科研
探索信息检索的未来:我院发布生成式信息检索综述
日期:2024-05-06访问量:在数字化时代,信息检索(IR)系统已成为我们获取知识、解答疑问、发现内容的重要工具。从谷歌搜索到智能问答系统,再到个性化推荐平台,IR技术无处不在,它们不仅提供信息,更是我们日常生活中不可或缺的工具。
传统的IR系统依赖于关键词匹配和文档排序,但随着预训练语言模型的兴起,一种全新的检索范式——生成式信息检索(GenIR)正在兴起。GenIR通过生成模型直接生成相关文档的标识符或直接生成可靠的回复来满足用户的信息获取需求。这不仅提高了检索的灵活性和效率,还极大地提升了用户体验。
为此,中国人民大学高瓴人工智能学院的师生们对生成式信息检索的最新研究进行了深入调查,并撰写了一篇综述文章,引用或介绍了超过350篇相关论文。该文章目前已以预印本的形式发布在arXiv网站上,旨在为研究者和工程师们提供技术参考。

论文链接:
https://arxiv.org/abs/2404.14851
GitHub项目链接:
https://github.com/RUC-NLPIR/GenIR-Survey
下面将简要介绍各个章节内容,完整内容请参阅我们的英文综述。
总览
生成式信息检索(GenIR)作为信息检索领域的一个新兴方向,其核心在于利用生成模型来实现信息检索的功能,而不是通过如图1(a)所示传统的相似度匹配方法。这种方法在处理用户查询时更为高效,因为它能够直接生成贴合用户需求的信息,而不需要用户在检索结果中进行筛选,再总结想要的答案。
GenIR的研究可以分为两大类:生成式文档检索(Generative Document Retrieval, GR)和可靠回复生成(Reliable Response Generation)。如图1(b)所示,GR通过生成模型的参数记忆文档,直接生成相关文档的标识符;另一方面,如图1(c)所示,可靠回复生成则利用语言模型直接生成用户所需的信息。这两种方法都旨在提高检索的效率和准确性,同时为用户提供更加丰富和个性化的搜索体验。
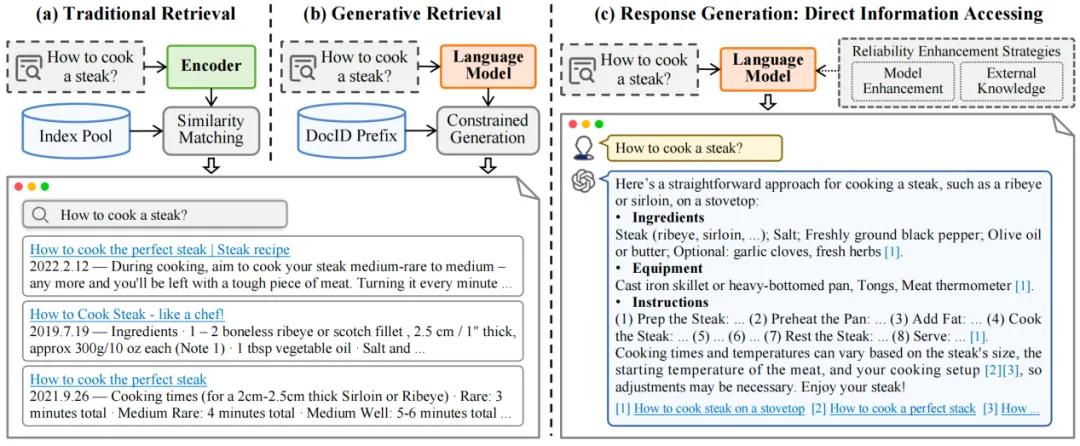
图1: 探索生成式信息检索的革新:从传统基于匹配的方法到基于生成的方法
下面是本综述的整体章节安排,涵盖了生成式文档检索、可靠回复生成、评估、挑战和前景:
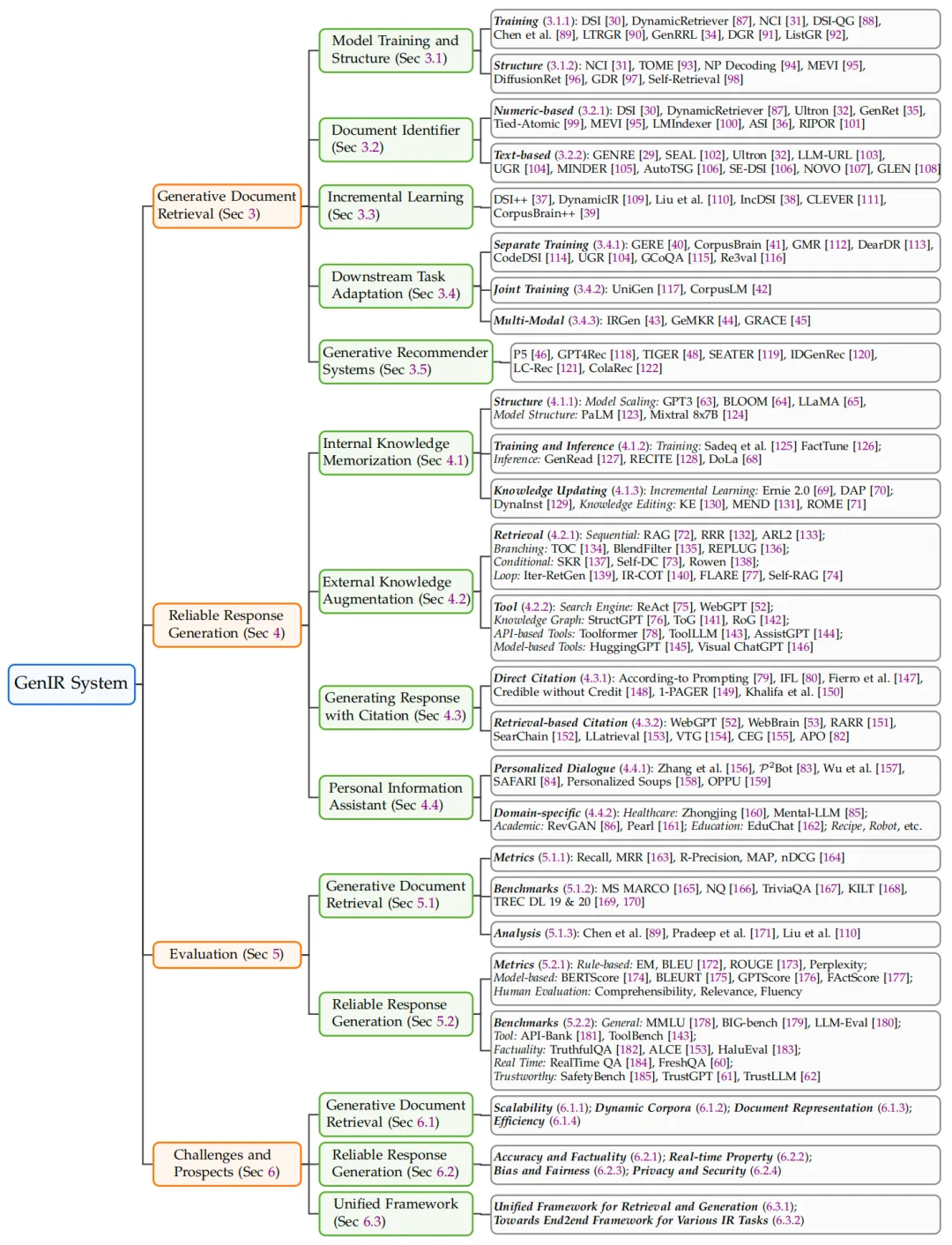
图2: 综述的章节安排,涵盖了生成式文档检索、可靠回复生成、评估、挑战和前景
生成式文档检索:从相似度匹配到生成文档标识符
在人工智能生成内容(AIGC)的最新进展中,生成式检索(GR)已成为信息检索领域的一种有前景的方法,引起了学术界的日益关注。图3展示了GR方法的时间线。最初,GENRE提出了通过限制集束搜索和预建的实体前缀树生成实体,实现了优越的实体检索性能。随后,Metzler等人构想了一个基于模型的信息检索框架,旨在结合传统文档检索系统和预训练语言模型的优势,创建能够在各个领域提供专家级答案的系统。
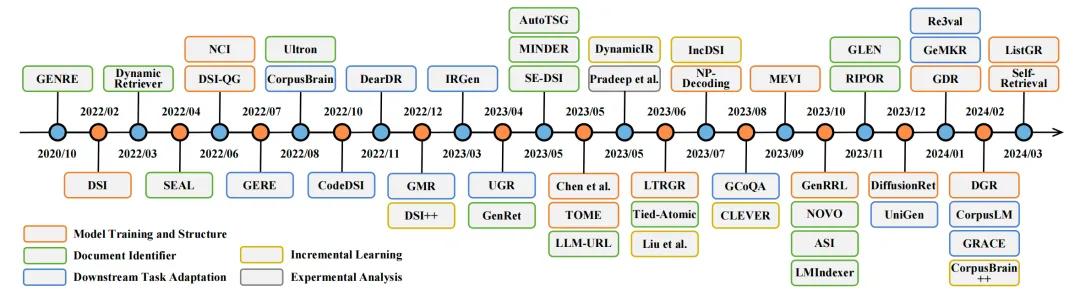
图3: 生成式文档检索相关研究的时间线
在这些工作的引领下,研究者提出了包括DSI、DynamicRetriever、SEAL、NCI等在内的一系列方法,相关工作不断涌现。这些方法探索了模型训练和架构、文档标识符、增量学习、任务特定适应性以及生成式推荐多个方面的内容。图4展示了GR系统的整体概览:
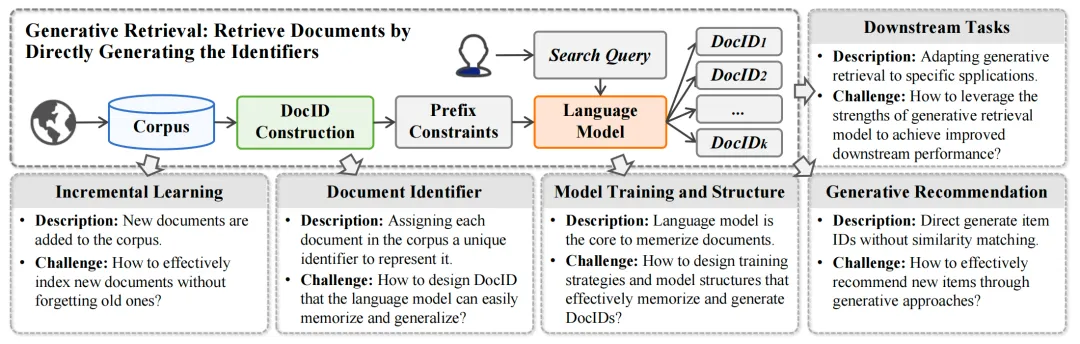
图4: 生成式文档检索的整体框架、各个模块及其挑战
我们深入讨论了生成式检索领域每个相关的研究方向,包括如下方面:
1. 模型训练与结构:GR模型的训练通常采用序列到序列(seq2seq)的方法,通过训练模型学习从查询到相关DocIDs的映射。研究者们还提出了多种数据增强和训练目标策略,以提升模型的检索性能。
2. 文档标识符:GR系统中的文档标识符(DocIDs)可以是数字序列或文本序列,它们作为模型的输出目标,帮助模型记忆文档内容。设计DocIDs的方式对于模型能否有效记忆和检索文档至关重要。
3. 增量学习:随着文档语料库的动态变化,GR模型需要能够增量学习新文档,同时保留对旧文档的记忆。研究者们开发了多种方法来优化模型以适应动态语料库。
4. 下游任务适应:GR模型不仅可以用于检索任务,还可以适应各种下游任务,如事实验证、实体链接、开放域问答等。
5. 多模态生成式检索:GR模型还可以结合多模态数据,如文本和图像,实现跨模态的检索。
6. 生成式推荐系统:基于GR的思想,推荐系统也可以不基于传统的匹配的方法,直接生成推荐物品的ID。
我们梳理了代表性GR方法中DocID的状态、数据类型和顺序;数据增强方法如常用的采样文档片段和生成伪查询的方法;以及训练目标包括基本的序列到序列目标、学习DocID以及排序的训练目标,进行了的详细比较,如下表所示:
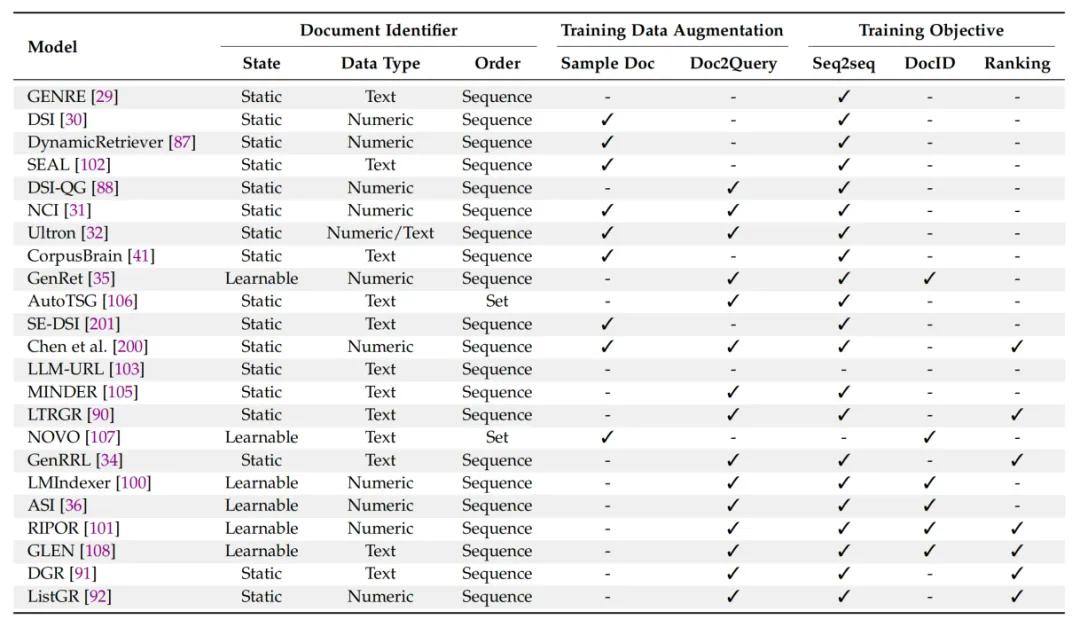
表1: 比较具有代表性的生成检索方法,针对文档标识符、训练数据增强和训练目标
可靠的回复生成:基于生成式语言模型直接获取信息
可靠回复生成是另一种GenIR方法,它侧重于直接生成用户所需的信息,而不是返回文档列表。大型语言模型的快速发展使它们成为了一种新型的信息获取方式,能够生成与用户信息需求直接对齐的可靠回复。这不仅节省了用户原本需要花费在收集和整合信息上的时间,而且还能够提供针对个体用户的个性化、以用户为中心的答案。
然而,创建一个能够提供可靠答案的GenIR系统仍存在挑战,例如幻觉、答非所问、无法将知识和生成内容关联、无法提供个性化信息获取需求等等,限制了人们对这种GenIR系统的信任和依赖。本节将讨论构建一个可靠的GenIR系统的策略,重点关注模型内部的优化、通过外部知识增强、生成带有引用的回复以及个性化信息助手的相关研究:
1. 内部知识记忆:为了生成可靠的回复,模型需要具备足够的内部知识。这涉及到模型结构的优化、训练以及推理技术的改进、模型知识的更新。
2. 外部知识增强:模型可以通过检索增强(如检索-生成模型)和工具增强(如API调用)来获取和利用外部知识,以提升回复的可靠性和准确性。
3. 生成带有引用的回复:在生成回复时,模型可以引用其知识来源,提供更加可信的内容。这包括直接在生成过程中引用,或在生成后添加引用。
4. 个性化信息助手:通过个性化对话系统和特定领域的个性化,模型能够理解用户的偏好和需求,从而生成更加个性化的回复。
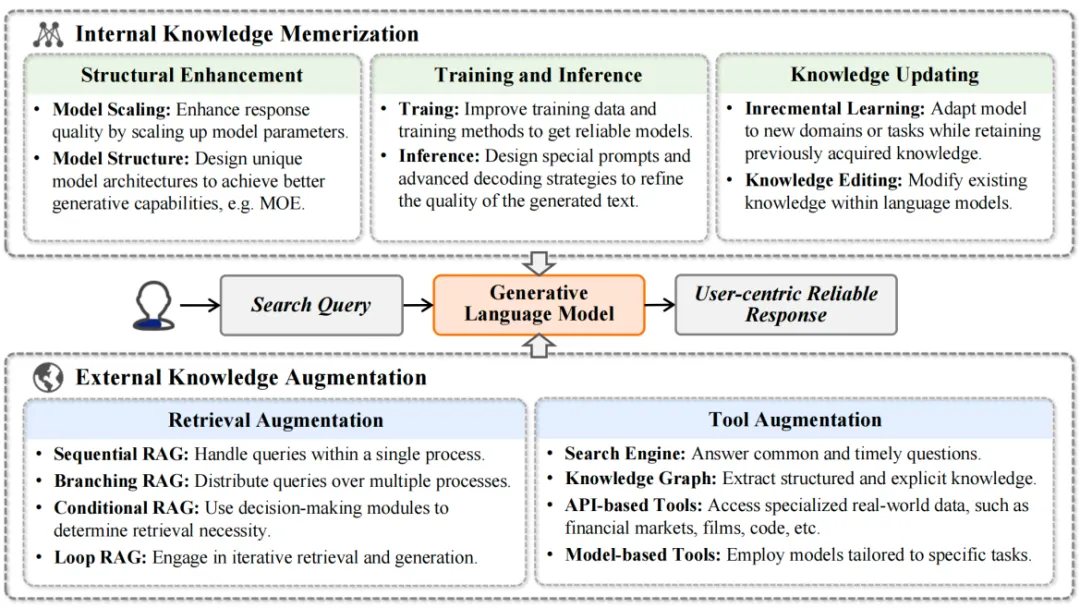
图5: 可靠的回复生成:内部知识记忆和外部知识增强
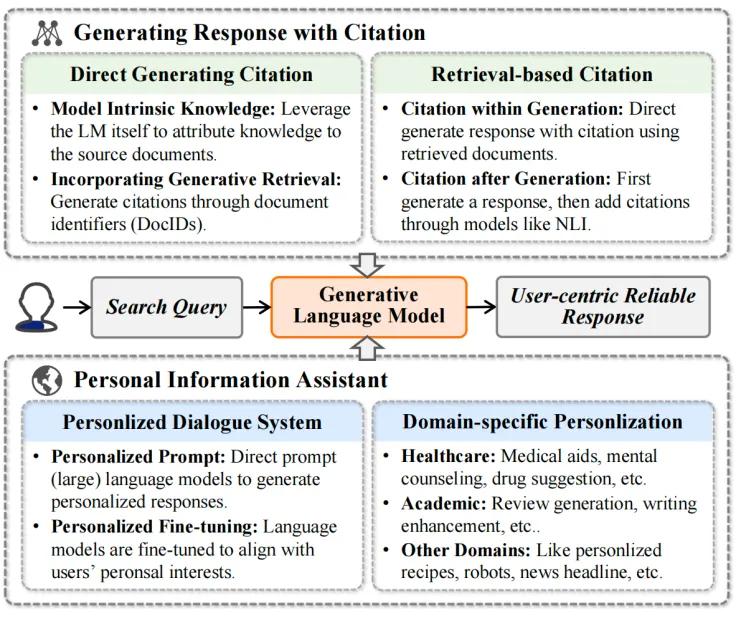
图6: 可靠的回复生成:生成带有引用的回复和个人信息助手
评估方法
文章系统从梳理了GenIR的评估方法。在生成式文档检索方面,评估主要依赖于几个核心指标,包括召回率(Recall)、R-精确度(R-Precision)、平均倒数排名(MRR)、平均精度(MAP)和归一化累积增益(nDCG)。这些指标从不同的角度衡量了检索系统的有效性,如准确度、效率和结果的相关性。此外,现有方法通过在如MS MARCO、NQ(Natural Questions)、TriviaQA和KILT等广泛应用的基准数据集上进行测试,以全面评估GR模型的性能。
对于可靠回复生成的评估,包括基于规则和基于模型的评价指标,以及人类评估指标,提供了对生成文本质量的全面审视。此外,还有一系列基准测试,如MMLU、BIG-bench、LLM-Eval、API-Bank、ToolBench、TruthfulQA、HaluEval、RealTime QA、FreshQA、SafetyBench、TrustGPT和TrustLLM,它们分别针对语言模型的不同能力进行评估,包括通用知识理解、工具使用能力、事实准确性、实时性、安全性和伦理性。这些评估方法不仅为GenIR系统提供了标准化的测试平台,也为未来的研究指出了改进的方向。
挑战与未来展望
前面讲到的两个方向都旨在通过生成式方法提升信息检索系统的性能和用户体验,但它们各自面临不同的挑战。我们也针对这些挑战给出了可能的研究方向和前景展望。
生成式文档检索的挑战:
1. 可扩展性:在处理百万级文档语料库时,GR的检索准确性仍低于密集检索方法。设计面向生成式检索的预训练,以及设计新的微调方法、新的模型结构、新的DocID来提升GR的可扩展性,必然是后面的研究重点。
2. 动态语料库:现实世界的应用经常涉及动态变化的文档集合,也需要设计更好的应对方法。
3.文档表示:如何设计高质量的文档标识符(DocIDs)的构建方法,是GR落地的关键。因为这关乎模型对DocID的记忆难度、对新文档库的可扩展性等重要方面。
4. 效率:当前GR方法在推理时依赖于受限的beam search,导致高延迟,这是GR方法大规模落地的关键之一,因此仍需更好的推理设计。
可靠回复生成的挑战:
1. 准确性和事实性:生成的回复需要确保内容的准确性和事实性。由于大型语言模型可能会产生虚假信息,这要求系统能够更好的发现和校正生成的错误内容。
2.实时性:GenIR系统需要及时提供最新的信息。由于预训练的生成模型的知识是固定的,因此需要通过检索和工具增强等方法来获取新知识。
3. 偏见和公平性:LLMs在训练时可能会从大量未过滤的数据中学习到偏见,这些偏见可能会在生成的回复中体现出来。研究者们正在探索减少这些偏见的方法,以构建更公平的GenIR系统。
4. 隐私和安全:生成的内容可能会涉及抄袭问题,因为预训练的语言模型可能会复制其训练数据中的大段文本。此外,LLMs可能会在受到攻击时返回在训练数据中看到的用户的私人信息,这需要有效的防御机制来增强安全性。
统一的框架:
1. 检索和生成的统一框架:目前,生成式文档检索和可靠回复生成被视为GenIR的两个主流形式,每种方法都有其优势和局限性。生成型文档检索仍然返回文档列表,而可靠的回复生成模型本身无法有效捕捉文档级别的关系。将这两种方法整合到一个统一的框架中是一个有前景的研究方向。
2. 端到端框架:我们还展望了未来的GenIR系统,是一个能够同时执行检索和一系列下游生成任务的大型搜索模型(large search model)。该模型不仅具有语言处理能力,还能够理解DocIDs并自身知识的来源。这样的模型可以决定何时生成DocIDs以拉取所需知识,再继续生成。未来,我们可以设计对齐知识和DocIDs的训练方法,并构建高质量的训练数据集,用于生成带有引用的答案,以训练这样的端到端GenIR模型。实现这一目标仍然具有挑战性,需要研究人员的协作努力,为构建下一代信息检索系统做出贡献。
本文作者:李晓熙(博士一年级),金佳杰(硕士一年级),周雨佳(博士五年级),张宇尧(本科四年级),张配天(硕士二年级),朱余韬(博士后),窦志成(教授)
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox