学院新闻
我院师生论文被CCF A类会议SIGIR录用
日期:2022-04-04访问量:2022年3月31日,中国计算机学会(CCF)推荐的A类国际学术会议SIGIR 2022论文接收结果公布。中国人民大学高瓴人工智能学院师生有10篇论文(其中8篇长文、2篇短文)被录用。SIGIR是人工智能领域智能信息检索方向最权威的顶级国际会议,也是中国人民大学A+类学术会议。第45届国际计算机学会信息检索大会(The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2022)将于2022年7月11日-15日在西班牙马德里召开,同时支持线上参会。本次会议共收到794篇长文投稿,仅有161篇被录用,长文录用率为20%。
论文介绍
论文题目: Curriculum Contrastive Context Denoising for Few-shot Conversational Dense Retrieval
作者:毛科龙,窦志成,钱泓锦
通讯作者:窦志成
论文概述:对话式搜索是信息检索领域一个重要且有潜力的研究分支。在本文中,我们揭示了并不是所有的历史轮次对于理解当前的用户查询意图都是必需的。对话上下文中的冗余噪声轮次极大地限制了对话式搜索模型的性能。然而,由于对话式搜索数据的缺乏,以及模型需要同时学习对话式查询编码,增强对话式搜索模型的上下文去噪能力是相当具有挑战性的。为了解决这些问题,本文针对少样本情况下的对话式稠密检索问题,提出了一种新的基于课程对比学习的上下文去噪框架(名为COTED)。在COTED中,我们提出了一种新的对话式数据增强策略来得到大量的有噪样本。随后,基于课程学习的思想,我们由易到难逐步地,通过有噪样本和无噪样本之间的对比学习,来增强对话式稠密检索模型的上下文去噪能力。我们同时探索了三种用于对话式搜索的课程学习策略。我们在CAsT-19和CAsT-20这两个少样本对话式搜索数据集上进行了大量实验,验证了我们的方法与最先进的基线相比的有效性和优越性。
论文介绍
论文题目:Webformer: Pre-training with Web Pages for Information Retrieval
作者:郭宇,毛佳昕,钱泓锦,张鑫宇,蒋昊,曹朝,窦志成
通讯作者:窦志成
论文概述:预训练语言模型在信息检索领域取得了巨大的成功。研究表明,将这些模型应用于 ad-hoc 文档排序可以实现更好的检索效果。但是,在 Web 上,大多数信息是以 HTML 网页的形式组织的。除了纯文本内容,HTML标签组织的内容结构也是网页传递信息的重要组成部分。目前,仅基于文本内容训练的预训练模型完全忽略了此类结构化信息。在本文中,我们提出利用大型网页及其 DOM树结构来预训练模型以进行检索。我们认为,使用网页中包含的层次结构,我们可以获得更丰富的上下文信息来训练更好的语言模型。为了利用这种信息,我们根据网页结构设计了四种不同的预训练优化目标,结合传统的MLM任务重新训练一个 Transformer 模型Webformer。在两个权威的 ad-hoc 检索数据集上的实验结果证明,与现有的预训练模型相比,我们的模型可以显著提高搜索性能。
论文介绍
论文题目:Generating Clarifying Questions with Web Search Results
作者:赵梓良,窦志成,毛佳昕,文继荣
通讯作者:窦志成
论文概述:在对话式搜索系统中,提问澄清问题是有效澄清用户意图的一种互动方式。当用户向搜索引擎提交查询时,用户将收到一个澄清问题以及多个可供单击的子意图项。根据现有定义,提出高质量澄清问题的关键是为提交的查询和提供子意图项生成良好的描述。然而,现有的主要基于知识库的方法很难找到许多查询或子意图项的描述,因为这些查询及其子意图项中不包含知识库中的实体。对于这种查询,它无法生成信息丰富的澄清问题。为了缓解这个问题,我们提出利用搜索引擎返回的搜索结果来帮助生成更好的描述,因为搜索结果包含丰富的上下文和相关信息。具体来说,我们首先设计了一种基于规则的算法,从搜索结果中提取候选描述,并根据多种人工设计的特征对它们进行排序。然后,我们进一步提出了一种用于排序的集成学习模型,以及另一种生成模型,在基于规则的模型的基础上学习候选描述的排序或生成,进一步提高了问题澄清的质量。所有方法都利用了Bing搜索引擎检索到的结果中包含的丰富网络信息。实验结果表明,与现有方法相比,本文提出的方法可以生成更具可读性和信息量的澄清问题。因此,搜索结果对搜索澄清非常重要,可以用来改善对话式搜索系统中用户的搜索体验。
论文介绍
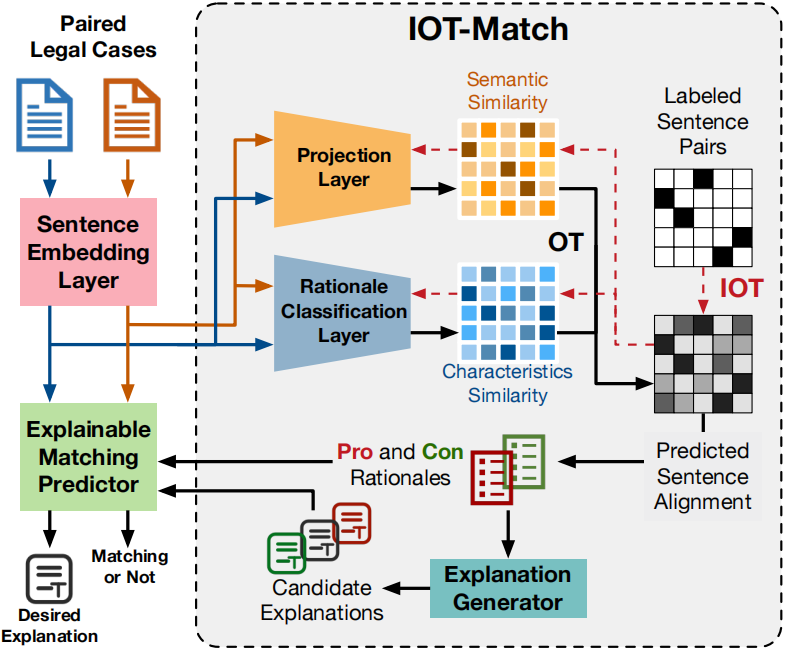
论文题目:Explainable Legal Case Matching via Inverse Optimal Transport-based Rationale Extraction
作者:俞蔚捷,孙忠祥,徐君,董振华,陈旭,许洪腾,文继荣
通讯作者:徐君
论文概述:作为法律检索的一项基本操作,法律案例匹配在智能法律系统中起着核心作用。该任务对匹配结果的可解释性有很高的要求,因为它对下游应用有着至关重要的影响——匹配的法律案件可能为目标案件的判决提供支持性证据,从而影响法律判决的公平和公正。针对这一具有挑战性的任务,我们提出了一种新颖的、可解释的方法——IOT-Match。它借助于最优运输,将法律案件匹配问题建模为逆向最优运输(IOT)问题。与仅仅关注法律案件之间句子层面语义相似性的大多数现有方法不同的是,IOT-Match 学习根据句子的语义和法律属性从成对的法律案例中提取预测依据。提取的依据被进一步应用于生成忠实于预测的自然语言解释并进行匹配。此外, IOT-Match对实际法律案例匹配任务中句子对齐标签不充分问题具有鲁棒性,适用于监督和半监督的学习范式。为了证明IOT-Match的优越性,并构建一个可解释法律案例匹配任务的基准,我们不仅扩展了著名的CAIL数据集,还建立了一个新的可解释法律案例匹配(ELAM)数据集,其中包含大量具有详细可解释注释的法律案例。在这两个数据集上的实验表明,IOT-Match在匹配预测、依据提取和解释生成方面均优于目前最优方法。
论文介绍
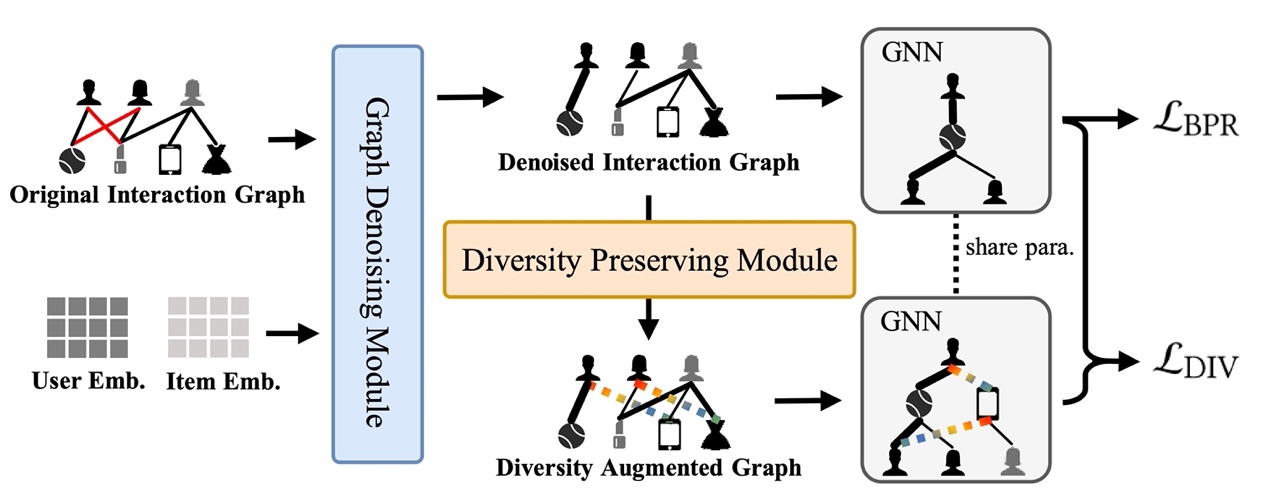
论文题目:Learning to Denoise Unreliable Interactions for Graph Collaborative Filtering
作者:田长鑫,谢悦湘,李雅亮,杨楠,赵鑫
通讯作者:赵鑫
论文概述:近年来,图神经网络(GNN)被成功地应用于协同过滤(CF)推荐系统。然而,用户交互数据中的噪声严重影响了基于GNN的CF模型的有效性和鲁棒性,且目前对推荐系统去噪的研究要么忽视了GNN消息传播机制对噪声的扩散,要么在去噪时未能保持推荐的多样性。为解决上述问题,本文提出了一种新的基于GNN的CF模型RGCF (Robust Graph Collaborative Filtering),用于去除不可靠的交互以提升推荐效果。RGCF由图去噪模块和多样性保持模块组成。图去噪模块采用硬去噪和软去噪策略,来减少噪声交互对GNN表示学习的影响。多样性保持模块建立多样性增广图,借助辅助的自监督任务增强推荐的去噪表示并保持推荐的多样性。这两个模块以多任务学习的方式集成在一起,共同提高模型的推荐性能。我们在三个真实的推荐数据集和三个合成数据集上进行了一系列的实验,证明了所提出的方法的有效性。
论文介绍
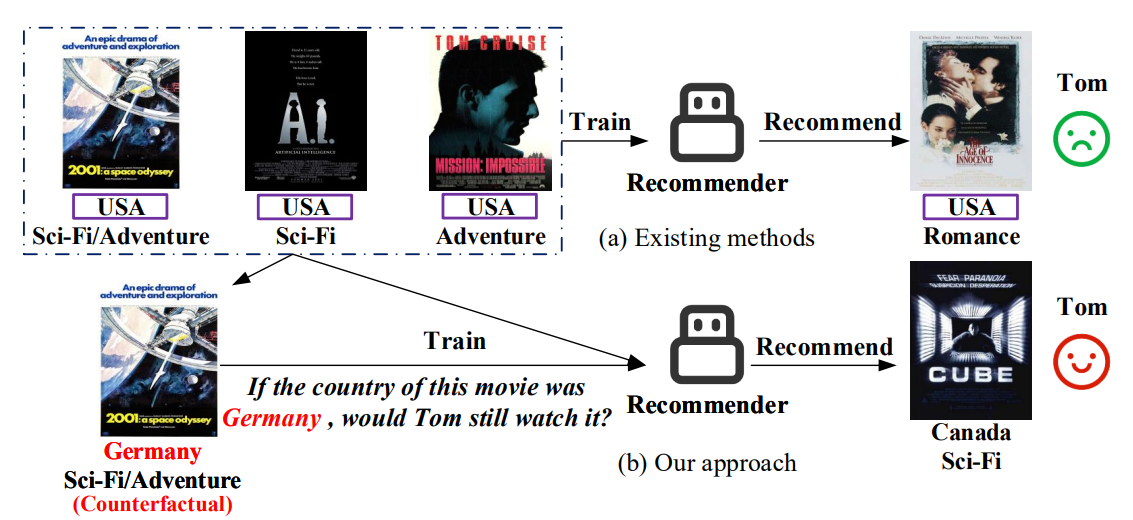
论文题目:Alleviating Spurious Correlations in Knowledge-aware Recommendations through Counterfactual Generator.
作者:牟善磊,李雅亮,赵鑫,王静远,丁博麟,文继荣
通讯作者:赵鑫
论文概述:受限于基于统计的机器学习框架,现有的知识感知推荐算法广泛地受到虚假相关关系的影响。它指的是一个知识实体看起来与用户行为存在因果关系,但实际上并非如此。为了解决这个问题,我们提出了一种从反事实的角度发现和减轻潜在虚假相关性的新方法。具体来说,我们的方法由两个反事实生成器和一个推荐器组成。反事实生成器旨在通过强化学习生成反事实交互数据,而推荐器使用两个不同的图神经网络实现,以分别聚合来自知识图谱数据和推荐交互数据的信息。反事实生成器和推荐器以相互协作的方式集成。通过这种方法,推荐器帮助反事实生成器更好地识别潜在的虚假相关并生成高质量的反事实交互,而反事实生成器生成的反事实交互帮助推荐器削弱潜在虚假相关的影响。与大量基线方法比较,在三个真实世界数据集的广泛实验证明了所提出方法的有效性。
论文介绍
论文题目:Ada-Ranker: A Data Distribution Adaptive Ranking Paradigm for Sequential Recommendations
作者:范欣妍,练建勋,赵鑫,刘政,李朝卓,谢幸,文继荣
通讯作者:赵鑫
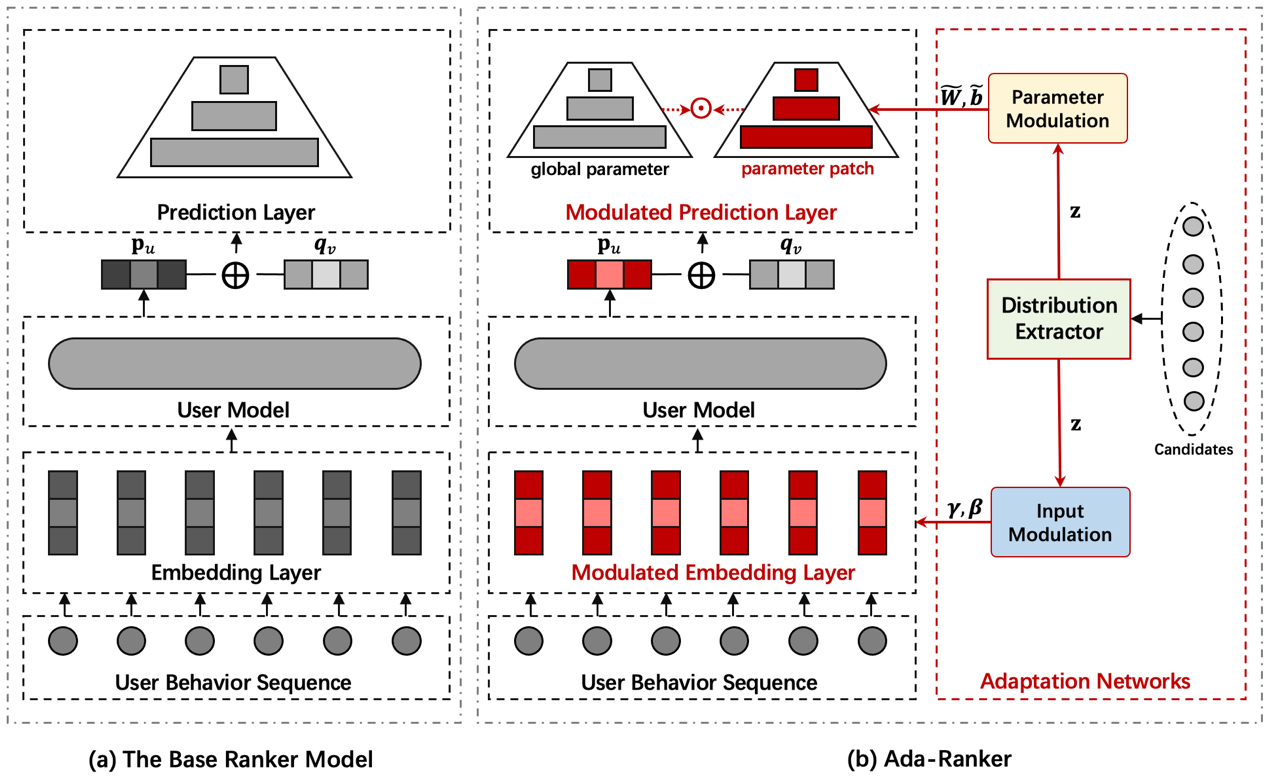
论文概述:大规模推荐系统通常由召回(recall)和排序(rank)两个模块组成。排序模型的目标是仔细区分用户对召回模块提出的候选物品集的偏好。随着深度学习的发展,主流排序模型从传统模型发展到深度神经网络模型。然而,我们在排序模型中使用的方式一直保持不变:离线训练模型 -> 冻结参数 -> 部署在线服务。实际上,候选集是由特定的用户请求决定的,在真实环境中,这些请求的底层分布彼此之间存在很大差异。经典的参数冻结推理方式无法适应动态服务环境,使排序模型的性能受到很大影响。
在本文中,我们提出了一种新的训练和推理范式,称为Ada-Ranker,以应对动态在线服务的挑战。Ada-Ranker是一个模型无关的方法,可以根据当前候选集的数据分布自适应地调整排序模型的参数,而不是使用参数冻结模型进行通用的服务。我们首先会针对候选集进行分布学习,从中提取一个分布偏置向量。然后,我们用分布偏置向量对排序模型进行调制,使排序模型自适应到当前的数据分布。最后,我们使用修改后的排序模型对候选物品进行评分。通过这种方式,我们赋予排序模型从全局(global)模型到局部(local)模型的适应能力,从而更好地处理当前任务。作为第一步的研究,我们研究了序列化推荐场景中的Ada-Ranker范式。在三个数据集上的实验表明,Ada-Ranker可以有效地增强各种类型的基础排序模型,并且优于其他基线方法。
论文介绍
论文题目:CORE: Simple and Effective Session-based Recommendation within Consistent Representation Space (短文)
作者:侯宇蓬,胡斌斌,张志强,赵鑫
通讯作者:赵鑫
论文概述:Session-based Recommendation是指基于匿名会话中的短期用户行为给出下一个商品的预测。然而,由非线性编码器编码的会话嵌入表示通常与商品嵌入表示不在同一表示空间中,导致在推荐商品时出现预测不一致问题。在这项工作中,我们旨在统一会话推荐中整个编码和解码过程的表示空间,并提出一个简单有效的框架 CORE。首先,我们提出了一种表示一致的编码器,将匿名会话中商品嵌入表示的线性组合作为会话嵌入,保证会话和商品在同一个表示空间中。此外,我们提出了一种鲁棒的距离测量方法,以防止嵌入在一致表示空间中的过拟合。在五个公开的真实世界数据集上进行的实验证明了所提出方法的有效性和高效性。
论文介绍
论文题目:Conversational Recommendation via Hierarchical Information Modeling(短文)
作者:涂权,高莘,李嫣然,崔建伟,王斌,严睿
通讯作者:严睿
论文概述:对话式推荐系统通过直接询问用户对于商品属性的偏好或直接给出推荐商品列表来为用户推荐合适的商品。然而,现有的大多数方法只使用了商品及其属性之间的关系,而忽视了由相似用户链接起来的层次关系可以提供更全面的信息。此外,这些方法只使用当前轮次用户接受的商品属性、拒绝的商品属性以及拒绝的商品来表示对话历史,却并没有建模不同轮次之间的层次关系。在本文中,我们提出了层次信息注意的对话式推荐系统,通过建模这两类层次关系来提升对话式推荐系统的表现。在四个基准数据集上的实验验证了我们所提出方法的有效性。
论文介绍
论文题目:Axiomatically Regularized Pre-training for Ad hoc Search
作者:陈佳,刘奕群,方言,毛佳昕,方辉,杨圣豪,谢晓晖,张敏,马少平
论文概述:近年来,预训练语言模型被广泛应用于信息检索和文档排序任务上。然而,由于预训练语言模型结构和包含预训练和微调两个阶段的训练过程较为复杂,我们很难了解模型在预训练过程中学习到了哪些对于文档排序有用的知识。因此,基于预训练语言模型在该任务中是一个缺乏可解释性的黑盒。为了解决上述问题,提升排序模型的鲁棒性和可解释性,我们尝试将IR公理引入到模型的预训练过程中。通过对已有工作中提出的IR公理进行归纳、总结和修改,我们选取了适合进行预训练的IR公理,并提出了一个名为ARES的预训练框架。在多个公开数据集上的实验结果表明ARES框架在训练检索模型方面的有效性。相较于现有方法,ARES框架在低资源场景(Few-shot和Zero-shot)下能取得更为明显的性能提升。在zero-shot场景下进行的可视化分析进一步显式了ARES模型能够有效的学习通过IR公理引入的排序规则。
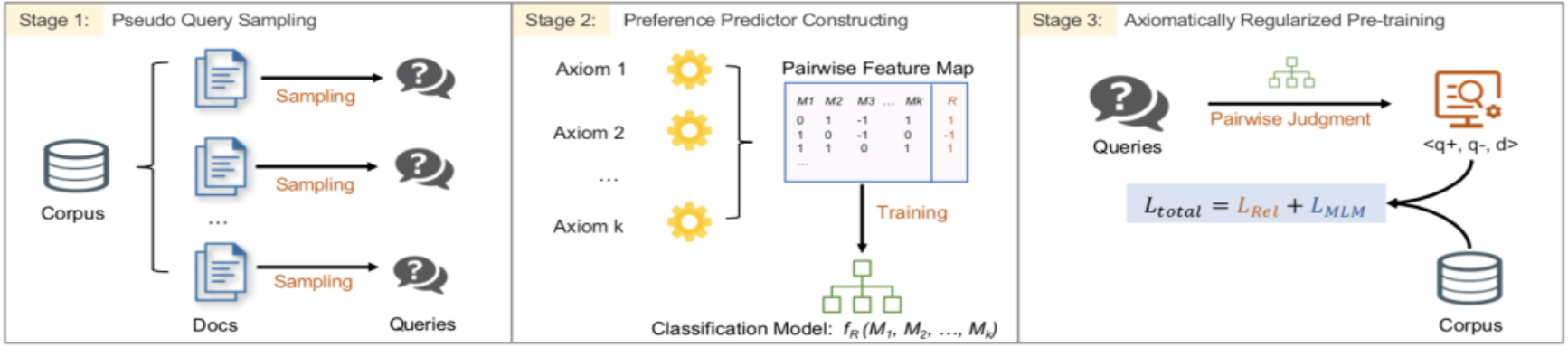
图: ARES框架示意图
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox