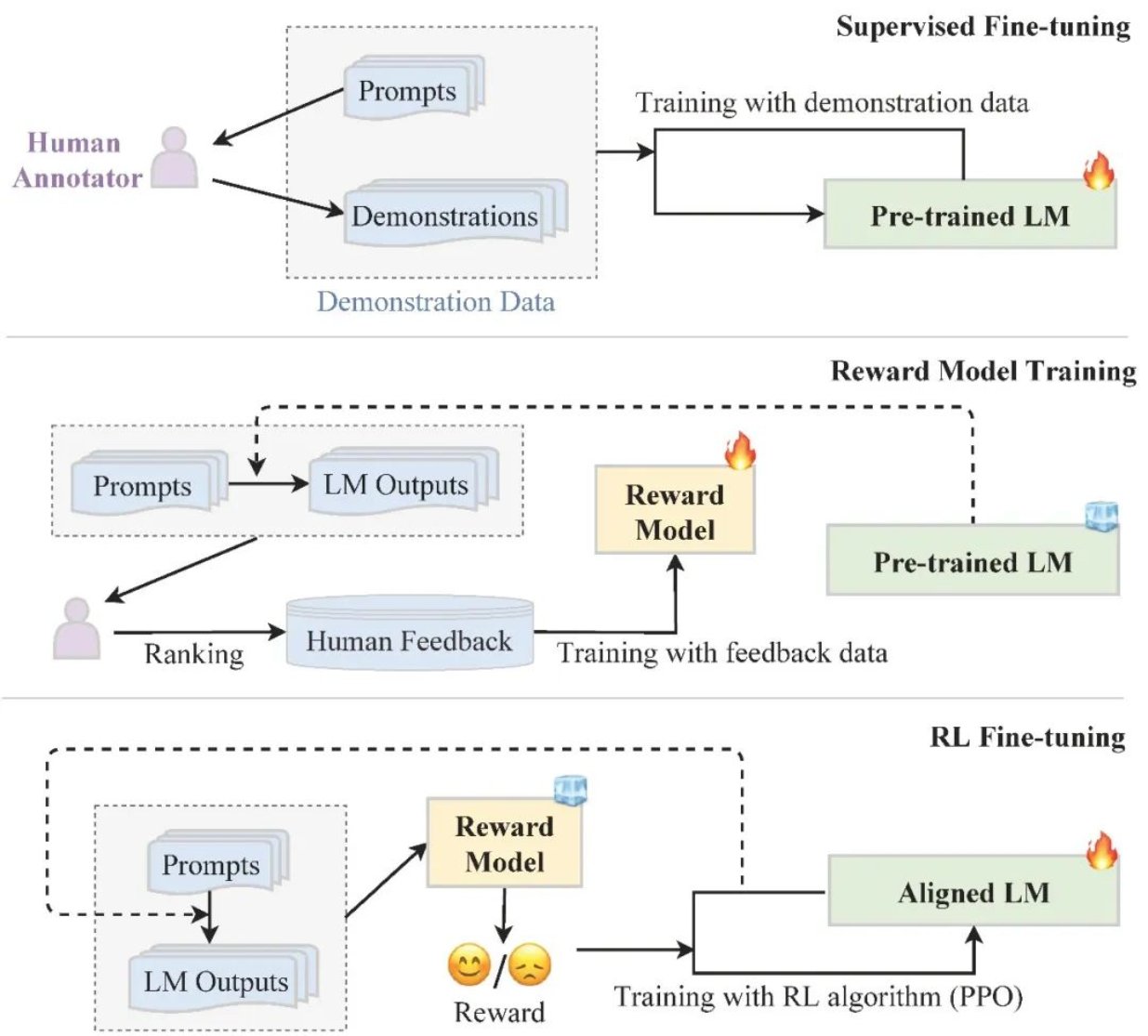
图4 基于人类反馈的强化学习工作流程
●对齐微调通过收集人类反馈数据,利用强化学习进一步微调大模型,使模型与人类对齐,更加符合人类的偏好。我们首先讨论了三种常见的对齐标准:有用性、诚实性和无害性,接着展示了三种人类反馈收集方式,最后介绍了基于人类反馈的强化学习流程(图4)。
五、大语言模型使用技术
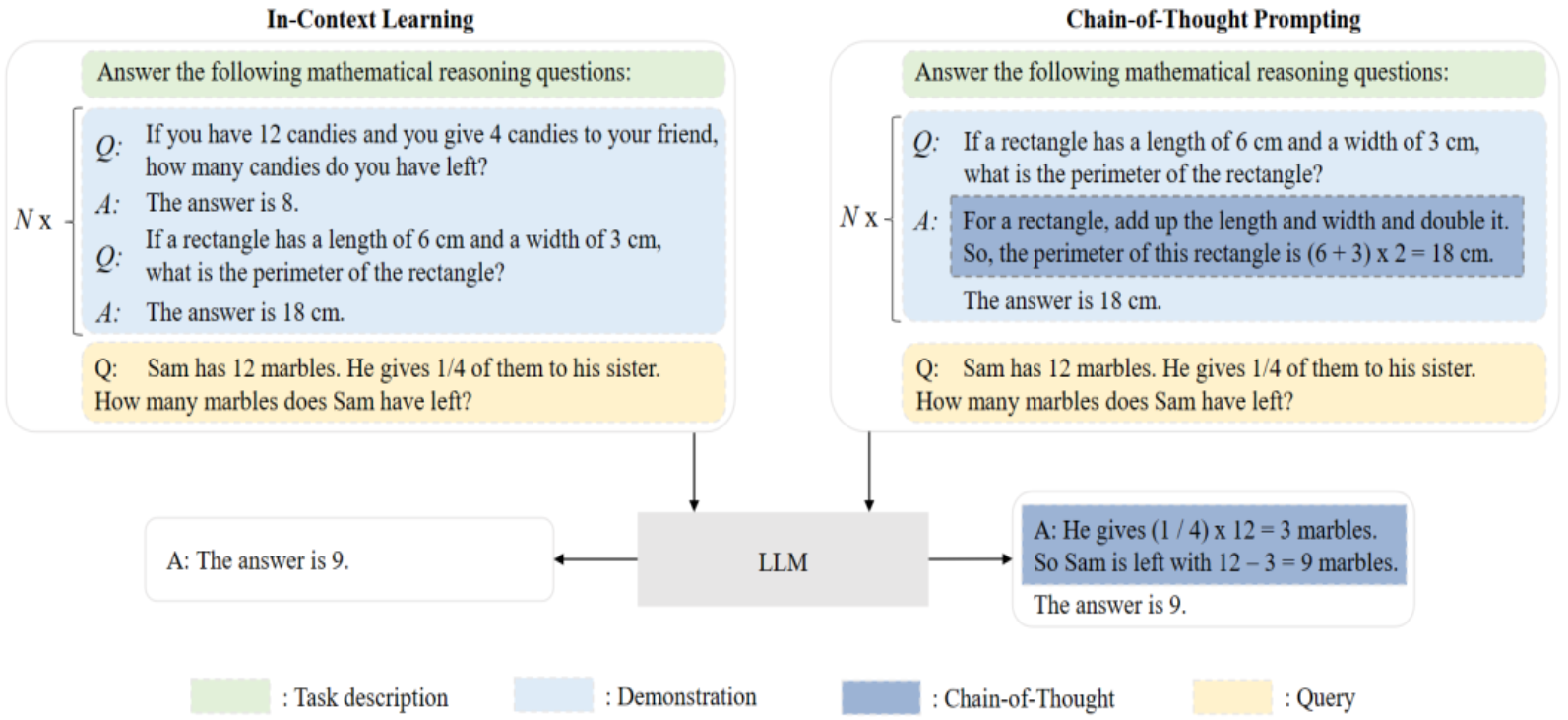
图5 两种使用技术上下文学习(ICL)和思维链提示(CoT)的对比
本章介绍了大模型完成训练之后的使用方法。其中的代表性技术是上下文学习,它以自然语言文本的形式给大模型提供任务描述和/或任务示例。我们重点总结了如何设计有效的任务示例来增强大模型通过上下文学习完成下游任务的效果,包括示例的选择、格式以及顺序。我们还从预训练和推理两个阶段讨论了大模型上下文学习能力的来源。
此外,思维链提示也受到广泛关注,它的做法是在提示中添加中间推理步骤来增强大模型在推理任务上的性能。根据提示中是否存在样例,思维链提示的使用场景可以分为少样本和零样本两种情况。我们还讨论了思维链提示的适用场景以及大模型思维链推理能力的来源
六、大语言模型能力评估
为了评估大语言模型的有效性和优越性,研究者在大量任务和评测基准上进行了评测与分析。我们从三个角度总结梳理了大语言模型的相关能力评估。
对于大模型的基础评测,我们主要关注了三类任务,包括语言生成任务、知识利用任务和复杂推理任务。总体来看,大语言模型在各类基础任务中取得了令人瞩目的效果。但与此同时,大语言模型在一些方面也存在亟待解决的问题,包括可控性、幻觉、知识实时性、一致性等等。
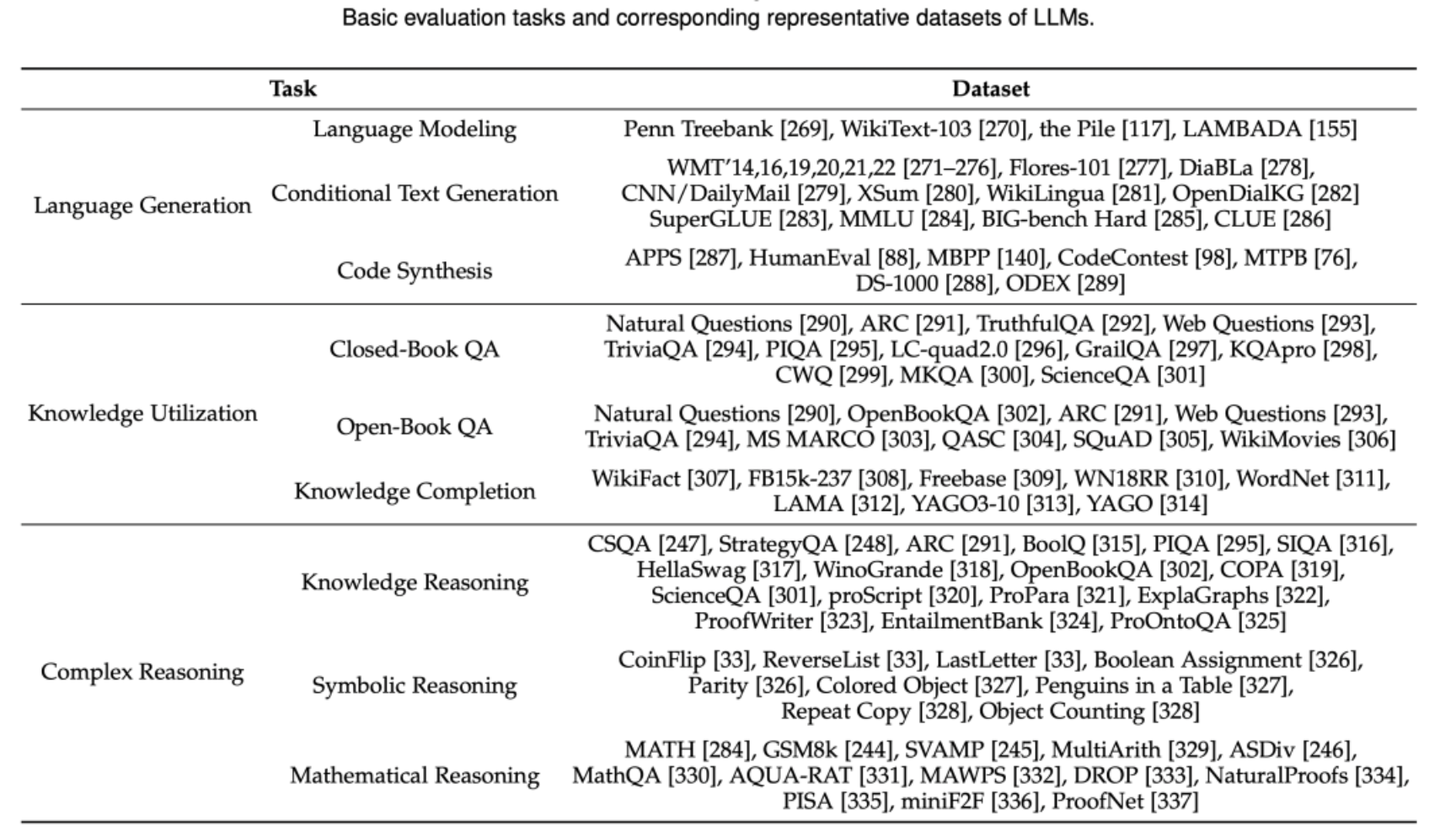
除了上述基础任务外,大模型还表现出了很多高级能力。我们着重讨论了人类对齐、外界环境交互、工具操作三大类高级能力及其对应的评估方法。这三种能力极大地丰富了语言模型的应用场景,使得语言模型能做出符合人类价值观和偏好的行为,对现实世界产生作用,以及利用工具扩展能力边界。
接下来,我们介绍了面向大语言模型的现有综合评测基准以及相关实证分析。研究者提出了许多综合评测基准,用于全面的评测和比较大语言模型。同时,另一大类工作着重于对大语言模型通用能力以及专业领域应用能力的分析。
七、总结
该综述文章系统回顾了大语言模型的最新进展,介绍了重要概念与相关技术,最后总结了大语言模型的若干挑战与未来研究方向:
(1)大模型相关的理论和本质;
(2)更优的模型架构;
(3)更有效的训练方法;
(4)更高效的使用策略;
(5)安全性与一致性;
(6)应用与生态。
注:这篇综述是项目小组在一次内部讨论会之后开始撰写的,初衷是为团队成员提供高度可读的大模型最新进展报告。第一版草稿于2023年3月13日完成,之后我们进行了大量的修改以尽量保证这篇综述的客观性和全面性。尽管我们付出了很多努力,由于自身能力所限,这篇综述仍然可能包含不严谨的表达和讨论,也可能遗漏重要的参考文献,希望各位读者能够给予更多的指导意见,帮助我们不断完善这篇综述文章。
本文作者:赵鑫(教授),周昆(博士三年级),李军毅(博士三年级),唐天一(硕士二年级),王晓磊(博士二年级),侯宇蓬(硕士三年级),闵映乾(硕士二年级),张北辰(硕士一年级),张君杰(硕士一年级),董梓灿(本科四年级),都一凡(博士一年级),杨晨(硕士二年级),陈昱硕(硕士二年级),陈志朋(本科四年级),蒋锦昊(博士二年级),任瑞阳(博士一年级),李依凡(本科四年级),汤昕宇(本科四年级),刘子康(博士一年级),刘沛羽(博士三年级),聂建云(加拿大蒙特利尔大学教授),文继荣(教授)
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox