科研
人大发布矩阵化金融领域大模型检索增强评估基准
日期:2025-01-02访问量:近年来,大语言模型(LLMs)在很多领域都得到落地应用,而检索增强生成(RAG)技术能辅助提升大模型的知识能力。在垂直领域(像金融领域),大语言模型通常缺乏特定领域的专业知识,RAG 模型就能结合外部领域语料库和大语言模型内部知识的优势,提升生成式人工智能系统的整体质量。但目前自动构建高质量全方位的基准来评估 RAG 模型在垂直领域的性能还是个未解决的问题。在金融领域对 RAG 或 LLM 系统的评估也存在不足,比如有些只评估最终回答的质量,忽略了检索性能。所以作者团队提出了一个自动且全方位的基准 OmniEval,来评估 RAG 系统在金融领域的表现。

论文标题:OmniEval: An Omnidirectional and Automatic RAG Evaluation Benchmark in Financial Domain
作者:王淑婷、谭杰骏、窦志成、文继荣
相关链接:arxiv论文:https://arxiv.org/abs/2412.13018
数据集的开源模型评测榜单: https://huggingface.co/spaces/RUC-NLPIR/OmniEval
开源评测模型:
https://huggingface.co/RUC-NLPIR/OmniEval-ModelEvaluator, https://huggingface.co/RUC-NLPIR/OmniEval-HallucinationEvaluator
开源金融知识库:
https://huggingface.co/datasets/RUC-NLPIR/OmniEval-KnowledgeCorpus
机器标注的问答对:
https://huggingface.co/datasets/RUC-NLPIR/OmniEval-AutoGen-Dataset
GitHub代码仓库:
https://github.com/RUC-NLPIR/OmniEval
背景:
随着人工智能技术的发展,大语言模型(LLMs)在自然语言处理领域取得了显著进展。然而,这些模型在垂直领域(如金融领域)的应用面临着挑战,因为它们通常缺乏特定领域的专业知识。为了解决这一问题,检索增强生成(RAG)技术应运而生,它能够将领域语料库与大语言模型的理解和生成能力相结合,从而提高生成式人工智能系统在垂直领域的整体质量。
在RAG技术的发展过程中,如何评估其性能成为了一个关键问题。尽管已有一些研究关注RAG基准的构建,但在垂直领域,特别是金融领域,仍然缺乏高质量、全方位且自动的评估基准。已有的评估基准存在各种局限性,如部分侧重于特定能力评估、数据生成方式单一、评估指标不够全面或忽视检索性能等。

表1:与现有金融基准的比较。对比了OmniEval基准与PIXIU、DISC - FinLLM、FinanceBench、AlphaFin、FinBen、FinTextQA等基准在评估场景、数据生成方式、评估指标、评估模型等方面的差异。
在这样的背景下,本研究旨在提出一个专门针对金融领域的自动和全方位的RAG评估基准OmniEval,以填补现有研究的空白,为RAG系统在金融领域的性能评估提供更有效的方法和工具,推动该技术在金融领域的发展和应用。
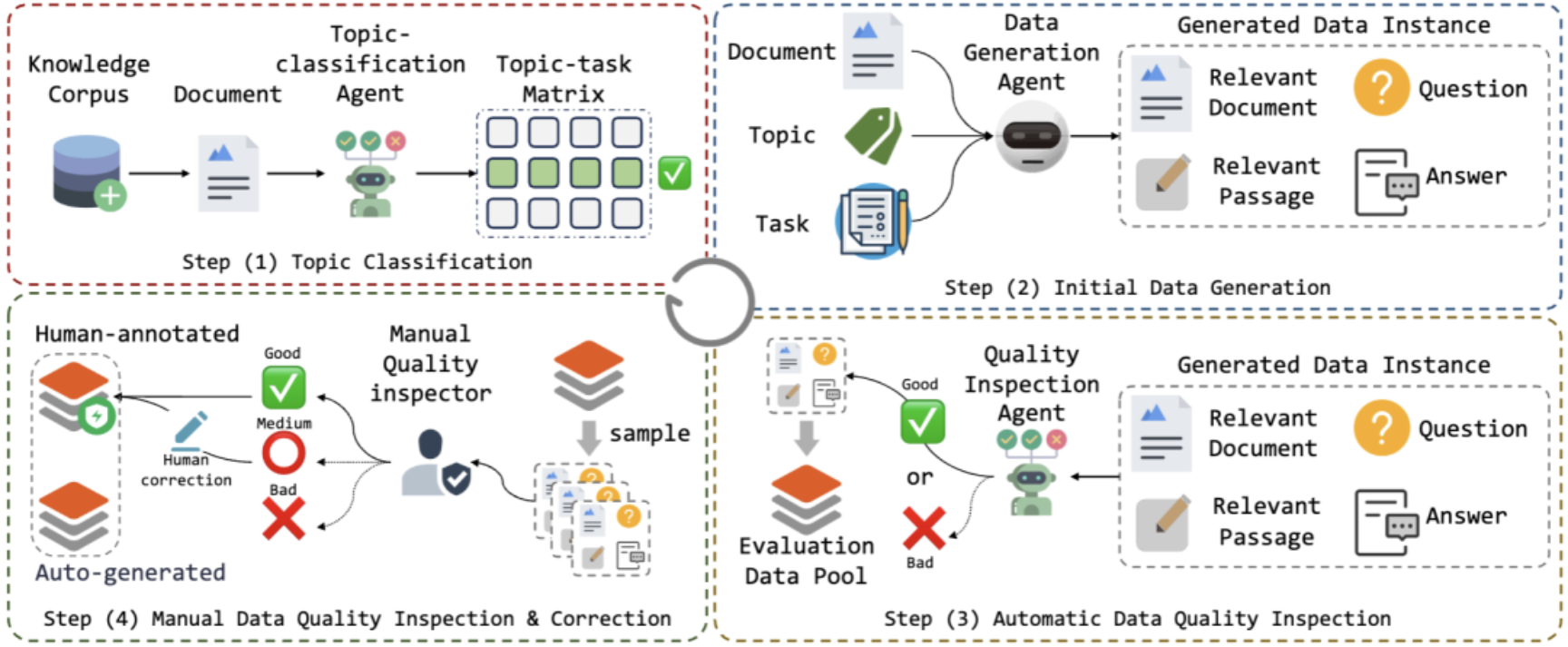
图1:OmniEval评估数据生成流程的可视化。展示了从主题分类、初始数据生成、自动数据质量检查、人工数据质量检查与修正到生成高质量评估数据集的流程。
OmniEval构建流程
1知识语料库构建
数据收集:从多个数据源收集金融相关文档,包括两个开源金融挑战赛(BS Challenge Financial,简称BSCF,包含数据库格式和PDF格式文档)、FinGLM(PDF格式)、维基百科中文金融相关网页(Wiki - Fin,JSON格式)、开源金融预训练数据集BAAI IndustryCorpus Finance(BAAI - Fin,JSON格式)以及从官方机构和银行网站抓取并通过法律审查的金融网页(JSON格式)。
数据处理:由于外部文档格式多样(如PDF、文本、SQLite等),使用LlamaIndex工具进行处理。先将SQLite数据转换为JSON格式,然后利用LlamaIndex将所有文档分割为长度为2048且重叠为256的段落,构建检索语料库。数据资源的统计信息见表2,包括数据来源、类型、文档数量、总长度和平均长度等。
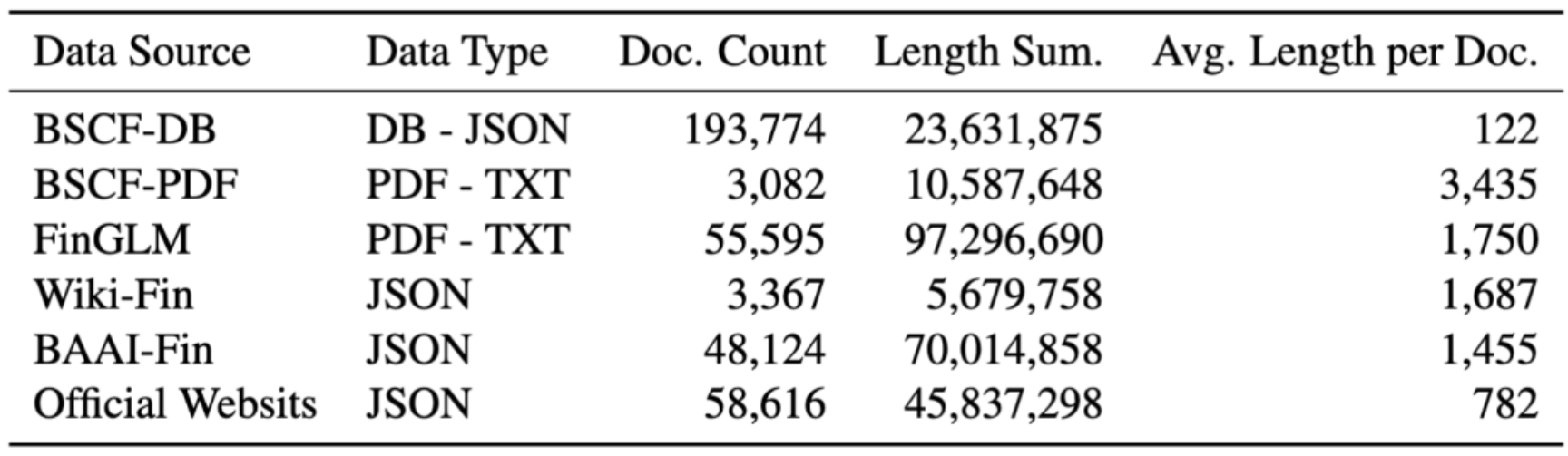
表2:不同数据源的统计信息。涵盖数据来源(如BSCF - DB、BSCF - PDF、FinGLM、Wiki - Fin、BAAI - Fin、官方网站等)、数据类型、文档数量、总长度、平均长度等信息,展示了构建知识语料库的数据基础。
2评估实例生成
RAG场景识别
1. 定义评估视角:从领域主题和RAG任务两个维度定义RAG场景。领域主题方面,如股票市场、投资银行、财产保险等不同主题可区分RAG场景;RAG任务方面,根据问题类型确定不同任务,如抽取式问答、多跳推理、对比、对话和长文本问答任务。这两个维度正交,形成RAG场景矩阵,每个元素代表特定主题 - 任务场景。
2. 构建主题系统:通过提示GPT - 4构建主题系统,并根据主题频率进行修剪,最终确定的主题树包含16个金融主题(见图2)。同时,设计一个由GPT - 4实现的主题分类代理,接收知识语料库中的采样文档,确定其相关主题,定位场景矩阵中的“行”。
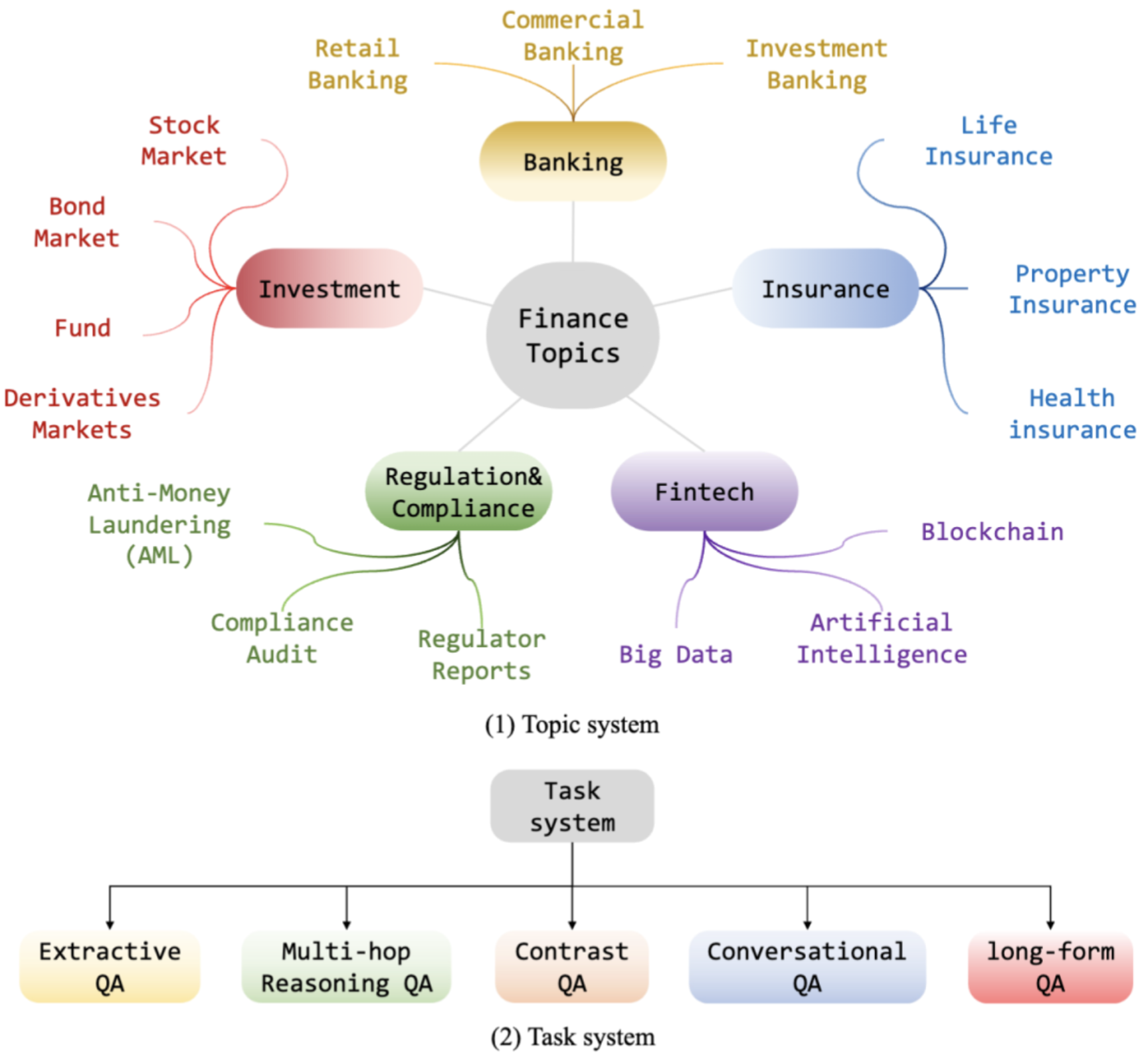
图2:用于构建基准的主题树。包含商业银行业务、股票市场、人寿保险、银行业、债券、财产保险、投资基金、金融衍生品市场、健康保险、监管与合规、反洗钱(AML)、金融科技、区块链、大数据人工智能、合规、监管报告等16个金融主题。
数据生成:确定文档及其相关主题后,遍历预定义的RAG任务,为每个属于场景矩阵元素的RAG场景生成数据实例。对于给定的文档、主题和任务描述,构建数据生成代理生成满足任务要求且与主题相关的问答对,将输入文档作为问答对的相关文档。考虑到文档可能包含无关信息,提示数据生成代理识别文档中与问答对最相关的段落,提高相关段落标记的准确性。一个数据实例包含用户问题、答案、相关文档和相关段落。
数据质量检查:引入质量检查代理过滤低质量生成的数据实例。该代理以生成的数据实例为输入,预测实例是否包含有意义信息并满足目标任务描述,仅保留被判定为高质量的实例。
人工质量检查与修正:除了基于代理的检查,还引入人工注释者进行数据质量检查和修正。从每个场景矩阵元素的所有生成实例中采样一个子集,注释者检查生成的问题是否满足任务要求、与主题是否相关、语义是否完整、答案是否正确完整以及提取的相关段落是否准确完整精确等,注释采用1 - 5的五分量表。统计结果显示自动生成案例的接受率为87.47%(见图3)。根据检查和修正步骤,构建了自动生成和人工注释的两个评估数据集,并将自动生成的数据集进一步划分为训练集和测试集,其统计信息分别见图4、图5和图6。
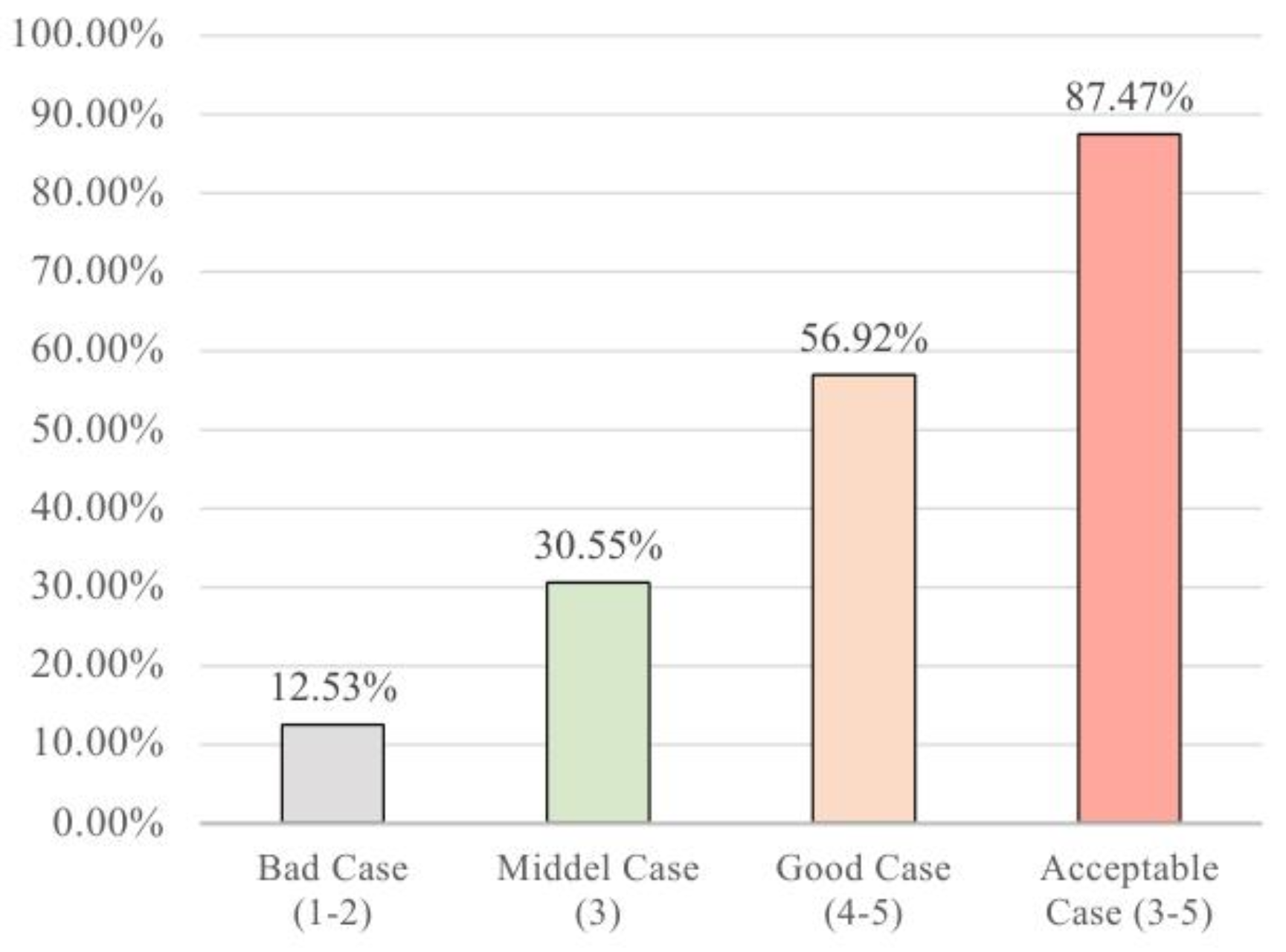
图3:人工检查的统计信息。显示自动生成案例的接受率为87.47%,其中“Good Case”(4 - 5分)占比最高,“Bad Case”(1 - 2分)占比最低,说明自动生成数据的质量总体较好。
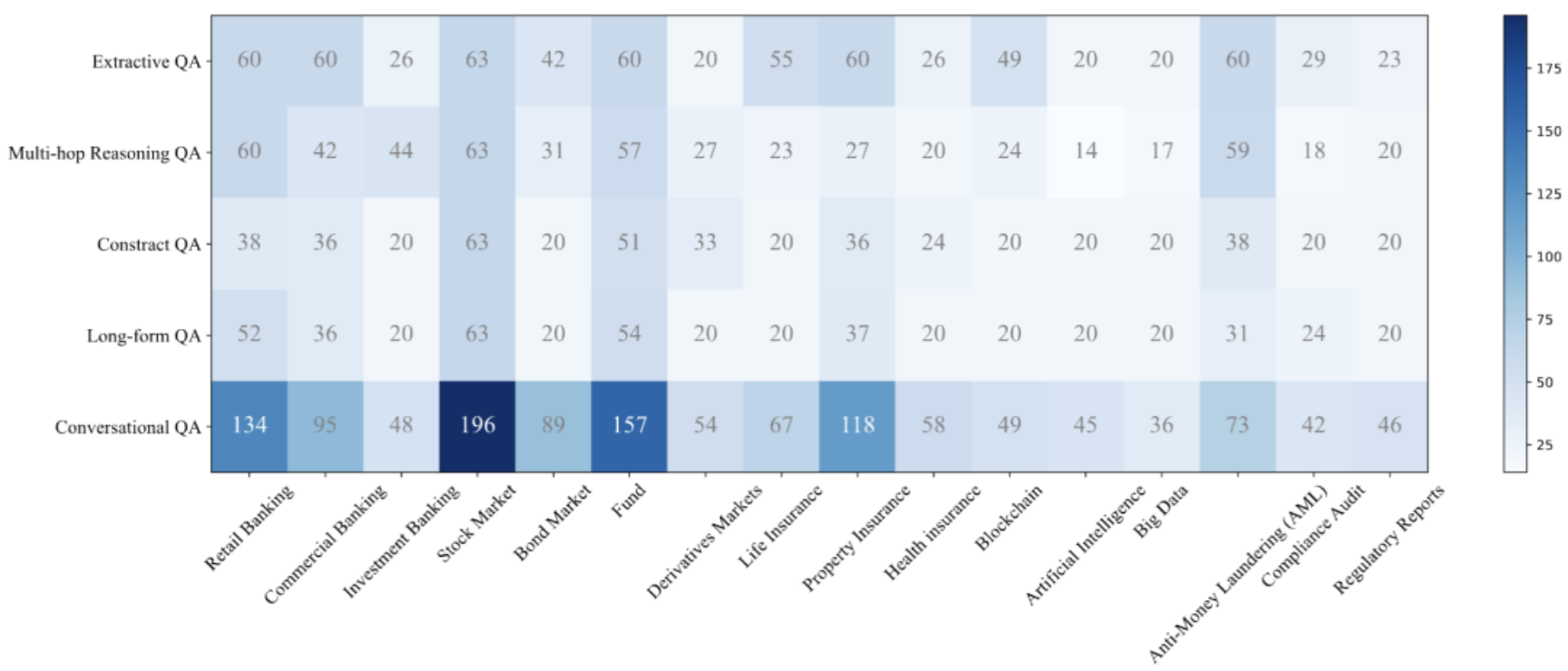
图4:自动生成训练集的统计信息。按不同话题-任务(抽取式问答、多跳推理问答、对比式问答、长文本问答、对话式问答)子集展示了数据量的分布情况,可直观了解训练集在各子任务中的数据分布差异。

图5:自动生成测试集的统计信息。与图4类似,呈现了自动生成测试集在不同子任务下的数据量分布,有助于分析测试集的特征。
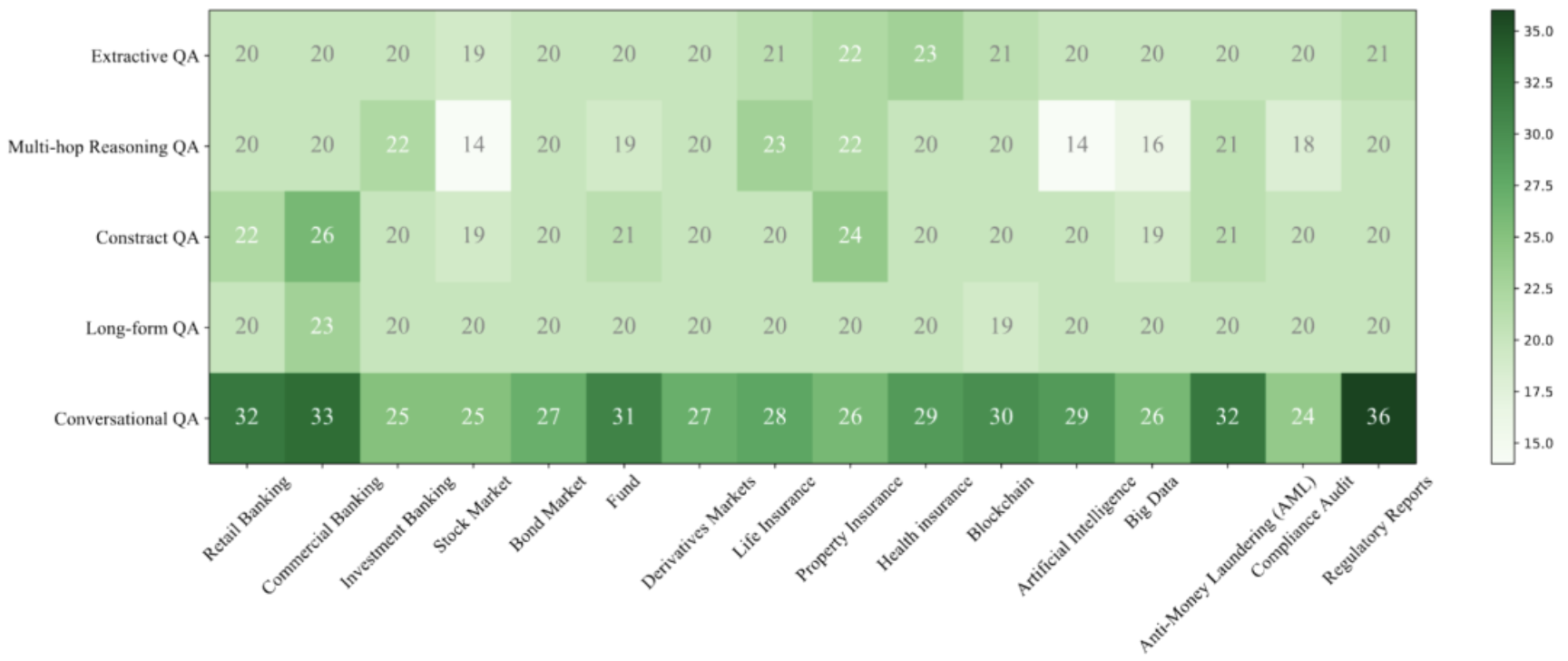
图6:人工注释测试集的统计信息。展示了各话题-任务子集的样本数量分布,反映人工注释测试集的分布特点。
RAG自动化评测
鉴于自动生成和人工注释的评估数据集,我们使用两种类型的指标,即基于规则的指标和基于模型的指标,来全面且准确地评估各种 RAG 基线。
1评价指标设计
基于规则的指标
1. ROUGE - L:用于对实验中的RAG系统进行基本评估,衡量生成文本与参考文本之间的重叠程度。
2. MAP(平均准确率)和MRR(平均倒数排名):这两个指标用于评估RAG系统中检索器的性能,从而实现对整个RAG流程的全面评估。MAP衡量检索结果的准确性,MRR则考虑了正确答案在检索结果中的排名位置。
基于模型的指标
1. 准确性(ACC):由于大语言模型生成的响应可能在内容正确但词汇匹配不佳,因此该指标通过测量大语言模型响应与正确答案之间的语义一致性来评估RAG系统,是一个三分类指标(1表示差,2表示平均,3表示好)。
2. 完整性(COM):针对长文本问答场景,用户期望全面的答案。该指标衡量响应是否满足真实答案的所有方面,是一个四分类指标(1表示未涉及任何方面,2表示部分满足,3表示全面覆盖, - 1表示某些短答案场景无需测量完整性)。
3. 幻觉(HAL):关注大语言模型生成的响应是否包含幻觉内容。如果答案完全正确或虽错误但源于检索文档,则幻觉值为0;若答案错误且内容不来自检索文档,则幻觉值为1,越低越好。
4. 利用率(UTL):主要评估大语言模型是否能有效利用检索到的文档,即答案是否可从检索文档中追溯,是一个类似ACC的三分类指标。
5. 数值准确性(NAC):用于金融计算相关场景,答案通常为数字形式,是一个二分类指标(1表示正确,0表示错误)。
6. 所有指标均归一化到[0,1]范围以确保尺度一致。
2评估器训练与构建
为确保基于大语言模型的评估器的可靠性,对RAG生成的响应的一个子集进行了人工注释,以获取用于训练稳定评估器的标注数据集。具体操作如下:
数据采样与标注:随机抽取127个案例,针对上述五个指标进行标注,共产生635个示例。将这些示例按5:1:4的比例划分为训练集、验证集和测试集。
模型训练与选择:对Qwen2.5和Llama3.1的不同模型规模进行了各种基于lora的微调或零样本设置。通过比较实验(见表3),选择准确率最高(74.4%)的微调后的Qwen - 2.5 - 7B - Instruct作为评估器,验证了基于大语言模型的评估器和评估结果的有效性和可信度。
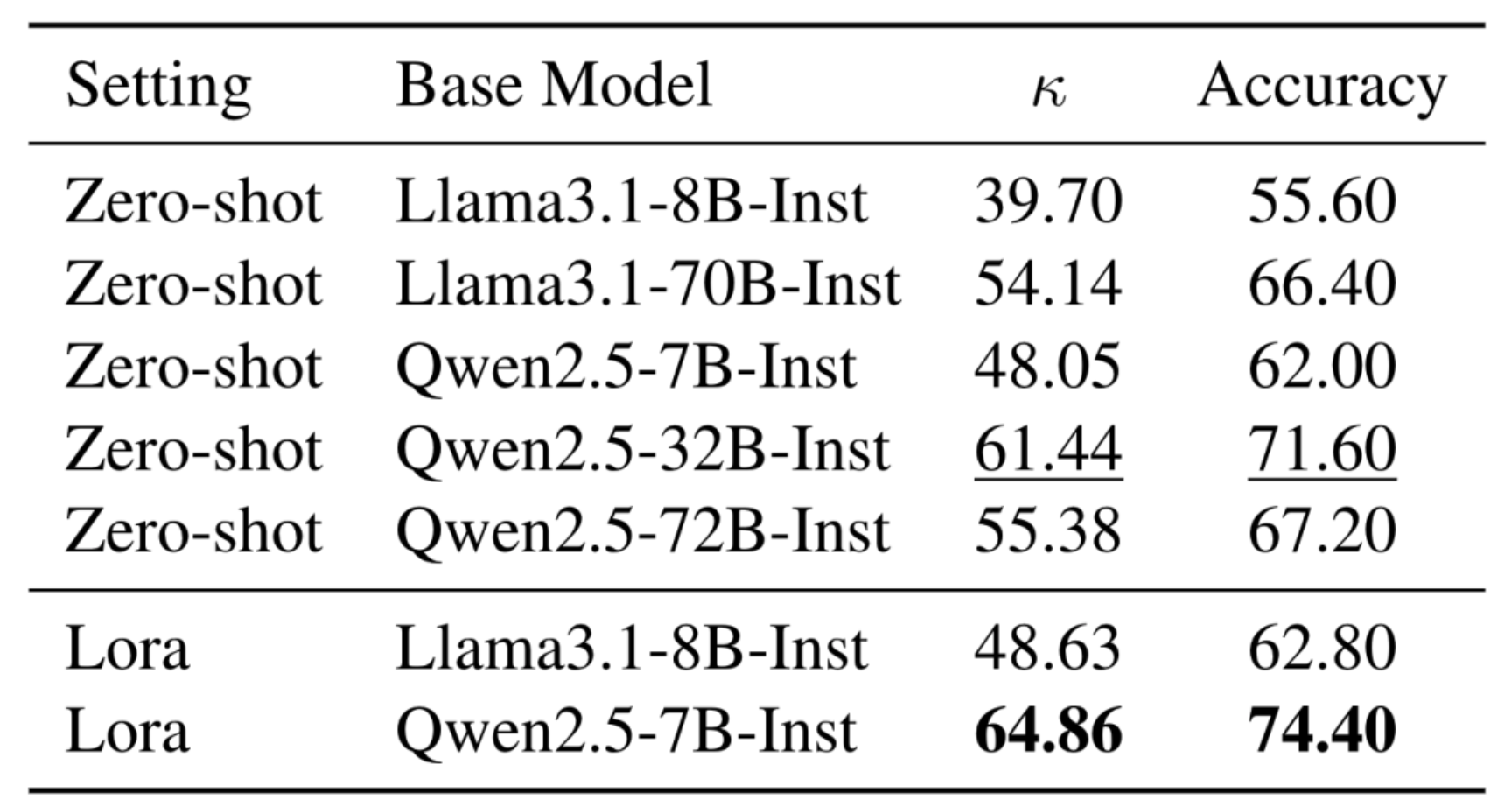
表3:基于模型的评估器实验结果。比较了不同设置(零样本和Lora微调)下Llama3.1和Qwen2.5不同模型规模在准确性和κ值方面的表现,确定了用于构建评估器的最佳模型。
实验设计
实验对象选择:在各种开源检索器和大语言模型上进行实验。检索器选择了GTE - Qwen2 - 1.5B、BGE - large - zh、BGE-m3和Jina - zh;大语言模型选择了Qwen2.5 - 72B、Deepseek - v2 - chat、Yi15 - 34b。
实验结果获取:利用自动生成和人工注释的评估数据集,通过上述两类指标对各种RAG基线进行全面准确的评估,得到包括检索模型(见表4)和RAG模型最终响应(见表5)的整体评估结果,以分析RAG系统在不同配置下的性能表现。
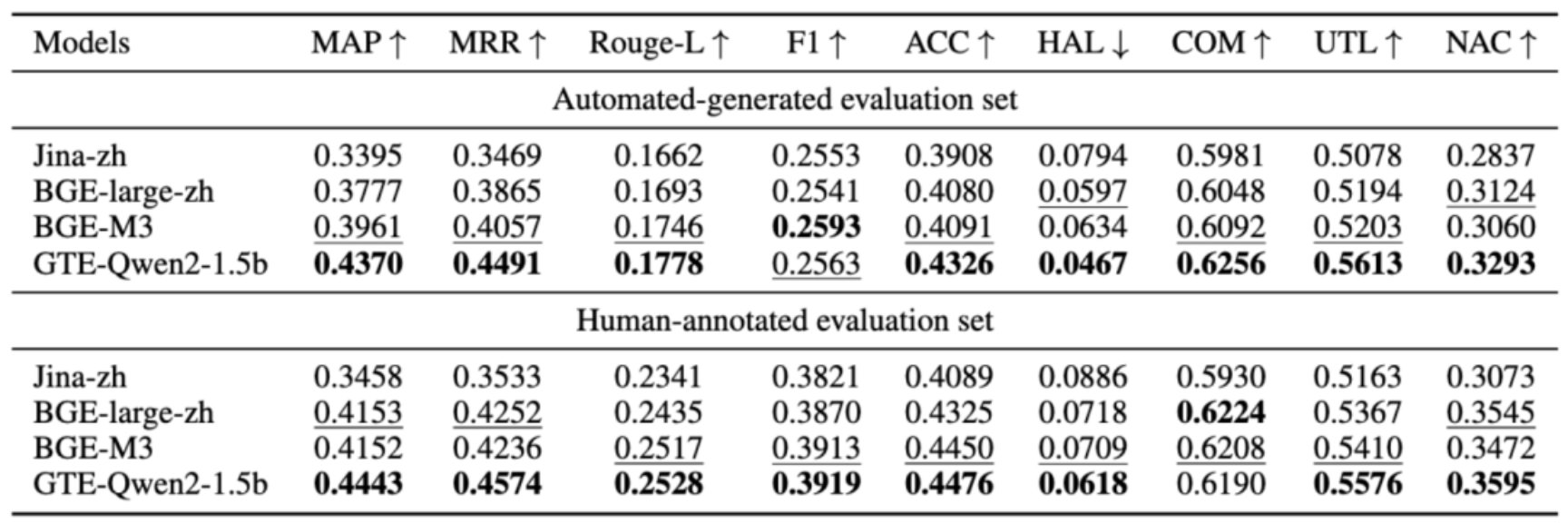
表4:以Qwen2.5 - 72B为生成器时检索模型的整体结果。展示了Jina - zh、BGE - large - zh、BGE - m3、GTE - Qwen2 - 1.5b等检索模型在MAP、MRR、ROUGE - L、F1等指标上的性能。
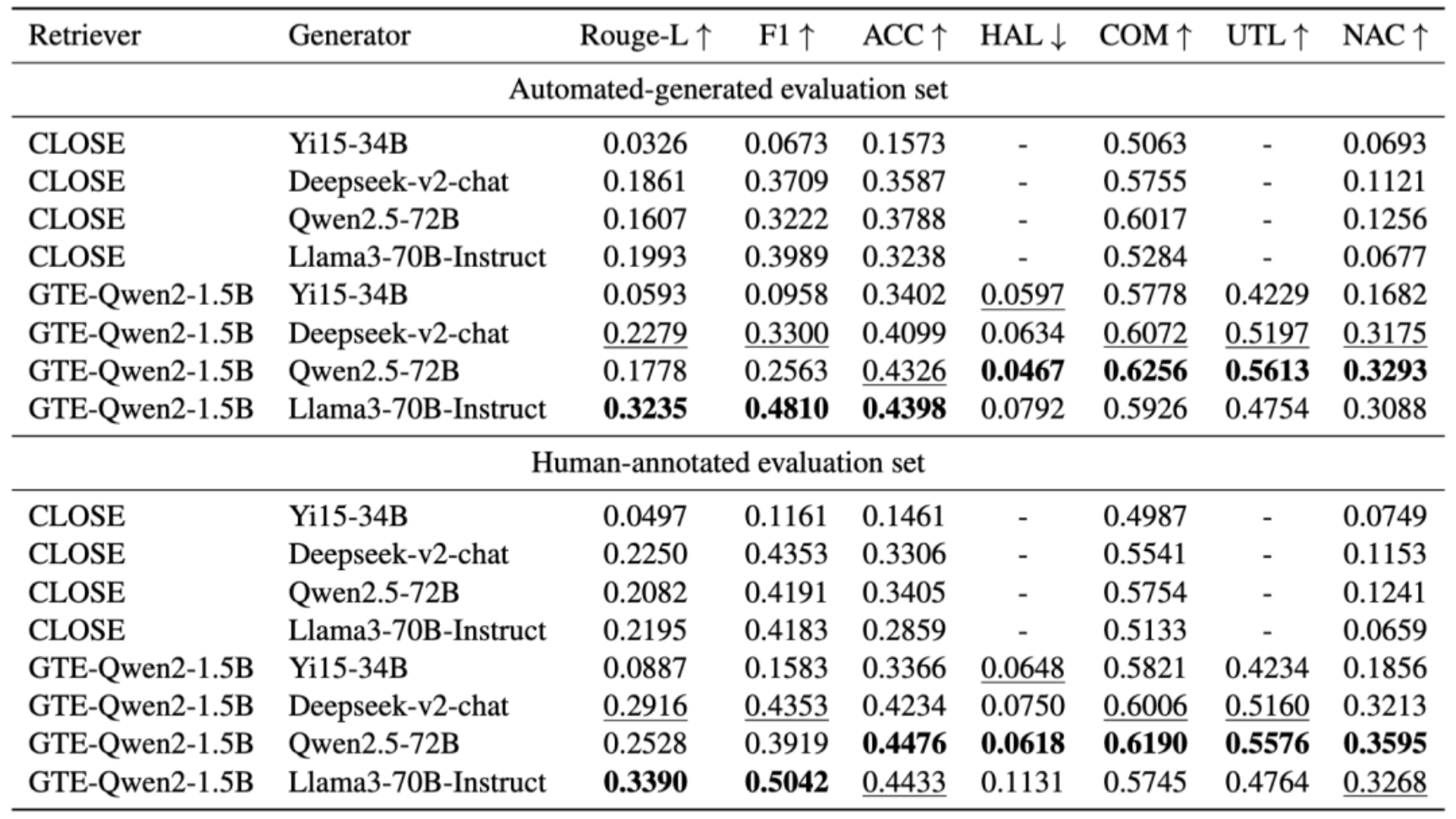
表5:RAG模型最终响应的整体评估结果。呈现了不同检索器与生成器组合(如CLOSE与不同生成器、不同检索器与Qwen2.5 - 72B等)在ROUGE - L、F1、ACC、HAL、COM、UTL、NAC等指标上的评估结果,全面反映RAG模型的性能。
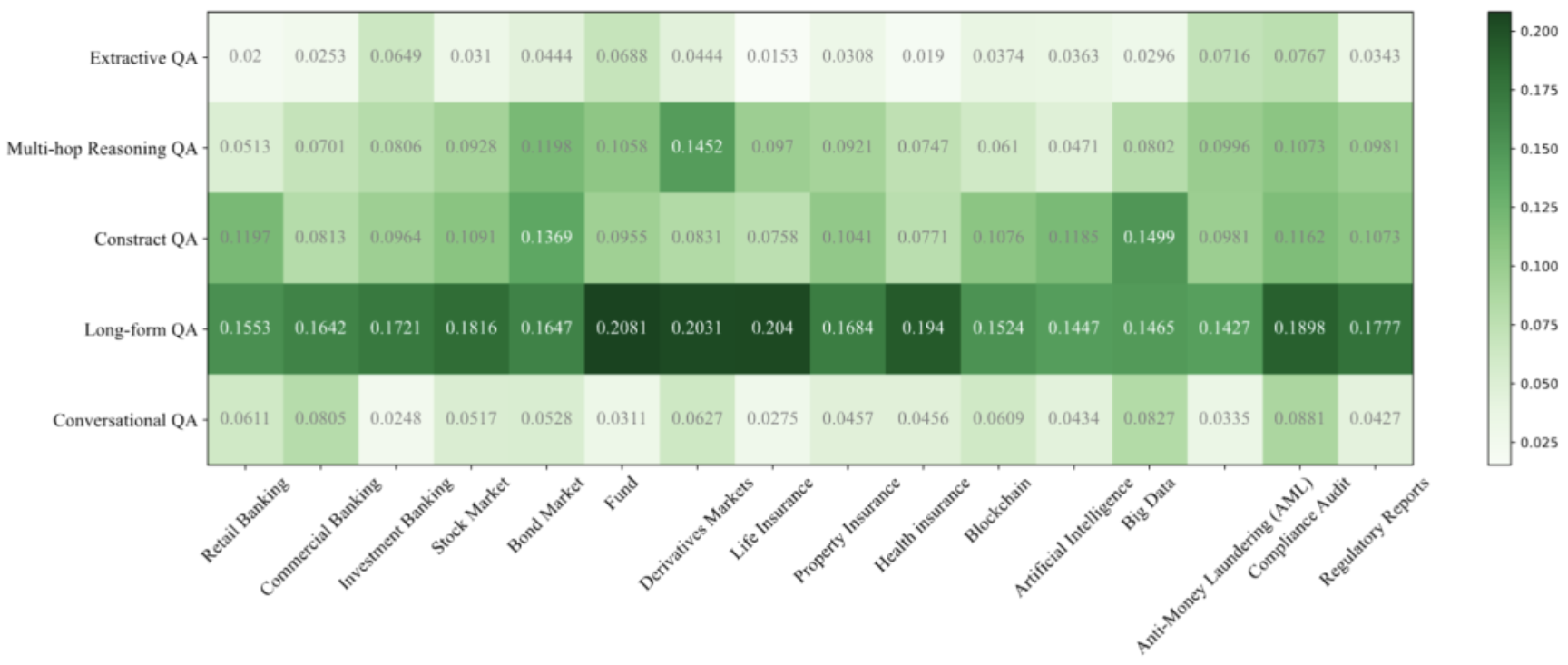
图7:在人工标注的集合上的基于矩阵的评估结果(GTE-Qwen2-1.5B+Yi15-34B on Rouge-L)
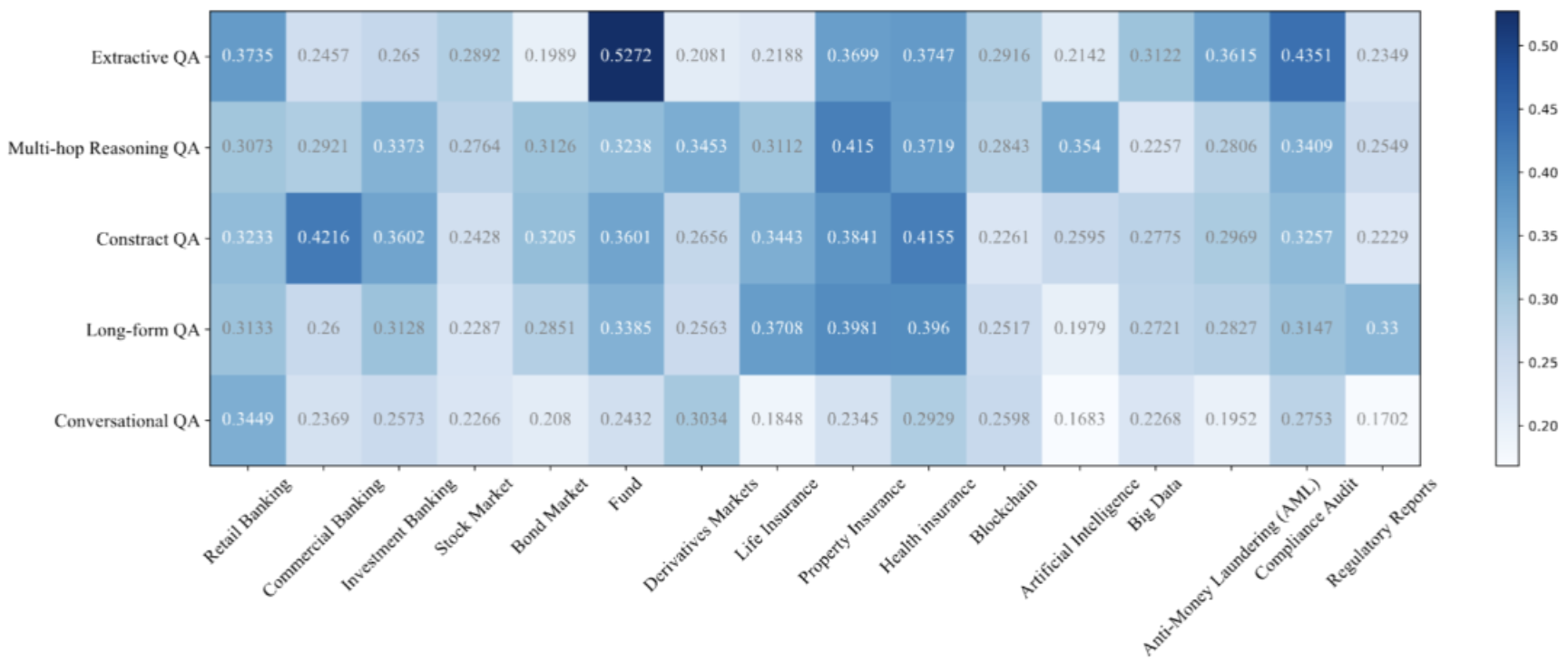
图8:在人工标注的集合上的基于矩阵的评估结果(GTE-Qwen2-1.5B+Deepseek-v2-chat on Rouge-L)
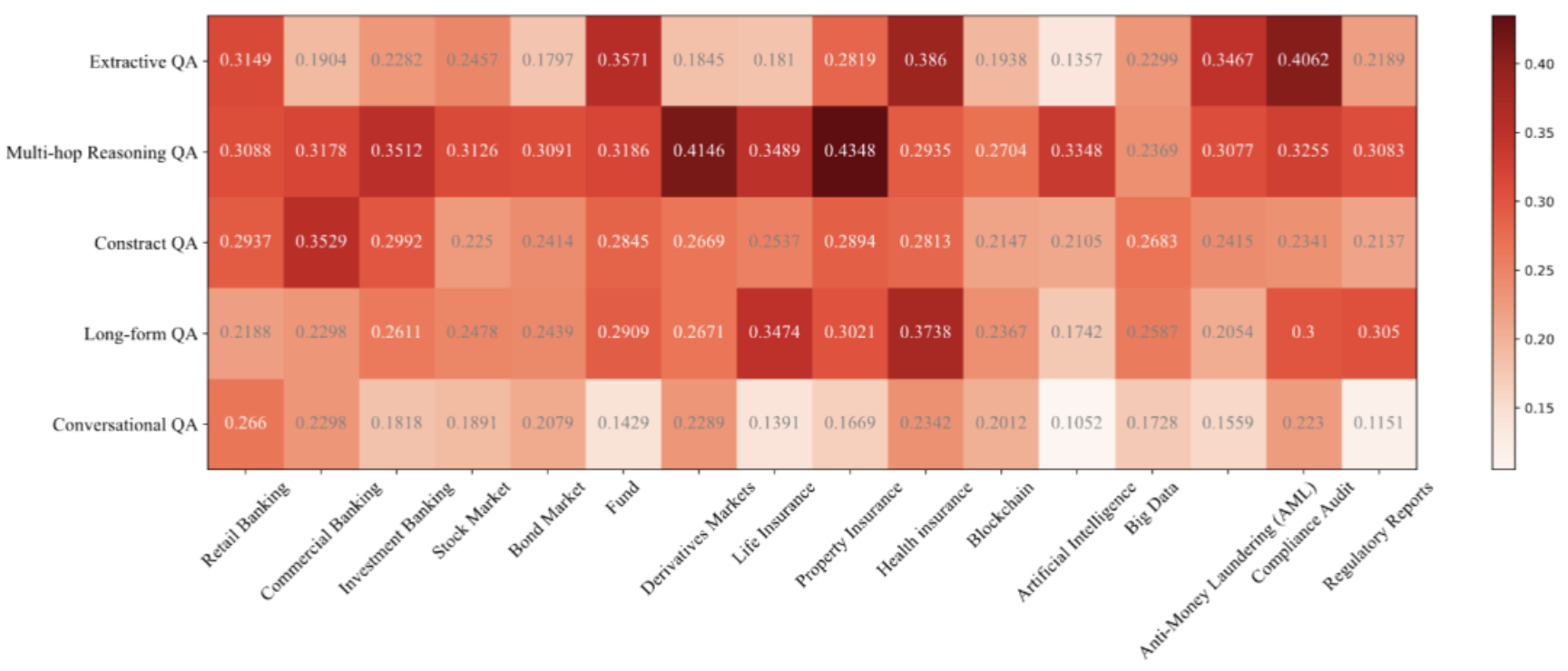
图9:在人工标注的集合上的基于矩阵的评估结果(GTE-Qwen2-1.5B+Qwen2.5-72B on Rouge-L)
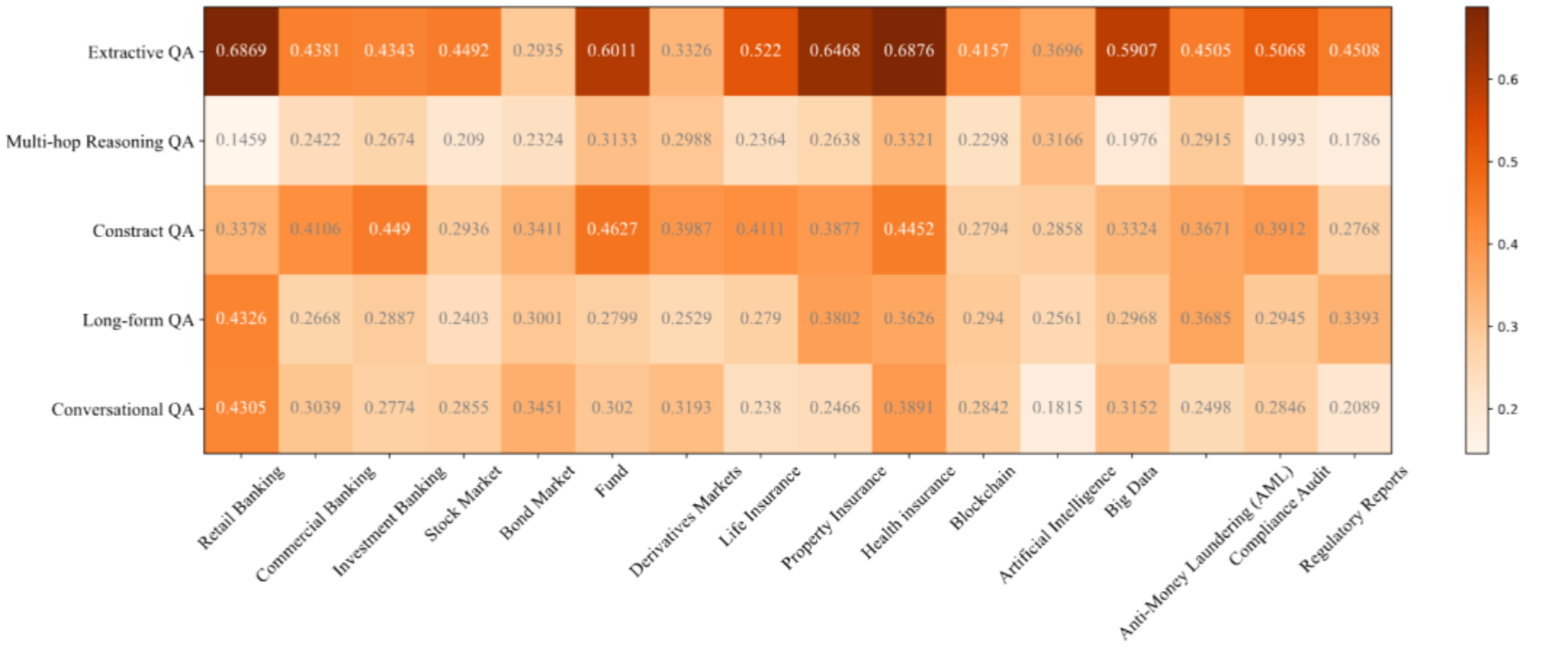
图10:在人工标注的集合上的基于矩阵的评估结果(GTE-Qwen2-1.5B+Llama3.1-70B on Rouge-L)
很明显,对于不同的查询话题和任务子集上,RAG模型效果差异较大。这种现象可能源于任务难度不同,以及各个话题相关的数据在大模型预训练预料中分布的差异。例如,大多数RAG模型在多跳推理和会话QA任务上表现较差,因为这两个任务需要RAG模型具备强大的推理或上下文理解能力,从而引入了更多的挑战。
总结
1研究意义
1. 提供金融领域RAG评估标准
OmniEval基准为金融领域的RAG系统提供了全面且自动的评估标准,填补了该领域高质量评估基准的空白,使RAG模型在金融场景下的性能评估更具规范性和系统性。
2. 助力RAG技术优化
通过多维度评估(如基于矩阵的场景、多阶段评估系统、多维指标等),能精准定位RAG系统在金融应用中的优势与不足,为其优化改进提供方向,推动RAG技术在金融领域的发展。
3. 创新评估方法与数据生成
创新的评估方法(如矩阵式场景分类、结合GPT - 4自动生成与人工注释的数据生成等)为RAG评估提供了新思路,不仅保证了评估的全面性,还通过人工评估验证了自动生成数据的有效性,提高了评估质量。
4. 推动金融领域智能化发展
帮助金融领域从业者更好地理解和应用RAG技术,提高金融信息处理的效率和准确性,进而促进金融领域的智能化转型,如智能客服、金融分析等应用场景的优化。
5. 为垂直领域研究提供范例
为其他垂直领域的RAG评估和模型优化研究提供了可借鉴的范例,有助于推动整个垂直领域RAG技术的研究进展,促进相关技术在不同专业领域的落地应用。
2未来方向
1. 优化评估基准
进一步扩充和完善OmniEval基准,涵盖更多金融子领域和复杂任务场景,增强基准的全面性和代表性。
持续改进数据生成方法,提高自动生成数据的质量和多样性,减少人工标注成本,同时确保数据的真实性和可靠性。
2. 提升RAG系统性能
根据评估结果,针对性地改进RAG系统在金融领域的薄弱环节,如提升检索器对专业知识的理解和筛选能力,增强生成器对金融术语和逻辑的处理能力。
探索更有效的模型架构和训练方法,结合金融领域特点进行优化,提高RAG系统在实际金融应用中的准确性、效率和稳定性。
提交测评
我们后续会在我们榜单(https://huggingface.co/spaces/RUC-NLPIR/OmniEval)中加入更多开源/闭源的模型。如果您想将您的模型提交到此排行榜,请联系我们。邮箱:wangshuting@ruc.edu.cn
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox