科研
你要的完整预训练细节!YuLan-Mini高效基座模型发布
日期:2025-01-02访问量:大语言模型的高效预训练一直面临着巨大的资源需求和技术过程的复杂性,近期,人大高瓴人工智能学院发布了 YuLan-Mini,一款 2.4B 参数量的高性能基座模型。我们的预训练方法包括:1. 精心设计的数据流程,将数据清理与数据调度策略相结合;2. 强大的优化方法,有效缓解了训练不稳定性;3. 有效的退火方法,结合了有针对性的数据选择和长上下文训练。在此次发布中,我们公布了所有技术细节和逐阶段的详细数据组成。
主页链接:https://github.com/RUC-GSAI/YuLan-Mini
论文地址:https://arxiv.org/abs/2412.17743
模型地址:https://hf.co/yulan-team/YuLan-Mini


八个开源榜单平均值:数学(GSM8K、MATH-500)、代码(HumanEval、MBPP)、推理(ARC-C、MMLU)和语言(HellaSwag、CEval)
YuLan-Mini 完全依靠人大科研力量从头预训练。作为 2.4B 小参数量模型,仅在 1.08T Tokens 上预训练,展现出优异的训练高效性:性能表现与业界同规模的模型相当,尤其是『数学』和『代码』两个领域。
为了提升高性能模型在社区中的开源程度,以及便于后续研究者在数据课程和退火数据选择上展开研究,我们完整开放了相关预训练细节,包括:逐阶段的详细数据组成,开源数据与我们合成的数据,逐阶段中间模型,退火前优化器状态。
模型评测:


评测结果显示YuLan-Mini:
在显著小的语料库(1.08T Tokens)上训练,表现仍具竞争力,数学推理和编程生成表现领先,有效扩展推理数据,通用基准上表现较强,平衡不同能力。
方法:
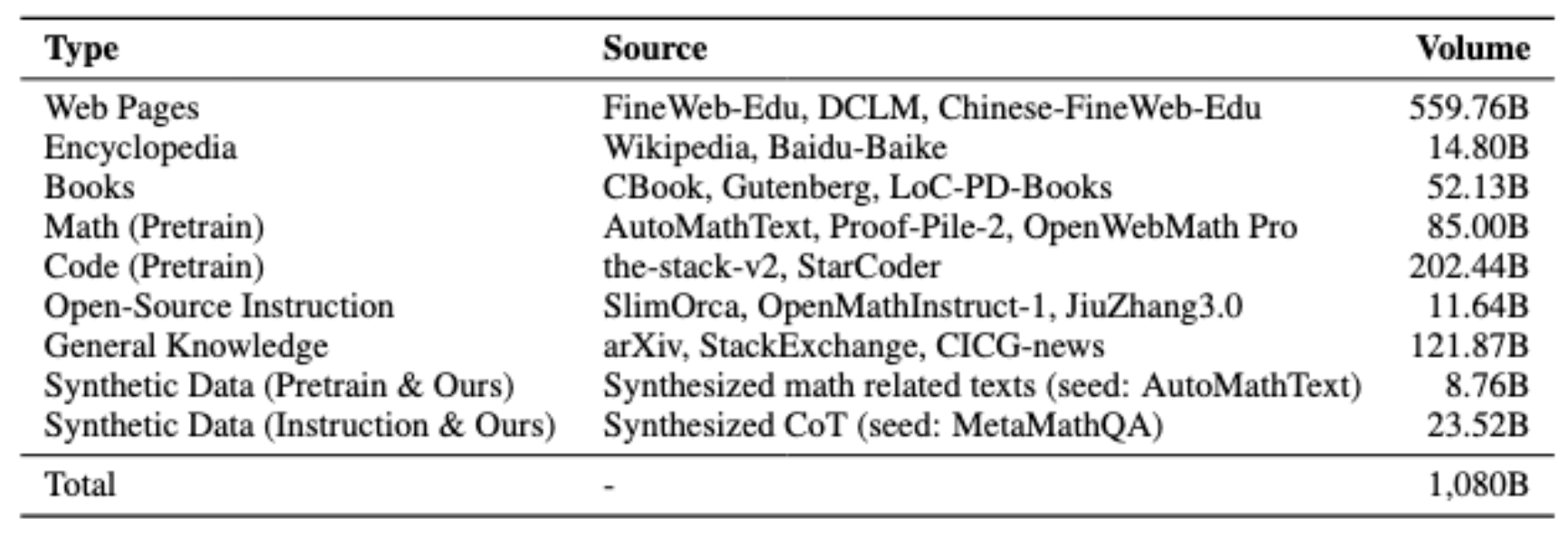
完整数据配比:
为了确保完整可复现性,我们公布了逐阶段的具体数据配比。下图的高清版本以及带有完整细节的列表会公布在 GitHub 主页,便于开源社区训练模型,以及后续研究者在数据课程和退火数据选择上展开研究。https://github.com/RUC-GSAI/YuLan-Mini

完整数据处理流程:
包括数据收集,去重、规则筛选、主题分类、质量打分和去污染,数据合成,数据课程。

多样化数据合成:
包括数学(合成文档、CoT推理、形式化数学等);代码(合成文档和CoT推理等)和科学。我们特别发现基于Lean的形式化数学和进阶推理数据(比如类o1具备反思的思维链)数据的有效性。
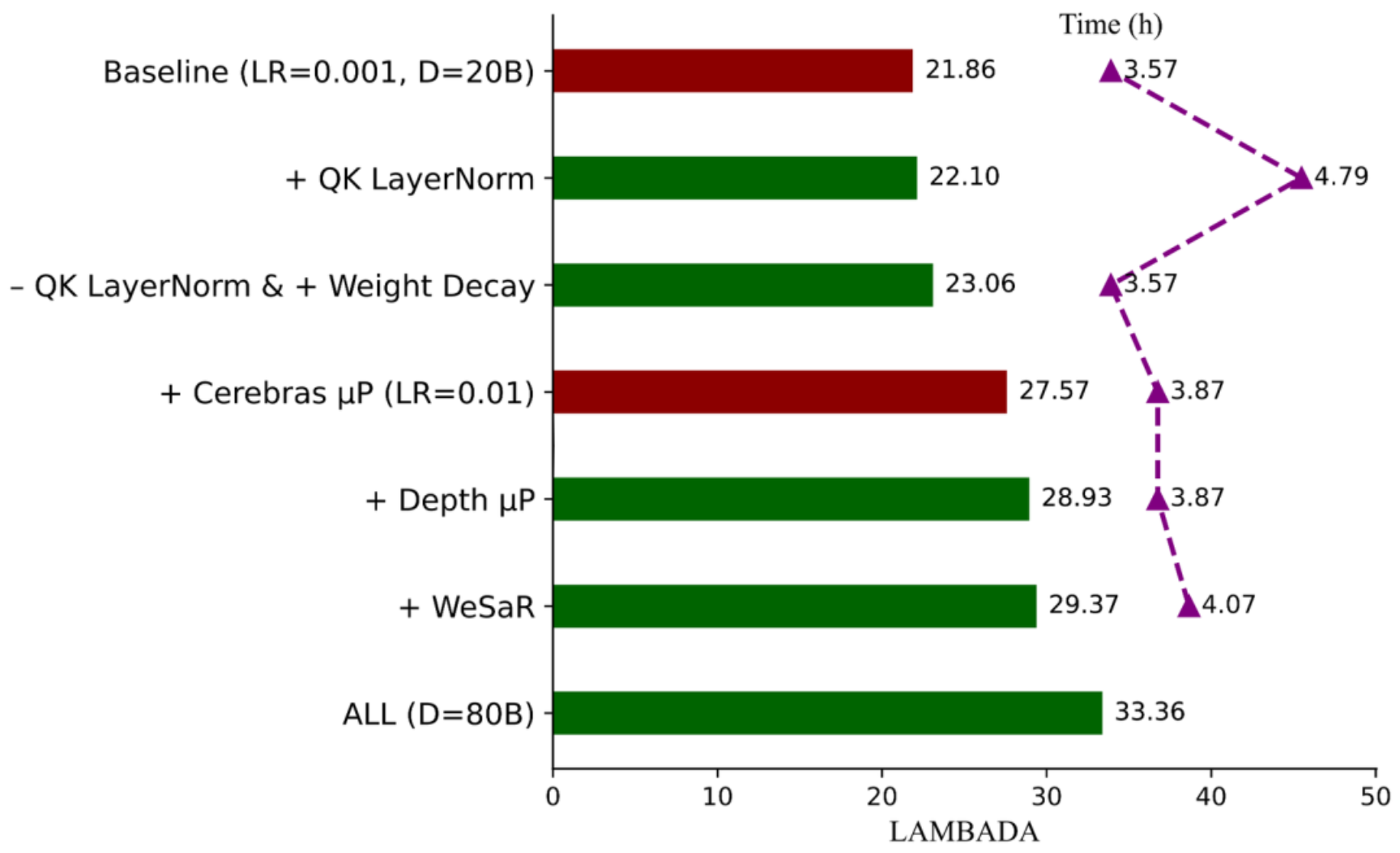
稳定训练:
主要使用重参数化与 µP 初始化方法稳定训练,Z-Loss、Weight Decay等稳定技巧配合,在0.01大学习率下减少损失函数尖刺。
写在最后
据了解,学术界真正坚持做从头预训练的研究团队越来越少,人大高瓴人工智能学院在算力和数据资源有限的情况下,坚信技术开放、持续探索才是真正的科研之路,我们一直努力在从事“解密”大模型预训练的工作,从大模型综述《A survey of large language models》到大模型中文书《大语言模型》,再到开源开放的两代玉兰从头预训练模型,致力于让大模型技术真正公开到关键细节。希望同有志于推动技术开放的算力公司或者数据公司携手合作,共同探索大模型前沿技术。
附录:Case Study
Math


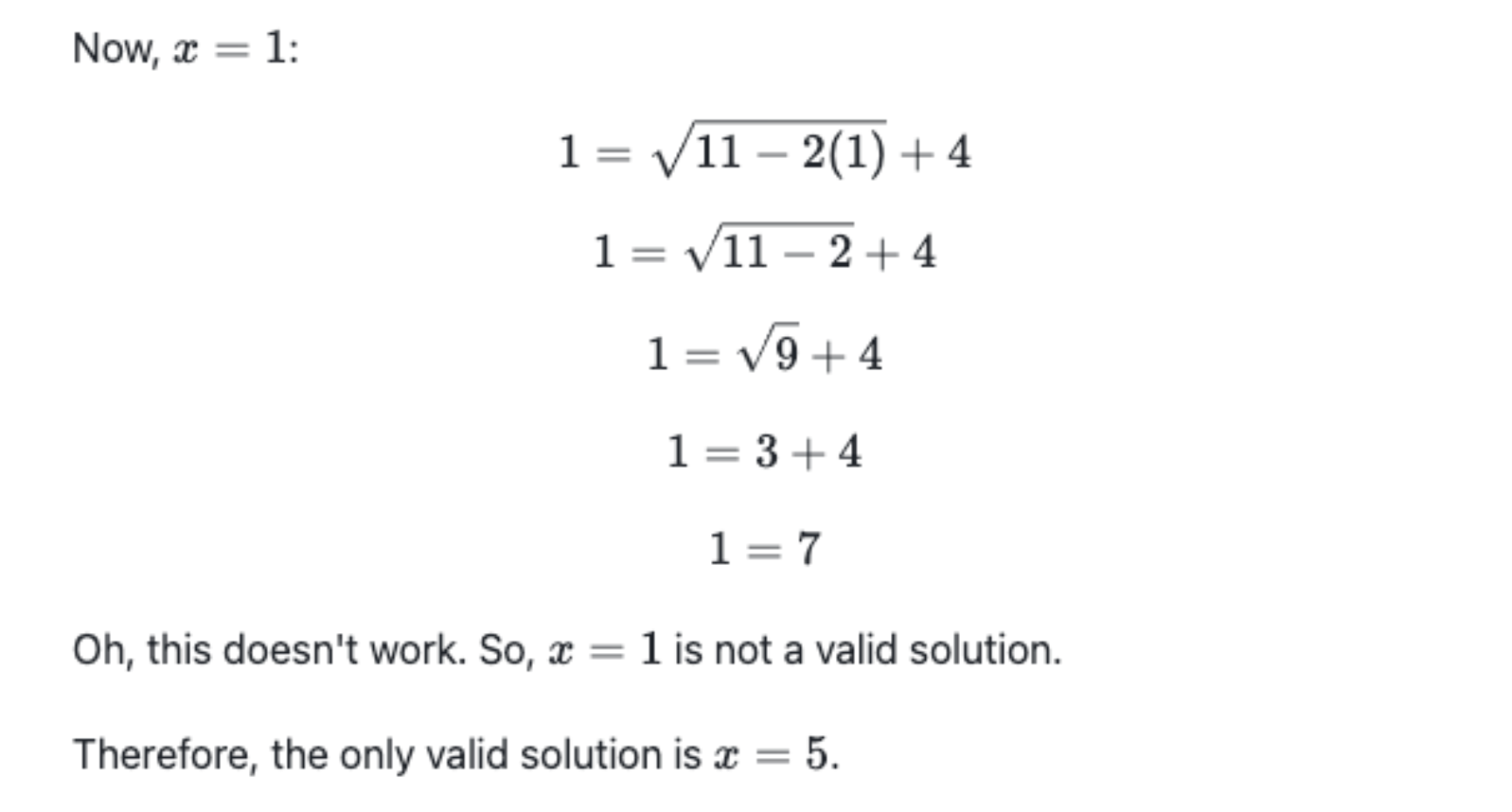
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox