学院新闻
高瓴人工智能学院师生论文被国际学术会议KDD 2025录用
日期:2025-06-11访问量:近日,中国计算机学会(CCF)推荐的A类国际学术会议KDD 2025论文接收结果公布。中国人民大学高瓴人工智能学院师生有16篇论文被录用。国际知识发现与数据挖掘大会 (ACM SIGKDD Conference on Knowledge Discovery and Data Mining,简称KDD) ,是数据挖掘和知识发现领域最具影响力的会议之一,第31届KDD将于2025年8月3日至8月7日在加拿大多伦多举行。

论文介绍
论文题目:Mixing Time Matters: Accelerating Effective Resistance Estimation via Bidirectional Method
作者:崔冠宇,王涵之,魏哲巍
通讯作者:魏哲巍
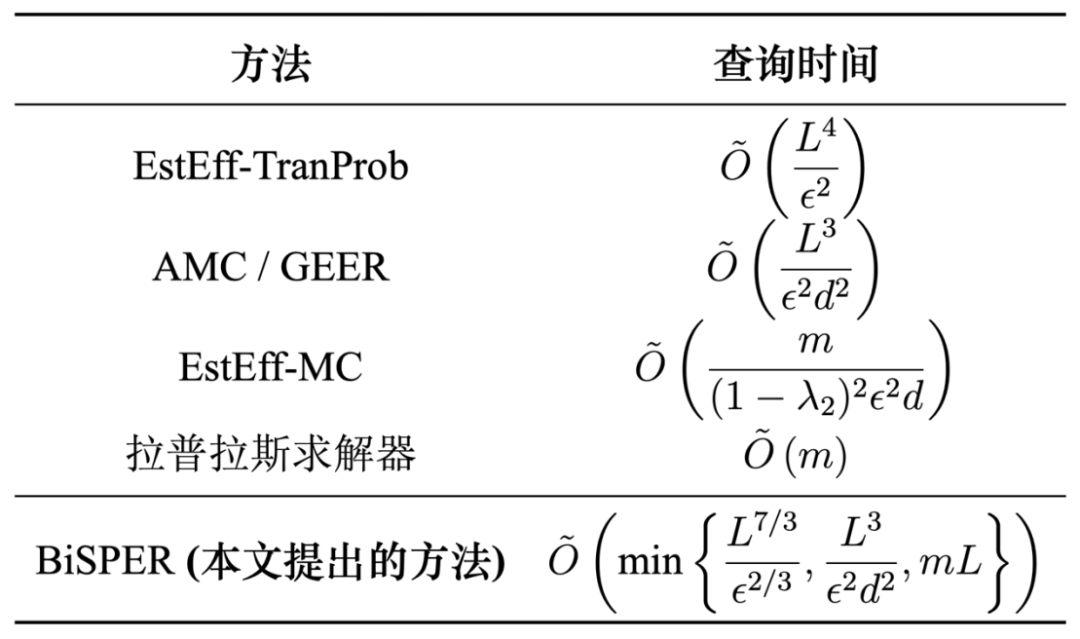
论文概述:我们研究了在无向图中高效近似计算有效电阻的问题。有效电阻是一种广泛使用的节点接近度度量方法,应用于图的谱稀疏化、多类别图聚类、网络鲁棒性分析、图机器学习等多个领域。具体来说,给定无向图 G 中的任意两个节点 s 和 t,我们的目标是在保证绝对误差 ε 很小的前提下,高效地估计节点 s 和 t 之间的有效电阻值 R(s, t)。下表列举了此前该问题的最优算法的时间复杂度与本文提出的算法的时间复杂度,其中 L 取决于图 G 上随机游走的混合时间,d = min{d(s), d(t)},而 d(s)、d(t) 分别表示节点 s 和 t 的度数,m 表示图中的边数。考虑到在现实世界网络中 L 往往非常大(例如 L > 10000),我们在 L 上的改进尤为显著,尤其适用于现实网络。我们还在真实和合成图数据集上进行了大量实验,实证展示了我们方法的优越性。实验结果表明,在保持相同绝对误差的前提下,我们的方法在运行时间上相较于基线方法实现了 10 倍至 1000 倍的加速。
论文介绍
论文题目:Large-Scale Spectral Graph Neural Networks via Laplacian Sparsification
作者:丁海鹏,魏哲巍,叶宇航
通讯作者:魏哲巍
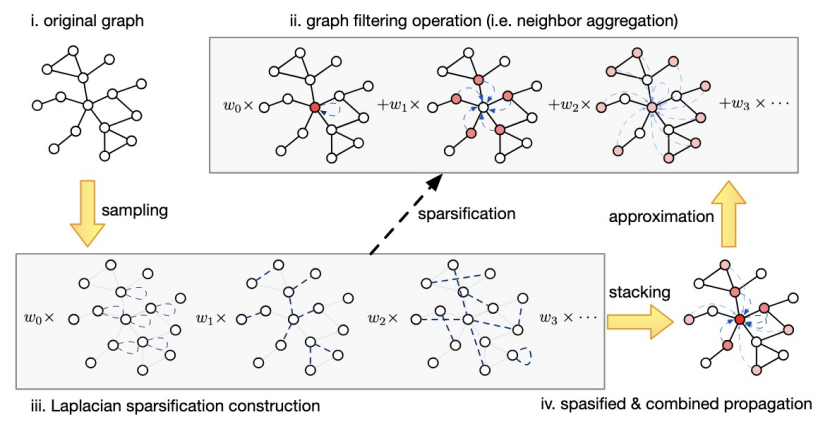
论文概述:近年来,图神经网络(GNN)在表示学习表现了非常优秀的效果,因而成为图上各类任务的重要模型。在多种GNN模型中,使用多项式滤波技术的谱域GNN在同配图和异配图任务上都表现出了可靠的效果。然而,谱域GNN的可扩展性由于其需要在多次图传播中学习多项式系数而受到限制。现有工作尝试通过删除输入节点特征后的线性层扩展谱域GNN,但这可能破坏端到端训练,可能影响性能,也可能无法完成高维度输入节点特征的训练。因此,我们提出了“使用拉普拉斯稀疏化的谱域图神经网络”。这是一种新的用于近似图传播特征的图谱稀疏化方法。我们证明了提出的模型可以生成拉普拉斯稀疏算子用于近似固定系数和可变系数的滤波器,并提供理论保证。我们的方法允许对输入节点特征使用线性层,保证了在处理纯文本输入特征时的端到端训练。我们的实验包含了多种图规模,多种不同的图性质,以证明我们提出模型的效率和效果。结果表明我们的模型可以在多种近似后模型上生成强于原模型的效果,以及在超大规模图 Ogbn-papers100M 和 MAG-scholar-C 上的可靠性。
论文介绍
论文题目:Reasoning-Enhanced Object-Centric Learning for Videos
作者:李健、任普、刘扬、孙浩
通讯作者:孙浩
论文概述:面向对象的学习(Object-centric learning)旨在将复杂的视觉场景分解为更易处理的对象级表示,从而提升机器学习系统对物理世界的理解与推理能力。近年来,基于槽位机制(slot-based)的视觉模型在对象分割和跟踪任务中表现出色,但普遍忽略了高效推理模块的作用。在现实世界中,推理与预测能力在人类感知和目标跟踪中扮演着关键角色,尤其与人类的直觉物理密切相关(例如,人类通过预测机制预先激活与任务相关的表征,从而提升感知与认知效率,使对外界信息的处理更加高效且准确)。受此启发,我们设计了一种新颖的推理模块——包含记忆缓冲机制的基于槽的时空 Transformer 模块 (STATM),以增强模型在复杂动态场景中的感知与推理能力。该模块中的记忆缓冲区用于存储上游模块提取的槽位信息;时空Transformer通过基于槽的时空注意力计算和融合进行预测。在多个基准数据集上的实验结果表明,STATM模块能够显著提升多种当前最具代表性的以对象为中心的视频学习模型的性能。此外,作为一个预测模块,STATM在下游的动态预测和视觉问答(VQA)任务中也展现出优异的泛化能力和表现。
论文介绍
论文题目:SlotPi: Physics-informed Object-centric Reasoning Models
作者:李健、万涵、林宁、詹玉梁、程泽睿志、王海宁、张毅、刘红升、王紫东、于璠、孙浩
通讯作者:孙浩
论文概述:通过视觉观察来理解和推理受物理定律支配的动态过程(类似于人类在现实世界中的能力)仍面临诸多挑战。尽管当前模仿人类行为的对象中心动态模拟方法已取得显著进展,但仍忽视了两个关键问题:1)物理知识在模型中的有效融合。人类通过观察世界获取物理常识,并灵活地将其应用于对多种动态场景的准确推理;2)模型在多样化场景中的适应能力验证。现实世界的动态过程,尤其是涉及流体与物体的场景,不仅要求模型能够建模物体间的相互作用,还需具备模拟流体流动特性的能力。为了解决上述问题,我们提出了 SlotPi——一种基于槽位机制、融合通用物理知识的对象中心推理模型。SlotPi将基于Hamiltonian的物理模块与时空预测模块相结合,用于对动态过程进行建模与预测。实验结果表明,该模型在预测任务和视觉问答(VQA)任务中表现优异,涵盖了多个标准数据集和流体场景数据集。此外,我们还构建了一个包含物体交互、流体动力学及流体-物体耦合等现象的真实世界数据集,并在此基础上进一步验证了模型的有效性。SlotPi在所有数据集上均展现出稳定的性能和强大的适应能力,为构建更高级的世界模型奠定了坚实基础。
论文介绍
论文题目:KnowTrace: Bootstrapping Iterative Retrieval-Augmented Generation with Structured Knowledge Tracing
作者:李锐,戴全宇,张泽宇,陈旭,董振华,文继荣
通讯作者:陈旭
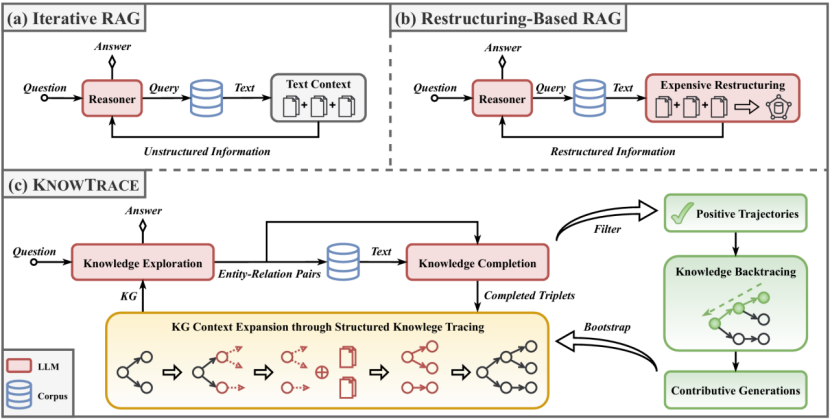
论文概述:近期在检索增强生成(RAG)领域的进展为大型语言模型(LLM)提供了迭代检索相关信息的能力,以处理复杂的多跳问题。这种方法交替进行LLM推理与信息检索,将外部信息积累到LLM的上下文。然而,随着上下文规模的增长,LLM识别关键信息片段及其潜在关联的难度不断增加,由此而产生的无效推理又会进一步加剧信息过载。针对这一挑战,本文提出了KnowTrace,一种创新的RAG框架,旨在有效缓解上下文过载,同时实现多步推理能力的自我提升。不同于简单堆积检索文本,KnowTrace采用一个独特的结构化知识追踪视角,通过自主追踪所需的知识三元组,组织与输入问题相关的特定知识图谱。这种结构化流程设计不仅为LLM提供了更加清晰的推理上下文,还自然衍生出一种知识回溯机制,能够识别对推理结果有实质贡献的生成内容,形成高质量的过程监督数据用以自我提升。大量实验表明,KnowTrace在三个标准多跳问答数据集上始终优于现有基线方法,并且其自我提升版本进一步放大了性能优势。
论文介绍
论文题目:Bridging Textual-Collaborative Gap through Semantic Codes for Sequential Recommendation
作者:刘恩泽,郑博文,赵鑫,文继荣
通讯作者:赵鑫
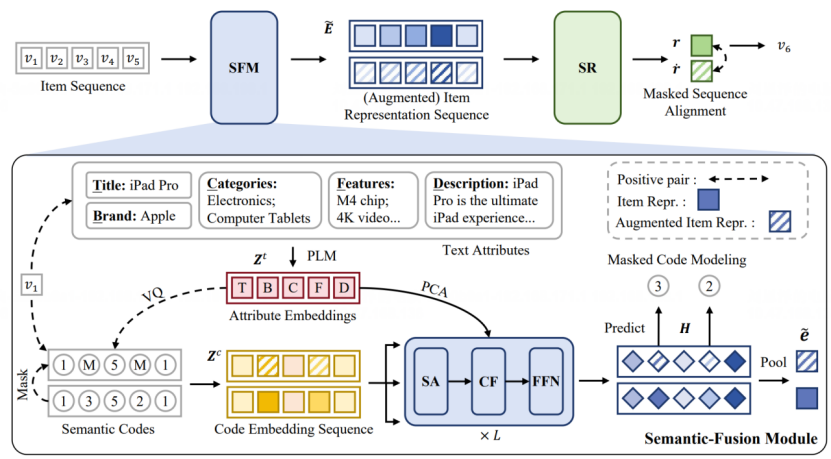
论文概述:近年来,大量研究致力于通过将丰富的辅助信息与基于ID的协同信息相结合来增强序列推荐系统。本研究特别关注如何利用与物品相关的文本元数据(如标题和品牌)。尽管现有方法通过融合文本表征与ID表征取得了显著成果,但这些方法往往难以在文本表征所嵌入的语义信息与用户行为序列模式中隐含的协同信息之间实现有效平衡。为此,我们提出了基于语义ID的文本与协同语义融合序列推荐方法(CCFRec)。该方法的核心理念是利用语义ID作为桥梁来弥合文本信息与协同信息之间的语义鸿沟。具体而言,我们通过向量量化技术从多视角文本嵌入中生成细粒度语义ID,继而利用基于交叉注意力机制的语义融合模块来灵活地从文本表征中提取并整合语义信息。为进一步加强文本语义与协同语义的融合,我们提出采用掩码技术的优化策略,该策略包含两个特定目标:掩码预测建模与掩码序列对齐。这些目标通过掩码预测任务和增强的物品表征,既能捕捉单个物品内部的语义ID关联,又能强化推荐主干网络的序列建模能力。在四个公开数据集上的大量实验表明,CCFRec具有显著优越性,其性能明显超越现有主流序列推荐模型。
论文介绍
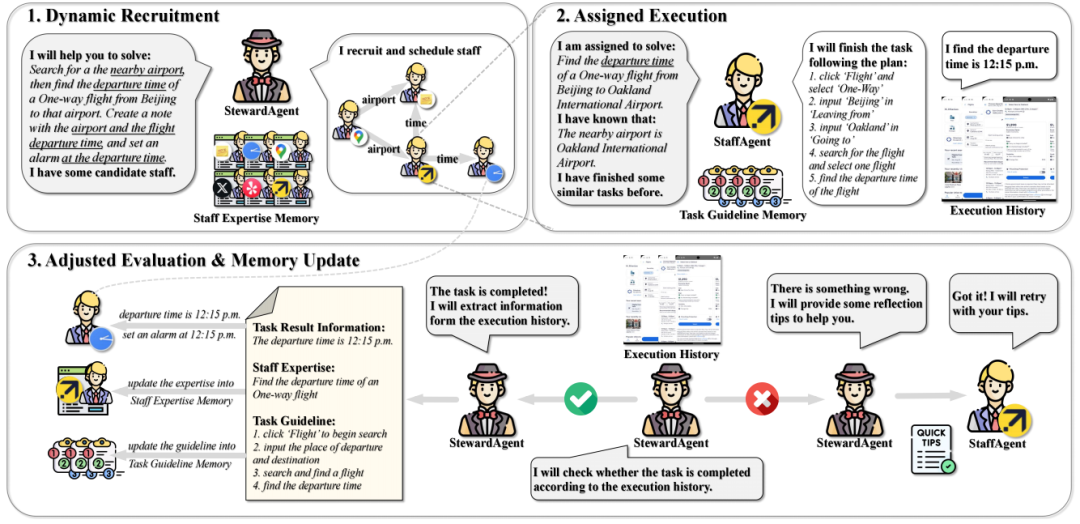
论文题目:MobileSteward: Integrating Multiple App-Oriented Agents with Self-Evolution to Automate Cross-App Instructions
作者:刘宇轩,孙宏达,刘伟,栾剑,杜博,严睿
通讯作者:严睿
论文概述:Mobile Agent能够帮助人们自动化完成手机上的日常任务,已成为一个重要的研究热点。然而,目前采用面向过程设计的Agent在处理跨应用指令时面临诸多挑战,包括:(1)任务关系复杂;(2)应用环境多样化;(3)多步骤执行中的错误传播和信息丢失。受面向对象程序设计的启发,我们提出了一个名为 MobileSteward 的自进化多智能体框架,该框架整合了多个面向应用的 StaffAgents,由一个中心化的 StewardAgent 协调。 MobileSteward 中设包含三个模块:(1)动态招募(Dynamic Recruitment)通过信息流引导生成调度图,关联不同应用之间的任务;(2)分配执行(Assigned Execution)将任务分配给面向应用的 StaffAgents,每个 StaffAgent 都配备特定应用的专业知识,以应对应用之间的多样性;(3)调整评估(Adjusted Evaluation)进行评估,提供反思建议或传递关键信息,从而缓解多步骤执行中的错误传播和信息丢失。为了持续提升 MobileSteward 的性能,我们开发了一种基于记忆的自进化机制,该机制总结成功执行的经验,以优化 MobileSteward 的性能。我们在真实环境中建立了第一个英文跨应用基准测试(CAPBench),用于评估Mobile Agent解决复杂跨应用指令的能力。实验结果表明,MobileSteward 在单智能体和多智能体框架中均表现出色,凸显了其在处理复杂多样的用户指令方面的优越性。
论文介绍
论文题目:Conservation-informed Graph Learning for Spatiotemporal Dynamics Prediction
作者:米源,任普,许洪腾,刘红升,王紫东,郭毅可,文继荣,孙浩,刘扬
通讯作者:孙浩,刘扬
论文概述:数据驱动方法在理解和预测时空动力学方面展现出巨大潜力,为系统的设计与控制提供了更优方案。然而,深度学习模型往往存在可解释性不足、难以遵循内在物理规律、以及跨域适应能力有限等问题。尽管研究者已提出基于几何的方法(如图神经网络GNN)来应对这些挑战,这类方法仍需从海量数据中挖掘隐含的物理定律,且过度依赖丰富的标注数据。本文提出守恒嵌入图神经网络(CiGNN), 一种端到端可解释学习框架,基于有限训练数据实现时空动力学建模。该网络通过对称性设计使其符合广义守恒定律,其中守恒与非守恒信息在潜在时间推进策略增强的多尺度空间中传递。基于合成与真实世界数据集的多组时空系统实验验证了模型有效性,其性能显著优于基线模型。结果表明,CiGNN不仅具有出色的预测精度和泛化能力,更能直接应用于复杂几何空间域中各类时空动力学的预测学习。
论文介绍
论文题目:TIDFormer: Exploiting Temporal and Interactive Dynamics Makes A Great Dynamic Graph Transformer
作者:彭杰,魏哲巍,叶宇航
通讯作者:魏哲巍
论文概述:动态图广泛存在于社交网络、推荐系统等真实场景中,其核心挑战在于如何设计算法模型来捕捉图中节点、边随时间演化的复杂序列关系。近年来,基于Transformer的动态图神经网络因其强大的序列建模能力受到关注,但现有方法普遍存在两大问题:一是动态图上使用的自注意力机制定义缺乏可解释性,难以准确建模节点间的交互动态;二是现有方法对时间动态和交互动态的编码效率低下,依赖复杂的模块设计或采样策略,导致计算成本高且性能受限。因此,如何设计一个高效且可解释的动态图Transformer框架,成为当前研究的迫切需求。本论文提出TIDFormer模型,针对动态图学习中的交互建模与时间编码问题,提出了交互级可解释自注意力机制,并设计了一套高效的混合粒度时间编码与双向交互编码模块,显著提升了基于Transformer的动态图神经网络的建模能力与计算效率。实验结果表明TIDFormer在真实动态图数据集上取得了优于基线模型的性能,推动了动态图神经网络在时序场景中的高效建模与可解释性发展。
论文介绍
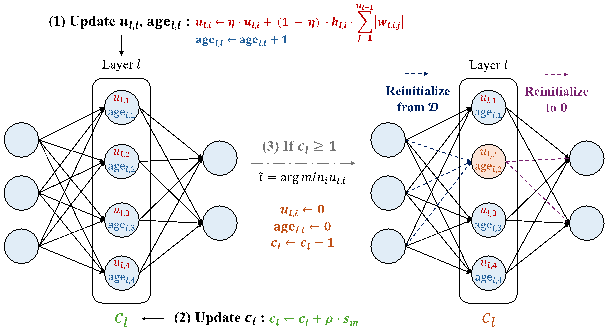
论文题目:Revisiting Clustering of Neural Bandits: Selective Reinitialization for Mitigating Loss of Plasticity(Research Track)
作者:苏智渊,戴孙浩,张骁
通讯作者:张骁
论文概述:无价值函数的强化学习设定(Bandit Setting)近期备受关注,然而将经典的浅层Bandit方法直接扩展到深度神经网络版本时常面临着性能下降的挑战。本文关注CB(Clustering of Bandits)类方法,其基于相似性将赌博机分组,利用各组的上下文信息显著提升了序列决策的性能,在个性化流媒体推荐等应用中展现了良好的效果和适应性。然而本文发现:当已有CB方法扩展到其神经网络版本CNB(Clustering of Neural Bandits)时,面临着“可塑性丧失”的问题,即:神经网络参数随时间变得僵化,适应性降低,限制了其在动态环境中的适应能力。为解决这一挑战,本文提出了一种新的Bandit强化学习框架SeRe(Selective Reinitialization),利用贡献效用度量自适应地识别、选择性地重置低效用的神经单元,从而有效缓解了深度Bandit方法的可塑性丧失问题。本文在6个实际推荐数据集上验证了SeRe能够有效地缓解CNB方法的可塑性丧失问题,增强其在动态环境中的适应性和鲁棒性;同时从理论上证明,SeRe能够使CNB在分段平稳环境中实现亚线性累积遗憾,确保算法的收敛性。
论文介绍
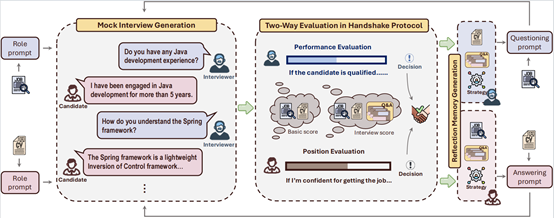
论文题目:MockLLM: A Multi-Agent Behavior Collaboration Framework for Online Job Seeking and Recruiting
作者:孙宏达,林宏展,闫海钰,宋洋,高欣,严睿
通讯作者:严睿
论文概述:在线招聘平台重塑了求职和招聘流程,使得改进人岗匹配的应用需求正在日益增长。传统方法通常依赖于分析简历和职位描述中的文本数据来学习它们之间的匹配函数,这限制了对有效招聘至关重要的交互动态。大型语言模型 (LLM) 的最新进展体现出其在模拟对话角色方面的巨大潜力,使其成为自适应和情境感知对话应用的理想选择。本文提出了 MockLLM,一个用于生成和评估模拟面试的全新框架。该系统分为两个主要部分:模拟面试生成和基于握手协议的双边评估。通过模拟面试官和候选人的角色,该系统实现了一致、协作的多智能体互动,从而促进了实时、双边的人岗匹配。为了持续提高匹配准确率,MockLLM 进一步融合了反思记忆生成和动态策略修改功能,可以根据以往的匹配经验来优化面试官和候选人的行为。我们基于在线招聘平台BOSS直聘的真实数据对MockLLM进行评估,实验结果表明,MockLLM在人岗匹配准确率、可扩展性以及不同部门的适应性方面均优于现有模型。这些结果展现了我们的MockLLM在候选人评估和在线招聘领域的巨大潜力。
论文介绍
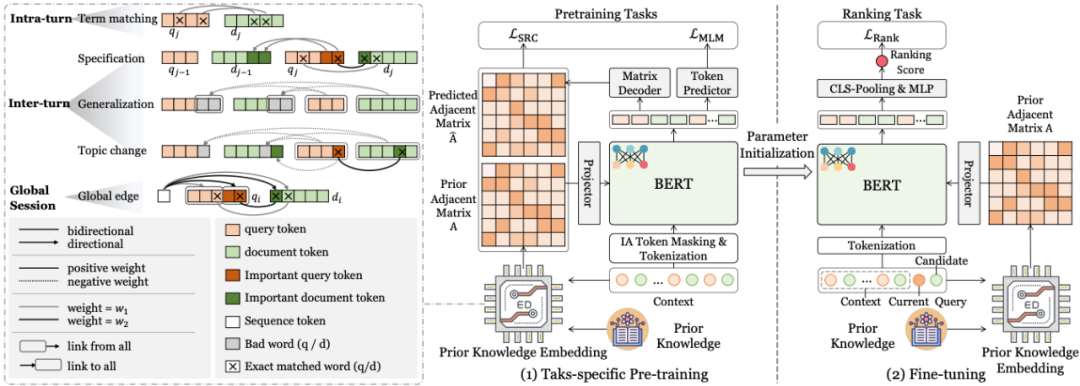
论文题目:Embedding Prior Task-specific Knowledge into Language Models for Context-aware Document Ranking
作者:王淑婷,朱余韬,窦志成
通讯作者:窦志成
论文概述:利用当前会话中用户的上下文行为已被证明对文档排序任务有利。最近,由于预训练语言模型(PLM)在语言建模方面的卓越能力,上下文感知文档排序任务从这些模型中获益匪浅。大多数基于 PLM 的上下文感知文档排序模型通过在历史搜索日志上微调 PLM 来隐式学习任务特定知识。然而,由于搜索日志数据存在噪声且包含各种用户意图和搜索模式,这种黑箱方式可能会阻碍模型充分掌握有效的上下文感知搜索知识。为了解决这个问题,我们提出了 LOCK,这是一种基于 PLM 的上下文感知文档排序模型,它通过将任务特定的先验知识显式嵌入到 PLM 中来引导模型优化。从局部到全局,我们确定了三种任务特定的知识类型,包括会话内信号、会话间信号和全局会话信号。LOCK 将这种先验知识转化为先验注意力偏差,以影响 PLM 的微调。这种操作可以通过任务特定的先验知识引导排序模型,从而提高模型的收敛性和排序能力。此外,我们引入了一个特定任务的预训练阶段,该阶段涉及掩码语言建模和先前注意力矩阵的软重构,这有助于预训练语言模型适应我们的任务。大量的实验验证了我们方法的有效性和收敛性。
论文介绍
论文题目:Learnable-Differentiable Finite Volume Solver for Accelerated Simulation of Flows
作者:闫梦涛、王琦、王海宁、程泽睿志、张翼、刘红升、王紫东、于璠、祁琦、孙浩
通讯作者:孙浩
论文概述:流体流动的模拟对于刻画气象学、空气动力学和生物医学等物理现象至关重要。传统的数值求解器通常需要在时空上使用高分辨率的网格,以满足稳定性、一致性和收敛性的要求,这导致了巨大的计算开销。尽管近年来的机器学习方法在效率方面表现更优,但它们往往存在可解释性差、泛化能力弱以及对数据依赖性强等问题。为此,我们提出了一种可学习且可微分的有限体积求解器——LDSolver,用于在时空粗网格上高效且准确地模拟流体流动。LDSolver 包含两个核心模块:(1)一个可微的有限体积求解器;(2)一个可学习模块,用于在粗网格上对通量(如导数和插值)进行等效近似,并进行时间误差修正。即便在训练数据非常有限的情况下(例如仅包含少量轨迹),LDSolver 也能显著加速仿真过程,并保持高度准确性与优越的泛化能力。在不同的流动系统(如 Burgers 方程、耗散流、强迫流和剪切流)上的实验结果表明,LDSolver 实现了当前最优性能,显著优于现有的基线模型。
论文介绍
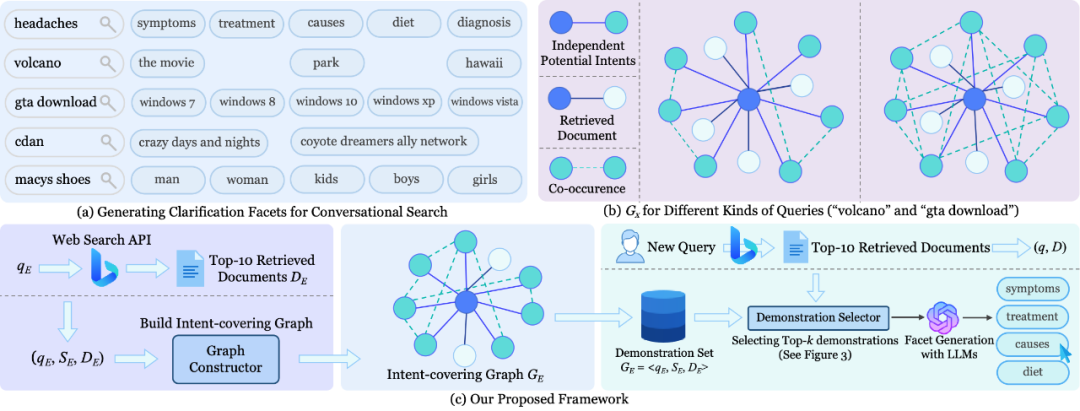
论文题目:Retrieving Intent-covering Demonstrations for Clarification Generation in Conversational Search Systems
作者:赵梓良,渠常乐,窦志成,陈浩楠,金佳杰
通讯作者:窦志成
论文概述:搜索澄清是开放域对话式网络搜索中的关键用户界面,为模糊或多维度查询生成高质量分面能有效引导消歧并提升用户交互体验。近期,基于大语言模型(LLMs)的上下文学习通过利用静态或基于相似性的示例作为提示,已成为分面生成的重要方法。然而现有方法主要依赖查询相似性,未能考虑查询意图的多维特性,导致大语言模型可能生成与用户需求不符的错误或次优分面。为应对这一挑战,我们提出"意图覆盖"框架,通过选择能全面覆盖查询潜在多样意图的示例来改进澄清分面生成。具体而言:首先训练带束搜索的生成模型预测潜在意图,并构建意图-文档图以捕获语义关系;随后设计启发式贪心算法,通过最大化意图覆盖度优化示例选择;此外鉴于示例顺序对生成质量的重要影响,开发重排序模型优化示例序列以提升上下文对齐。实验表明,本方法在多种词汇和语义评估指标上均优于强基线模型。我们进一步深入分析了示例数量、顺序及上下文相关性对生成性能的影响机制。该研究为对话式搜索系统的澄清界面设计提供了新的技术路径和理论洞见。
论文介绍
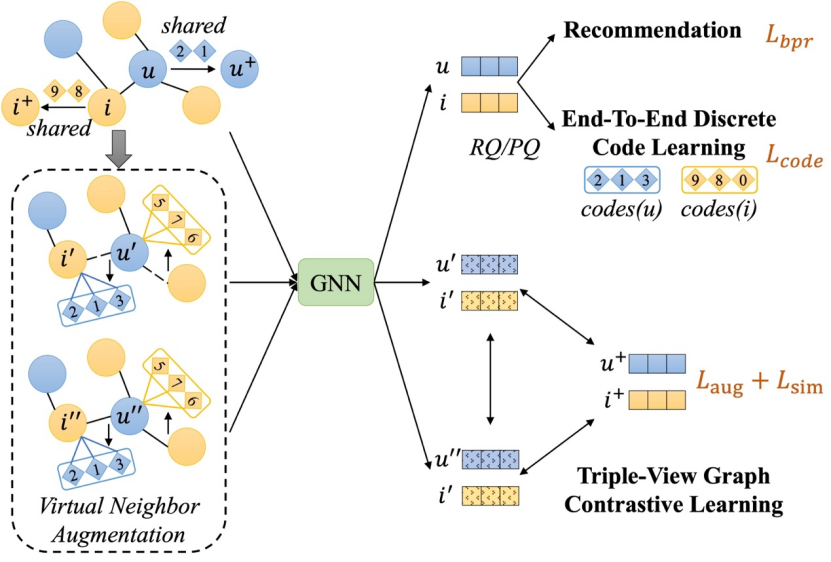
论文题目:Enhancing Graph Contrastive Learning with Reliable and Informative Augmentation for Recommendation
作者:郑博文、张君杰、卢泓宇、崔成鹏、陈明、赵鑫、文继荣
通讯作者:赵鑫
论文概述:图神经网络(Graph Neural Networks, GNN)因其能够捕捉高阶用户与物品之间的关系,在协同过滤(Collaborative Filtering, CF)中取得了显著进展。为了缓解数据稀疏性并提升表示学习效果,近年来研究者将对比学习(Contrastive Learning, CL)引入到图神经网络中。然而,现有方法在生成对比视图时往往通过对结构或表示的扰动,可能会破坏潜在的协同信息,从而降低正样本对齐的有效性。为了解决这一问题,本文提出了一种全新的图对比学习方法CoGCL。其核心思想是通过离散code增强对比视图中的协同信息。具体地,本文设计了一种端到端的多级向量量化器,用于将用户和物品的表示编码为包含协同语义的离散code。基于这些离散code,本文提出虚拟邻居增强和语义相关采样两种策略,分别在结构邻居和语义相似性两个层面构建更加可靠和信息丰富的对比视图。最终,本文将上述增强方法融合为一个三视图的图对比学习框架,有效提升了推荐性能。在四个公开数据集上的实验结果验证了CoGCL的优越性。
论文介绍
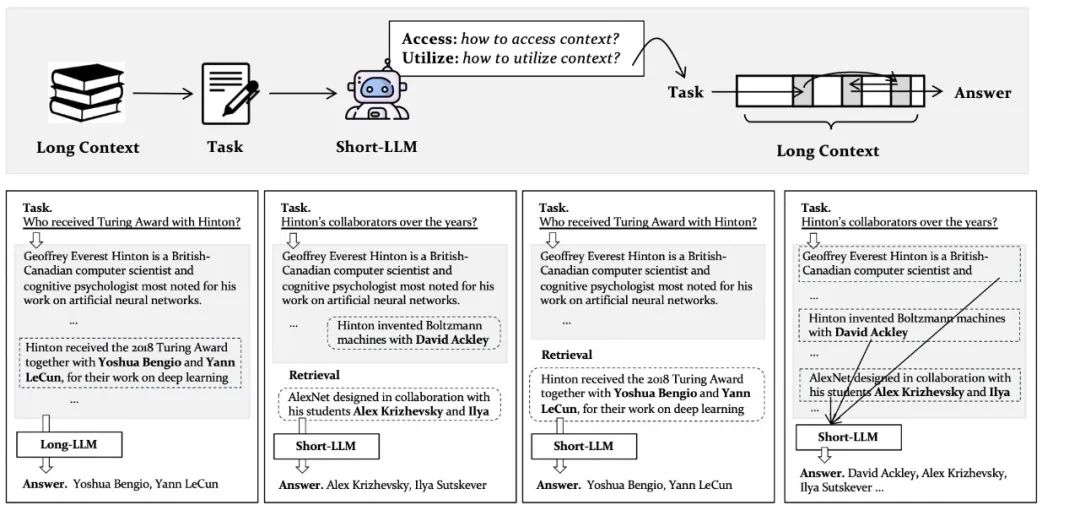
论文题目:Tackling the Length Barrier: Dynamic Context Browsing for Knowledge-Intensive Task
作者:钱泓锦,刘政,张配天,毛科龙,周雨佳,陈旭,窦志成
论文概述:知识密集型任务通常需要在长文本上下文中进行复杂推理和语境理解。然而,尽管近年来取得了进展,长上下文大语言模型的训练与部署仍然是一项挑战性问题。在本研究中,我们提出,短上下文大语言模型在处理具有长上下文的知识密集型任务方面具有巨大潜力——即这些任务可以通过仅依赖输入长上下文中的“理想短上下文片段”来完成。基于这一观点,我们提出了一个名为 DCISO的框架,使得短-LLM能够通过动态浏览上下文来处理知识密集型的长上下文任务。在该框架中,短-LLM会自行推理并做出两个关键决策:(1)如何访问输入上下文中最相关的部分,(2)如何高效利用所访问的上下文内容。通过根据具体任务自适应地访问与使用上下文,DCISO 能够作为一个通用框架,用于解决多样化的知识密集型长上下文问题。我们在多个流行的长上下文基准任务上进行了全面评估,实验表明 DCISO 在各类任务上都取得了显著的性能提升。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox