学院新闻
我院师生论文被CCF A类会议TheWebConf录用
日期:2022-01-24访问量:近日,2022年国际万维网会议(Proceedings of the ACM Web Conference 2022,简称 WWW’22)论文接收结果公布。中国人民大学高瓴人工智能学院师生12篇论文被录用。TheWebConf是中国计算机学会(CCF)推荐的A类国际学术会议,由国际万维网会议委员会(IW3C2)和主办地地方团队合作组织,每年召开一次,今年是第31届会议。本年度论文录用率为17.7%。

论文介绍
论文题目:Socialformer: Social Network Inspired Long Document Modeling for Document Ranking
作者:周雨佳,窦志成,苑华莹
通讯作者:窦志成
论文概述:利用 BERT 等预训练语言模型在信息检索中的文档排序方面取得了巨大成功。受限于计算和内存要求,长文档建模成为一个关键问题。在本文中,我们提出了模型 Socialformer,它将社交网络的特征引入到设计稀疏注意力模式中,用于文档排序中的长文档建模。具体来说,我们考虑了四种社交属性,从而在词之间构建一个类似于社交网络的图。由于社交网络的特性,图中的大多数节点对都可以在保证稀疏性的同时以短路径到达。为了方便计算,我们将图分割成多个子图来模拟社交场景中的朋友圈。这种剪枝使我们能够使用 Transformer 编码器实现两阶段的信息传输。实验结果证实了我们的模型对长文档建模的有效性。

论文介绍
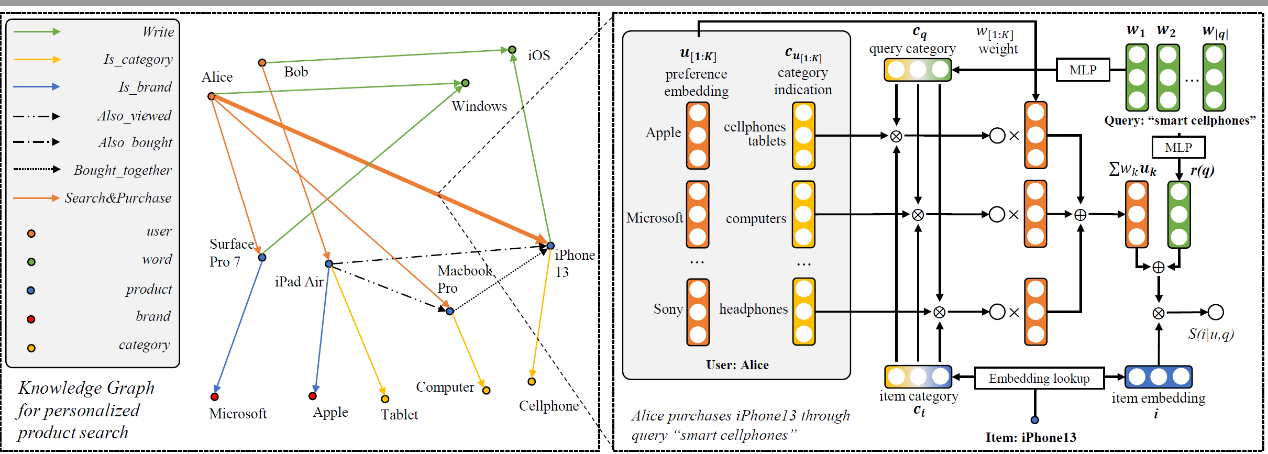
论文题目:A Category-aware Multi-interest Model for Personalized Product Search
作者:刘炯楠,窦志成,朱倩男,文继荣
通讯作者:窦志成
论文概述:现有的个性化产品搜索往往将用户兴趣建模为单个向量,忽略了用户在不同产品类别上可能存在不同偏好的问题。为了解决这个问题,本文提出了一个基于KG的多兴趣模型来建模用户偏好。该多兴趣模型除了建模了用户的兴趣向量之外,也刻画了每个兴趣向量对应的产品类别分布情况,通过基于查询和产品的注意力机制,集成多维兴趣对产品进行打分。同时在模型训练时,我们引入了一个多样化损失项,防止建模的同一用户的不同兴趣出现同质化现象。实验结果证明,我们提出的模型相比现有模型有明显的效果提升。
论文介绍
论文题目:A Gain-Tuning Dynamic Negative Sampler for Recommendation
作者:朱倩男,张昊博,贺清,窦志成
通讯作者:窦志成
论文概述:基于隐性反馈的推荐通常通过对用户反馈数据的配对学习来优化模型,在优化过程中选择可靠的负训练实例是一项具有挑战性的任务。现有的方法通常利用用户反馈数据上的各种负采样器(例如基于启发式或基于GAN的采样)来提高负样本的质量。然而,目前方法专注于选取具有高梯度的hard负样本进行训练,倾向于优先选择假阴性负样本,带来假阴性负样本的噪声放大,从而可能造成模型的过度拟合和进一步的不良泛化。为了解决这个问题,我们提出了一个增益调节驱动的动态负采样模型GDNS,使推荐更加稳健和有效。这个模型设计了一个期望增益采样器,利用训练中用户对正例和负例样本的偏好差距的期望,以动态地指导负例样本的选择。这种增益调节的负例采样器可以有效地识别虚假的负例样本,进一步降低引入虚假负例样本的风险。此外,为了提高训练效率,我们在每次迭代中为每个用户构建了正负样例组,并开发了一个分组优化器,以交叉方式对其进行优化。在两个真实世界的数据集上的实验表明,我们的方法明显优于最先进的负采样基线。

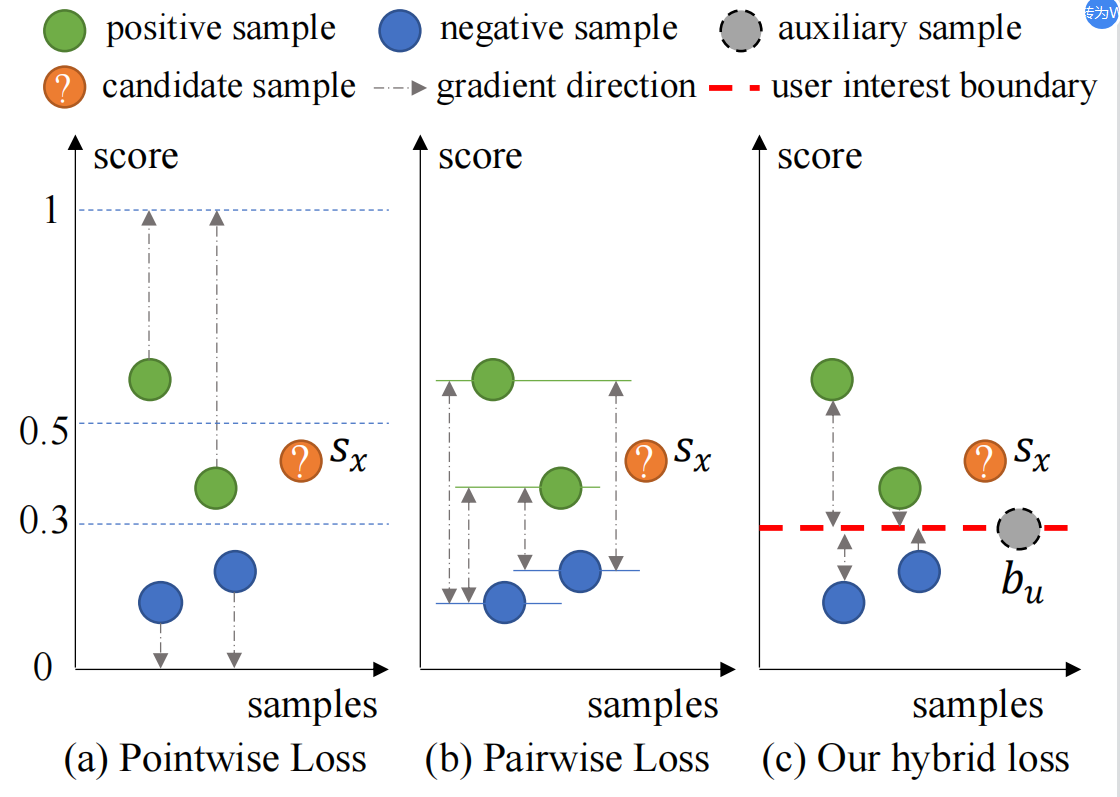
论文题目:Learning Explicit User Interest Boundary for Recommendation
作者:卓建欢*,朱倩男*,岳银亮,赵雨虹
通讯作者:岳银亮
论文概述:推荐系统建模的核心目标是最大化正样本分数s_p和最小化负样本分数s_n,这通常可以概括为两种范式:逐点和成对范式。逐点范式将每个样本分别与其标签相匹配,这在实例级别的加权和采样方面具有灵活性,但忽略了固有的排序特性。通过定性地最小化相对分数s_n-s_p,成对范式能自然地捕获样本的排序,但也存在训练效率低的问题。此外,这两种范式都很难明确提供个性化的决策边界,以确定用户是否对未交互的物品感兴趣。为了解决这些问题,我们创新性地为每个用户引入了一个辅助分数b_u来表示用户兴趣边界(UIB),并使用成对范式分别惩罚跨越边界的样本,即分数低于b_u的正样本和分数高于b_u的负样本。通过这种方式,我们的方法成功地实现了逐点范式和成对范式的混合损失,从而将两者的优点结合起来。分析表明,该方法不需要任何特殊的抽样策略,可以提供个性化的决策边界,显著提高训练效率。大量实验表明,我们的方法不仅在经典的逐点或成对模型上,而且在具有复杂损失函数和复杂特征编码的最新模型上都取得了显著的改进。
论文介绍
论文题目:A Model-Agnostic Causal Learning Framework for Recommendation using Search Data
作者:思子华,韩雪冉,张骁,徐君,殷越,宋洋,文继荣
通讯作者:徐君
论文概述:基于机器学习的推荐系统逐渐成为帮助人们自动过滤信息、发掘兴趣的主要方式。现存模型通常使用embedding来表示推荐系统中丰富的信息,比如物品、用户和上下文信息。从因果分析的角度来看,这些向量和最终用户反馈之间的关系是由因果关系和非因果关系混杂在一起组成的。因果关系是反应物品被用户偏好的原因,非因果的关系仅仅反应用户和物品之间的统计依赖关系,比如:曝光模式、公众观念、展示位置等。然而现存推荐算法大部分都忽略了因果关系和非因果关系之间的不同之处。在这篇文章中,我们提出了一个模型无关的叫做IV4REC的因果学习框架来有效的分离出这两种关系,从而加强推荐模型的效果。更确切地说,我们联合考虑了搜索场景和推荐场景下的用户行为。借鉴了因果推断中的概念,我们将用户的搜索行为作为工具变量(Instrumental variables(IVs)),来帮助分解原本推荐中embedding,即treatments。IV4REC然后使用深度神经网络将分离的两个部分结合起来,用结合后的结果来完成推荐任务。IV4REC是一个模型无关的框架,可以应用到众多推荐模型中,比如:NRHUB和DIN。在公开数据集MIND和一个商业软件的工业级数据上的实验结果验证了IV4RE有效提升了推荐模型的效果。

论文介绍
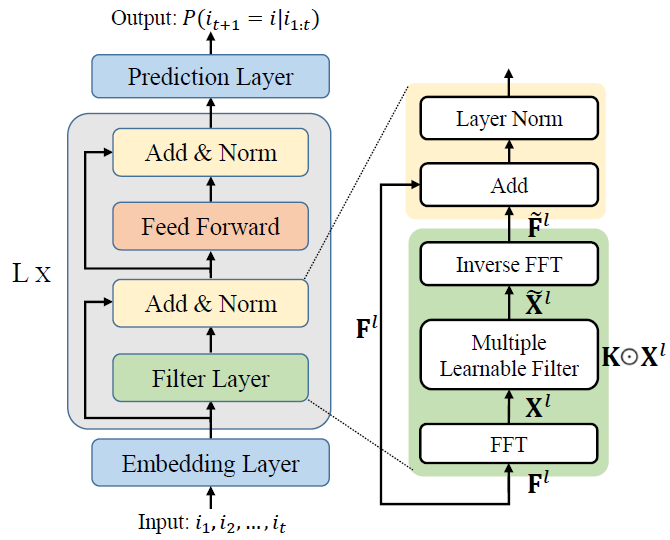
论文题目:Filter-enhanced MLP is All You Need for Sequential Recommendation
作者:周昆,于辉,赵鑫,文继荣
通讯作者:赵鑫
论文概述:基于RNN,CNN,Transformer等架构的模型已经广泛用于序列化推荐任务以建模用户序列化的行为特征。然而用户行为往往不可避免地带有噪声,以上较为复杂的模型往往容易拟合该部分噪声。借鉴信号处理领域,我们首先发现简单的滤波算法可以直接给这些模型带来提升,且直接将这些滤波算法与纯MLP模型结合都能超越许多复杂模型。受此启发,我们提出了一个简单且高效的纯MLP的序列化推荐模型,其基于可学习的自适应滤波器来在频域下消除噪声数据影响,等价于时域下的循环卷积算法。在8个数据集上的大量实验证明了我们模型的有效性。
论文介绍
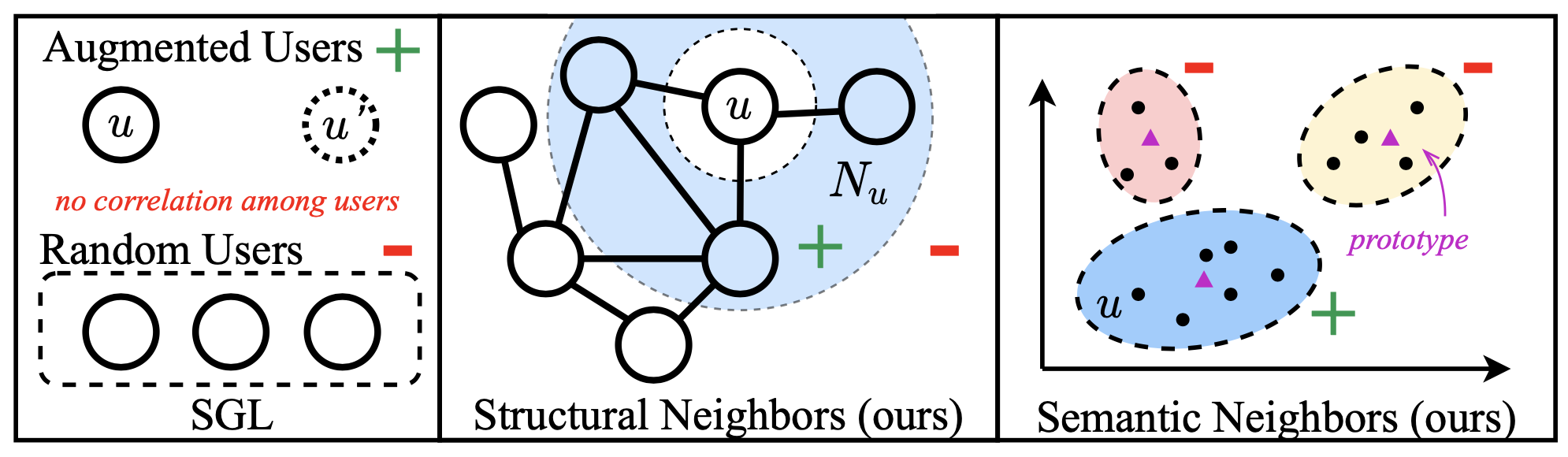
论文题目:Improving Graph Collaborative Filtering with Neighborhood-enriched Contrastive Learning
作者:林子涵,田长鑫,侯宇蓬,赵鑫
通讯作者:赵鑫
论文概述:在推荐系统的研究中,图协同过滤方法试图将用户和物品之间的交互建模为二部图,但实际场景中存在的数据稀疏问题对这类方法影响较大。最近对比学习被应用于图协同过滤方法上来缓解数据的稀疏性,然而这些方法通过随机扰动来构建对比目标,忽略了推荐场景下广泛存在的用户(或商品)之间的邻居关系,未能充分发挥对比学习应用于推荐时的潜力。为了解决上述问题,我们提出了一种新颖的对比学习范式 NCL,它显式地将潜在的邻居关系构造为对比目标。具体来说,我们分别从图结构和语义空间中引入用户(或商品)的邻居。对于二部图上的结构邻居,我们将GNN不同层的输出分别视为节点自身的表示及其结构邻居表示来构建对比目标。此外,为了挖掘语义空间中潜在的邻居关系,我们假设具有相似表示的用户是语义空间中的邻居,并将其纳入原型对比目标。在五个公共数据集上进行的大量实验证明了所提出方法的有效性。
论文介绍
论文题目:Unbiased Sequential Recommendation with Latent Confounders
作者:王振磊,沈世奇,王志鹏,陈波,陈旭,文继荣
通讯作者:陈旭
论文概述:序列化推荐系统通过捕获连续的行为关系来推断用户偏好。现有的研究主要集中在设计不同的模型,以便更好地拟合离线数据集。然而,观测数据可能受到曝光和选择的偏差,这使得学习的序列模型不可靠。为了解决这一基本问题,在本文中,我们提出用潜在结果框架重新表述序列化推荐任务,在这个框架中,我们能够清楚地理解数据偏差机制,并通过使用反向倾向评分(IPS)重新加权训练实例来纠正它。为了提高建模的鲁棒性,在IPS估计中采用了裁剪策略,以减小学习目标的方差。为了使我们的框架更加实用,我们设计了一个参数化模型来消除潜在的混杂因子的影响。最后,我们从理论上分析了该框架在IPS权重下和裁剪IPS权重下模型估计的无偏性。据我们所知,这是关于序列化推荐系统纠偏的第一项工作。我们在合成数据集和真实数据集上进行了广泛的实验,以证明我们的框架的有效性。
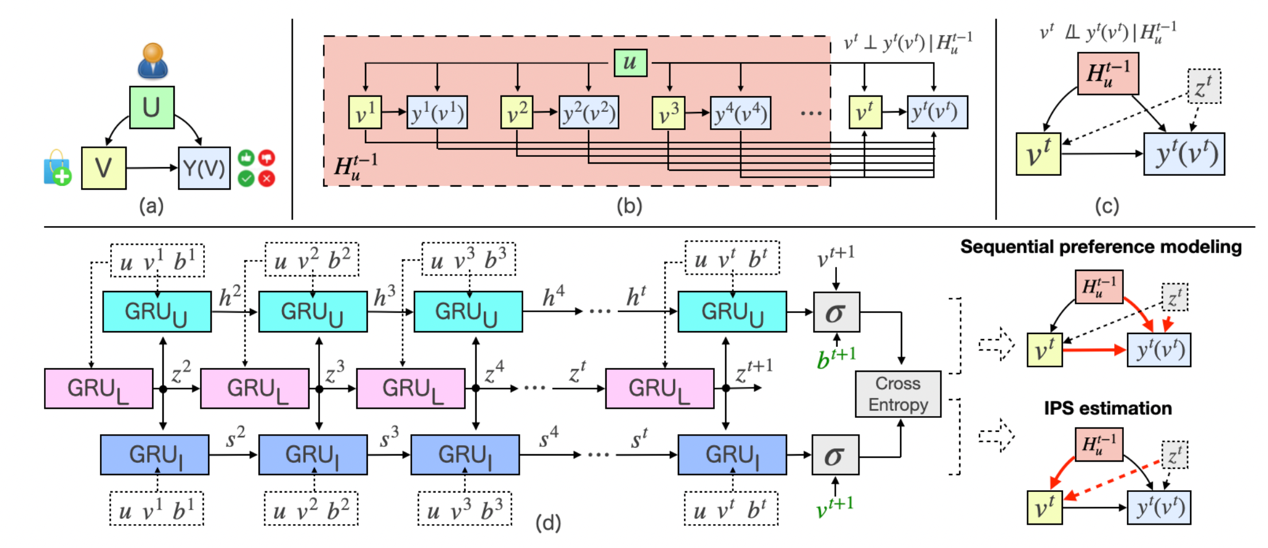
论文介绍
论文题目:Sequential Recommendation with Decomposed Item Feature Routing
作者:林焜,王振磊,王志鹏,陈波,沈世奇,陈旭
通讯作者:陈旭
论文概述:序列化推荐的基本目标是捕获用户不断变化的偏好。直观地说,用户与项目交互通常是因为某些特定的特征,而用户不断变化的偏好本质上是由沿时间线上的一系列重要特征决定的。然而,现有的序列推荐模型通常通过一个统一的嵌入来表示每个项目,这无法区分项目特征,更不用说对特征序列进行建模了。为了弥补这一差距,同时能够实现更集中的模型优化和更好的推荐性能,本文提出了一种新的序列化推荐模型,用于学习用户行为背后的关键项特征序列。为了达到这个目标,我们首先用显式或隐式的特征来表示每个项目,然后建立软模型和硬模型来寻找最优的特征序列。更具体地说,在软模型中,我们设计了一个2D注意机制,它能够同时区分序列中项目的重要性和同一项目中特征的重要性。对于硬模型,我们将特征寻找问题视为一个马尔可夫决策过程,并提出了一种强化学习方法来生成特征序列,从而降低了负对数似然。我们在多个真实数据集上与多种方法进行比较,实验证明我们的模型在NDCG和MRR上分别有8.2%和16.1%的提升。
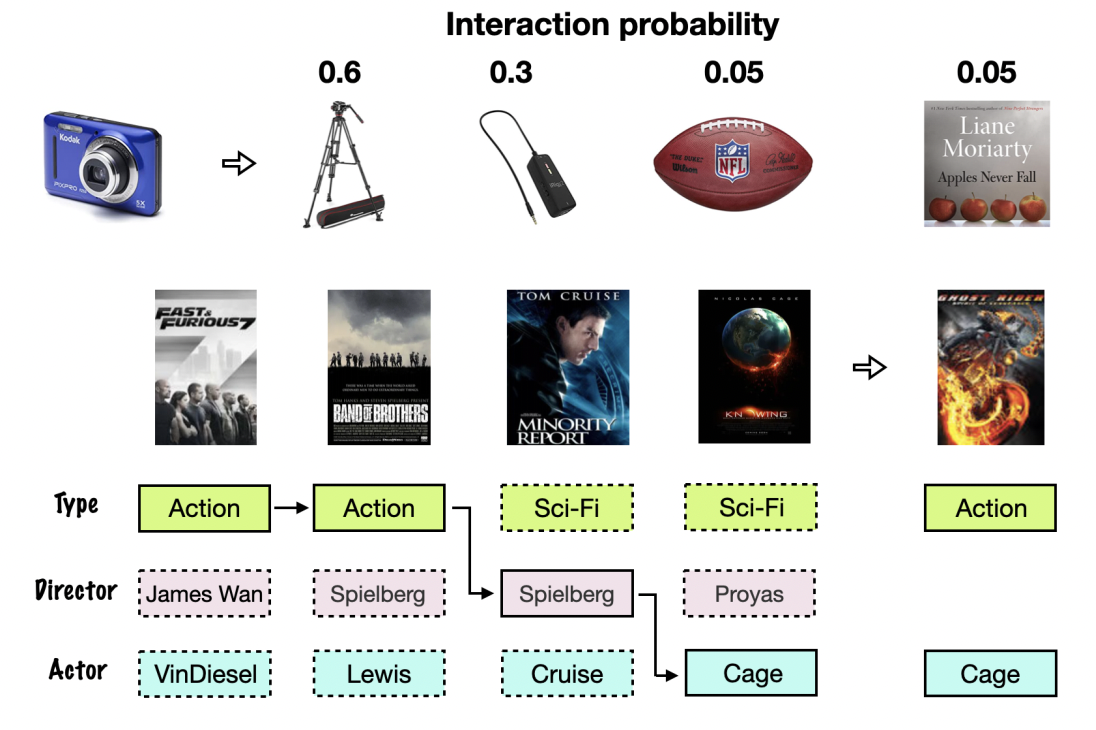
论文介绍
论文题目:Generative Session-based Recommendation
作者:王志丹,叶文文,陈旭,张文强,王振磊,邹立新,刘卫东
通讯作者:陈旭
论文概述:序列化推荐系统最近越来越受到学术界和工业界的关注。以往的模型大多通过设计不同的神经模型,引入不同的诱导偏差来拟合训练数据。然而,在实践中,推荐数据可能非常稀疏,尤其是对于用户的顺序行为,这使得学习可靠的模型非常困难。为了解决这个问题,本文提出了一种新的基于生成序列的推荐框架。论文核心思想是生成额外的样本以补充原始训练数据。为了产生高质量的样本,我们考虑两个方面:(1)用户行为序列的合理性(2)训练目标模型的信息量。为了满足这些要求,我们设计了一个双对抗网络。第一个对抗性模块旨在使生成的样本符合真实用户顺序偏好。第二个对抗性模块旨在生成使得模型损失值较大的样本。在我们的模型中,样本是基于强化学习策略生成的,其中奖励的设计基于上述两个要求。为了使训练过程稳定,我们引入了一种self-paced正则化项,以一种简单到困难的方式学习agent。我们在真实数据集上进行了大量实验,证明了我们模型的有效性。
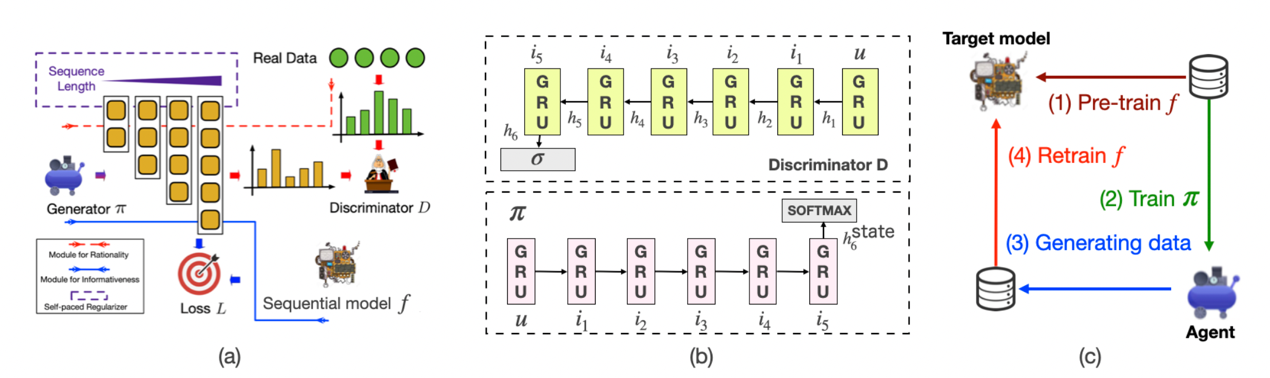
论文介绍
论文题目:Learning Probabilistic Box Embeddings for Effective and Efficient Ranking
作者:梅朗,毛佳昕,郭港,文继荣
通讯作者:毛佳昕
论文概述:排序作为信息检索中最重要的任务之一。随着深度表示学习的发展,已有研究提出将查询和文档都编码为向量,并根据向量空间中的内积或距离度量得分进行排序。然而,基于向量的排序模型在有效性和效率方面存在不足。在有效性上,它们缺乏内在的模拟排序任务中查询和文档的多样性和不确定性能力。在效率上,对大规模文档向量集合中执行最近邻搜索可能较为耗时。在本文工作中,我们利用近期提出的probabilitic box embedding进行有效和高效率的排序,其中查询和文档被参数化为高维轴对齐超矩形。在提高有效性上,我们利用box embedding对应的超矩形之间的重叠关系来建模多样性和不确定性,并证明这种重叠度量是一种核函数,可用于其他基于核的方法。在提高检索效率上,我们提出了一种基于box embedding的索引方法,该方法可以安全地过滤无关的文档,从而减少检索延迟。我们进一步设计了一种训练策略,有效的增加了检索过程中可过滤的不相关文档的比例。在公开数据集上的实验表明,box embedding和基于box embedding的索引在文档检索和商品推荐两个任务上取得了较好的排序性能和检索效率。
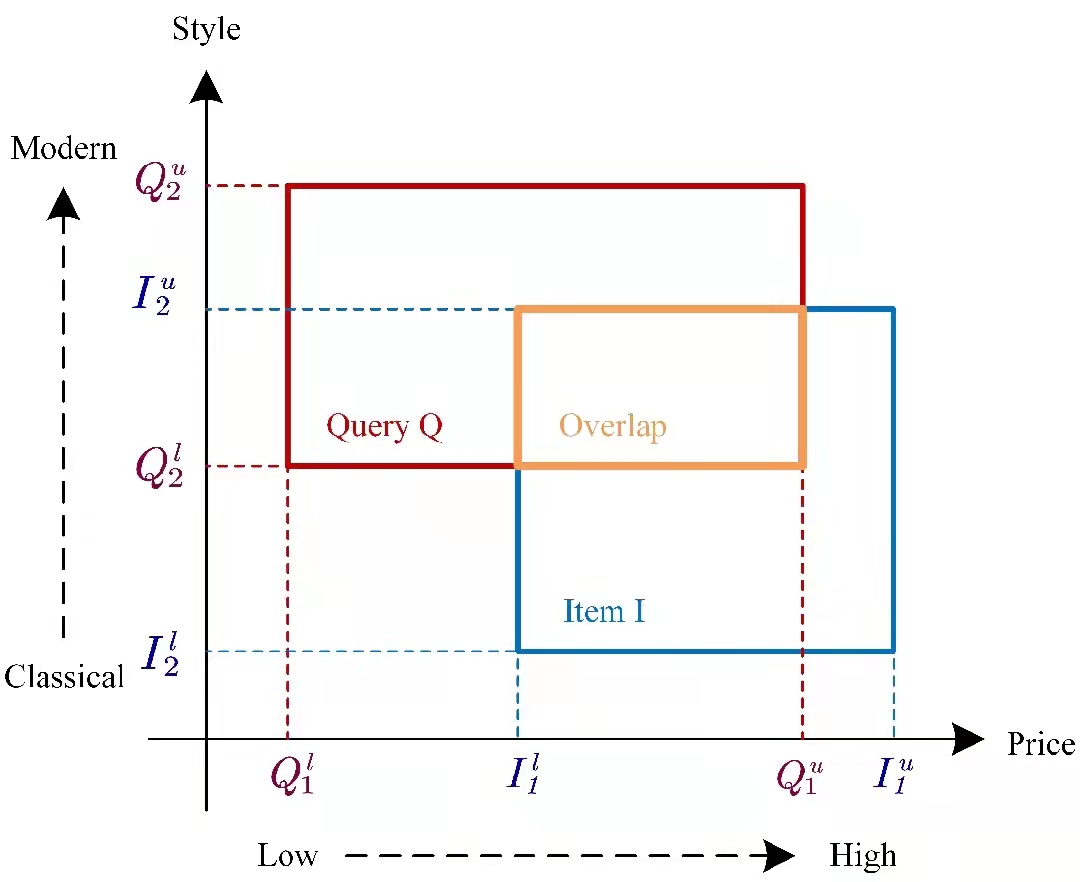
论文介绍
论文题目:Global or Local: Constructing Personalized Click Models for Web Search
作者:张俊祺,刘奕群,毛佳昕,谢晓晖,张敏,马少平
论文概述:点击模型被广泛的应用于获取相关性反馈、模拟用户行为、评价搜索引擎新能等任务中。大多数现有点击模型均假设用户的行为模式和相关性判断标准是同质化。然而,已有工作表明不同用户与搜索引擎的交互方式之间存在较大差异。因此,一个基于用户同质化假设的统一的点击模型很难建模用户异质化的点击行为。为了解决这个问题,我们提出了一个点击模型个性化框架(Click Model Personalization framework,简称CMP)。该框架可以在点击模型预测时自适应的选择建模整个用户群体的全局模型和建模单个用户的局部模型。在该框架下,我们设计了不同的自适应选择策略来进行个性化点击预测。
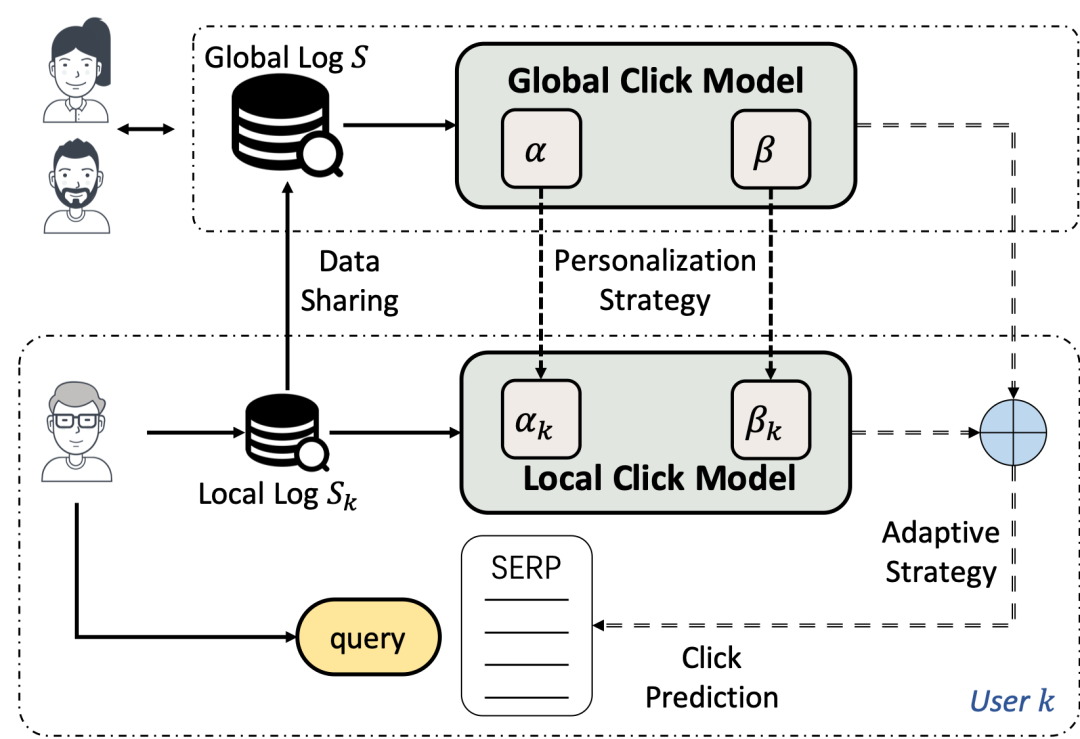
图:个性化点击模型Click Model Personalization (CMP)框架
为了验证个性化点击模型和CMP框架的有效性,我们构建了一个包含1,249个用户在六个月内点击记录的个性化点击日志。在该数据集上的实验表明CMP框架下构建的个性化点击模型可以在点击预测方面取得相交传统非个性化点击模型显著的性能提升。实验结果还表明,较于建模用户个性化的相关性判断,建模用户个性化的行为模式对提升点击预测性能更为重要。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox