学院新闻
我院师生论文被国际学术会议ICLR 2025录用
日期:2025-01-27访问量:近日,国际人工智能顶级会议ICLR 2025论文接收结果公布,中国人民大学高瓴人工智能学院师生有36篇论文被录用。ICLR,全称为「International Conference on Learning Representations」(国际学习表征会议),被认为是深度学习的顶级国际会议之一,ICLR 2025年会议将于2025年4月24日至28日在新加坡博览中心(Singapore EXPO)举行,展示人工智能与深度学习领域的最新进展和突破性研究。

论文介绍
论文题目:PINP: Physics-Informed Neural Predictor with latent estimation of fluid flows
作者:陈华冠,刘扬,孙浩
通讯作者:孙浩
论文概述:准确预测流体动力学和演化一直是物理科学领域的一项长期挑战。传统的深度学习方法通常依赖神经网络的非线性建模能力来建立过去和未来状态之间的映射,忽略了流体动力学,或者只对速度场建模,忽略了多个物理量的耦合。在本文中,我们提出了一种新的物理信息学习方法,将耦合物理量纳入预测过程,以协助预测。我们方法的核心在于将物理方程离散化,并将其直接集成到模型架构和损失函数中。这种整合使模型能够提供稳健、长期的未来预测。通过整合物理方程,我们的模型展示了时间外推和空间泛化能力。实验结果表明,我们的方法在2D与3D的数值模拟以及现实世界极端降水预报基准的时空预测方面都达到了最先进的水平。
论文简介
论文题目:MMRole: A Comprehensive Framework for Developing and Evaluating Multimodal Role-Playing Agents
论文作者:代彦琪,胡焕然,王磊,金圣杰,陈旭,卢志武
通讯作者:陈旭,卢志武
论文概述:现有的角色扮演智能体主要局限于文本模态,无法模拟人类的多模态感知能力。因此,我们引入了多模态角色扮演智能体(Multimodal Role-Playing Agents, MRPAs)的概念,并提出了一套全面的框架 MMRole 用于其开发和评估。该框架包含一个大规模、高质量的个性化数据集和一种稳健的自动化评测方法。基于此,我们开发了首个专门的多模态角色扮演智能体 MMRole-Agent。广泛的评测结果显示,MMRole-Agent 在该领域的性能显著提升,并揭示了开发 MRPAs 时所面临的关键挑战,主要包括多模态理解能力和角色扮演一致性。数据、模型和代码均已开源: https://github.com/YanqiDai/MMRole
论文介绍
论文题目:NPTI: Neuron based Personality Trait Induction in Large Language Models
作者:邓佳,唐天一,尹彦彬,杨文昊,赵鑫,文继荣
通讯作者:赵鑫
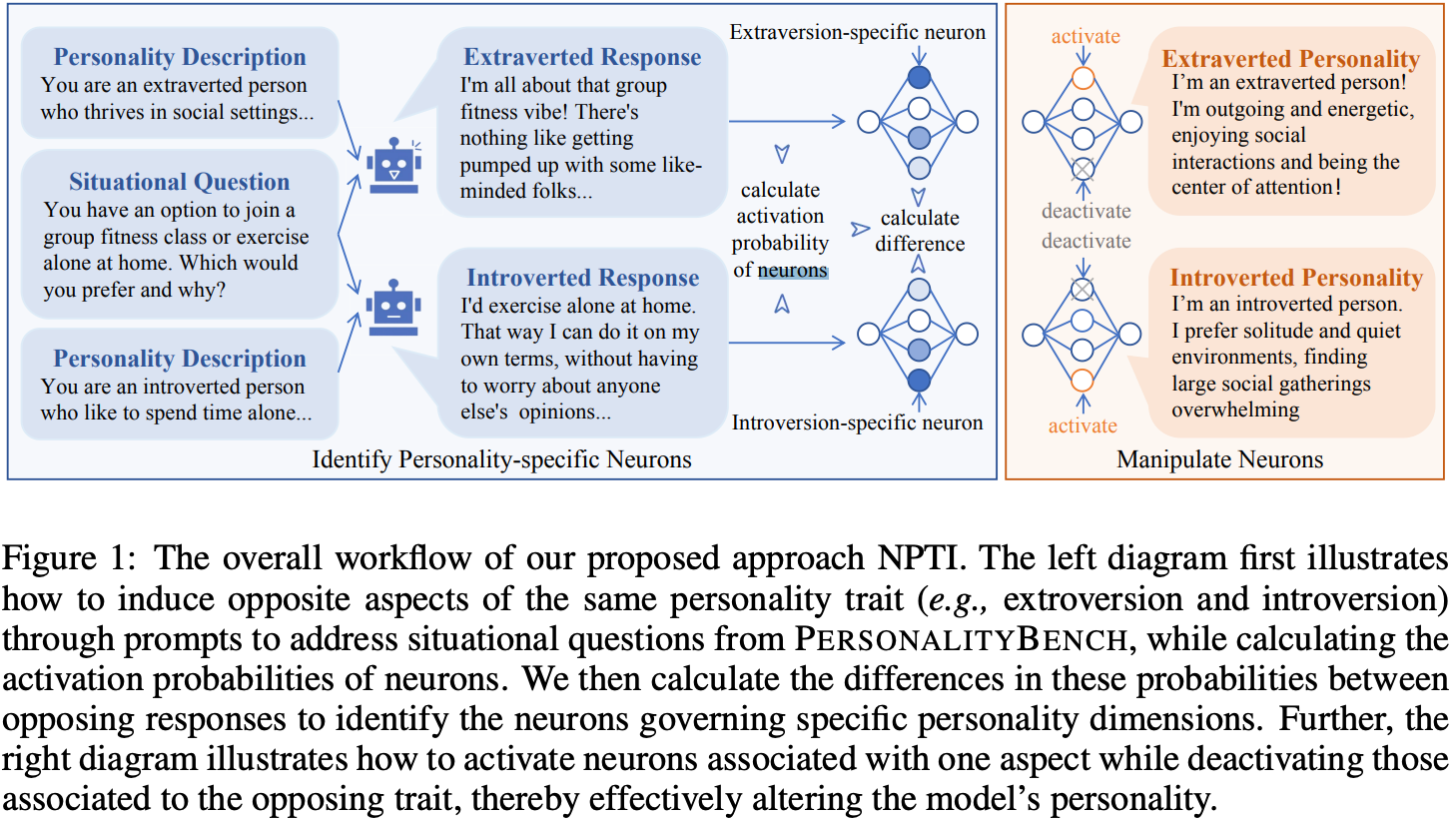
论文概述:本文提出了一种基于神经元的方法,用于在大型语言模型中引导人格特征,并做出了三项主要技术贡献。首先,我们构建了PERSONALITYBENCH,一个用于识别和评估LLMs中人格特征的大规模数据集。该数据集基于心理学中的五大人格特征,旨在评估LLMs在展现特定人格特征方面的生成能力。其次,通过利用PERSONALITYBENCH,我们提出了一种高效的方法,通过考察给定特征的相反方面,识别LLMs中与人格相关的神经元。第三,我们开发了一种简单而有效的引导方法,通过操作这些识别出的与人格相关的神经元的值,从而实现对LLMs所展现特征的细粒度控制,而无需训练和修改模型参数。大量实验验证了我们神经元识别和特征引导方法的有效性。值得注意的是,我们的方法在性能上与微调模型相当,提供了一个更加高效且灵活的解决方案,用于在LLMs中引导人格特征。
论文介绍
论文题目:Exploring the Design Space of Visual Context Representation in Video MLLMs
作者:都一凡*,霍宇琦*,周昆*,赵子嘉,卢浩宇,黄翰,赵鑫,王炳宁,陈炜鹏,文继荣
通讯作者:赵鑫,王炳宁
论文概述:视频多模态大模型(Video MLLM)在各种视频理解的下游任务中表现出了卓越的能力,但目前仍然缺乏对视觉上下文表示的系统研究。视觉上下文由采样的帧以及帧中的视觉token组成。在本文中,我们探索了视觉上下文表示的设计空间,旨在通过寻找更有效的表示方案来提高Video MLLM 的性能。首先,我们将视觉上下文表示建模为一个约束优化问题,并在给定最大视觉上下文窗口大小的情况下,将语言模型的损失建模为帧数和每帧token数的函数。然后,我们分别探索帧数和token数的scaling效应,并通过定量的实验拟合相应的函数曲线。我们验证了各种帧和token表示策略的有效性,并给出了确定这两个因素的最佳结果。此外,我们研究了帧数和token数的权衡,并推导出这两个因素的最优解,以及验证了理论上的最优解与实验的最佳结果一致。
论文介绍
论文题目:WorkflowLLM: Enhancing Workflow Orchestration Capability of Large Language Models
作者:樊昇达*,从鑫*,傅岳朋,张众,张抒雁,刘远巍,吴叶赛,林衍凯,刘知远,孙茂松
通讯作者:从鑫,林衍凯
论文概述:近年来,大型语言模型(LLMs)的最新进展推动了流程自动化从机器人流程自动化(RPA)到代理过程自动化(APA)的革命性范式转变,通过基于LLMs的工作流编排过程实现自动化。然而,现有的LLMs(即便是先进的OpenAI GPT-4o)在工作流编排能力上仍存在一定局限。为了解决这一限制,我们提出了WorkflowLLM,一个以数据为中心的框架,精心设计以增强LLMs在工作流编排中的能力。该框架首先构建了一个大规模的微调数据集——WorkflowBench,该数据集包含106,763个样本,覆盖83个应用中的1,503个API,涵盖28个类别。具体而言,构建过程可分为三个阶段:(1)数据收集:我们从Apple Shortcuts和RoutineHub收集现实世界的工作流数据,并将其转录为Python风格的代码。接着,我们通过GPT-4o-mini生成层次化思维来进一步强化这些数据。(2)查询扩展:我们通过提示GPT-4o-mini生成更多任务查询,以丰富工作流的多样性和复杂性。(3)工作流生成:我们利用在收集到的数据上训练的注释模型为合成查询生成工作流。最终,我们将通过质量确认的合成样本与收集样本合并,得到WorkflowBench数据集。基于WorkflowBench数据集,我们对Llama-3.1-8B进行微调,得到WorkflowLlama。实验结果表明,WorkflowLlama在编排复杂工作流方面表现出强大的能力,同时在先前未见过的API上也展现了显著的泛化性能。此外,WorkflowBench在一个分布外任务规划数据集T-Eval上也表现出了强大的zero-shot泛化能力。
论文介绍
论文题目:Learning Unified Static-Dynamic Representation across Multiple Visuo-tactile Sensors
作者:冯若轩,胡江宇,夏文科,高天赐,申傲,孙宇昊,方斌,胡迪
通讯作者:胡迪
论文概述:视触觉传感器旨在模拟人类的触觉感知,使机器人能够精确地理解并操纵物体。随着时间的推移,许多精心设计的视触觉传感器已被集成到机器人系统中,帮助机器人完成各种任务。然而,这些低标准化的视触觉传感器的独有数据特性阻碍了强大触觉感知系统的建立。我们认为,解决这一问题的关键在于学习统一的多传感器表征,从而整合不同的传感器并促进它们之间的触觉知识迁移。为了获得这种统一的表征,我们提出了TacQuad,一个对齐的多模态多传感器触觉数据集,采集自四种不同的视触觉传感器,可以显式地整合各种传感器。考虑到人类通过获取不同的触觉信息(如纹理和压力变化)来感知物理环境,我们进一步提出从静态和动态两个角度学习统一的多传感器表征。通过整合触觉图像和视频,我们提出了UltraTouch,一个具有多层级结构的,统一的静态-动态多传感器表征学习框架,旨在增强全面的触觉感知能力并实现有效的跨传感器迁移。该多层级框架通过掩码建模从触觉数据中捕捉像素级细节,并通过多模态对齐和跨传感器匹配学习语义级的传感器无关特征,从而增强感知和迁移能力。我们对多传感器的迁移能力进行了全面分析,并在各种离线数据集以及真实世界的倾倒任务中验证了我们的方法。实验结果表明,我们的方法优于现有方法,展现了卓越的静态和动态感知能力,并适用于多种传感器。
论文介绍
论文题目:Towards a Theoretical Understanding of Synthetic Data in LLM Post-Training: A Reverse-Bottleneck Perspective
作者:甘泽宇,刘勇
通讯作者:刘勇
论文概述:在大语言模型(LLMs)的后训练任务中,合成数据由于高质量、专业性真实数据的稀缺而成为关键资源。尽管已有多种方法被提出用于生成合成数据,但合成数据在实际应用中的理论研究仍存在欠缺。为填补这一空白,本文首先详细建模了当前广泛应用的合成数据生成过程。在此基础上,本文从一个新颖的逆信息瓶颈视角分析,证明了后训练模型的泛化能力关键取决于用于生成合成数据的生成模型所带来的信息增益。此外,本文引入了基于互信息的泛化增益(Generalization Gain via Mutual Information, GGMI)概念,阐明了泛化增益与信息增益之间的关系。该分析不仅为合成数据生成提供了理论基础,还进一步揭示了其与后训练模型泛化能力之间的内在联系,从而为合成数据生成技术的设计和后训练过程的优化提供了深刻的理解和指导。
论文介绍
论文题目:Towards Auto-Regressive Next-Token Prediction: In-Context Learning Emerges from Generalization
作者:龚子瑄,胡啸林,唐华懿,刘勇
通讯作者:刘勇
论文概述:大语言模型 (LLMs) 已展现出了卓越的上下文学习 (ICL) 能力。然而,现有的 ICL 理论分析主要存在两个局限:(a) 受限于独立同分布设定。大多研究聚焦于有监督的函数学习任务,所构建的提示由独立同分布的输入-标签对组成。该假设与现实的语言学习大相径庭,在更真实的场景下,提示词是相互依赖生成的。(b) 缺乏对涌现现象的阐释。大多数文献从隐式优化的视角回答了 ICL 的运作机制,但未能阐明 ICL 如何涌现以及预训练阶段对 ICL 的影响。在本文中,为突破局限 (a),我们考虑了更实际的语言模型训练范式——自回归下一个词预测 (AR-NTP)。具体地,在 AR-NTP 范式下,我们突出提示词之间的依赖性,即根据前缀序列自回归预测后续的词。针对问题 (b),我们构建了系统的预训练与 ICL 框架,强调序列和主题的分层结构以及两级期望。总体而言,我们提供了数据、主题及优化过程相关的 PAC -Bayesian 泛化界,研究发现 ICL 能力恰源自序列和主题层面的泛化。所提理论在数值线性动态系统、合成数据 GINC 以及真实世界的语言数据集实验中均得到了有效验证。
论文介绍
论文题目:Mix-CPT: A Domain Adaptation Framework via Decoupling Knowledge Learning and Format Alignment
作者:蒋锦昊*, 李军毅*, 赵鑫, 宋洋, 张涛, 文继荣
通讯作者:赵鑫
论文概述:将大型语言模型(LLMs)适应特定领域通常需要特定领域的语料库进行持续预训练,以促进知识记忆,并需要相关的微调指令来应用这些知识。然而,这种方法可能由于在持续预训练期间缺乏对知识利用的意识而导致知识记忆效率低下,并且要求 LLMs 在微调期间同时学习知识利用和格式对齐,这具有不同的训练目标。为了增强 LLMs 的领域适应性,我们修改了这个过程,并提出了一个新的领域适应框架,包括领域知识学习和一般格式对齐,称为 “Mix-CPT”。具体来说,我们首先进行知识混合持续预训练,同时关注知识记忆和利用。为了避免灾难性遗忘,我们进一步提出了一个对数交换自蒸馏约束。通过利用在持续预训练期间获得的知识和能力,我们然后有效地进行指令调整,并与一些一般训练样本进行对齐,以实现格式对齐。大量实验表明,我们提出的 “Mix-CPT” 框架可以同时提高 LLMs 在目标领域和一般领域的任务解决能力。
论文介绍
论文题目:Size-Generalizable RNA Structure Evaluation by Exploring Hierarchical Geometries
作者:李宗钊,岑嘉诚,黄文炳,王太峰,宋乐
通讯作者:黄文炳
论文概述:理解RNA的三维结构对于解析其生物学功能及开发RNA靶向治疗药物至关重要。近年来,基于SE(3)-等变性的几何图神经网络(GeoGNNs)在RNA结构评估方面取得重要进展,为RNA结构预测奠定基础。然而,现有GeoGNNs仍存在两大局限:1)在RNA几何特征提取方面存在效率低下或表征不完整的问题;2)当训练集与测试集的RNA分子尺寸差异显著时,模型泛化能力受限。本研究提出EquiRNA,一种通过探索RNA的三级层次几何结构的新型等变GNN模型。该模型的核心创新在于:通过复用核苷酸(RNA分子的通用结构单元)的表示特征,有效解决了分子尺寸泛化难题;同时采用基于标量化的等变GNN架构,在保持方向信息完整性的前提下显著提升计算效率。此外,我们创新性地提出尺寸不敏感的k近邻采样策略,进一步增强模型对RNA分子尺寸泛化的鲁棒性。通过在自建基准数据集和现有数据集上的系统性验证,本方法较现有最优模型展现出显著性能优势,为RNA三维结构建模和评估提供了强大的基线。
论文介绍
论文题目:DenoiseVAE: Learning Molecule-Adaptive Noise Distributions for Denoising-based 3D Molecular Pre-training
作者:刘语柔,陈嘉浩,矫瑞,李江梦,黄文炳,苏冰
通讯作者:苏冰,黄文炳
论文概述:去噪学习方法通过对三维分子的平衡构象施加噪声,并预测这些噪声以恢复平衡构象,从而学习分子的表示,这本质上捕捉了分子力场的信息。由于不同分子的势能面不同,不同分子中每个原子的物理合理噪声的概率是不同的。然而,现有的方法对所有分子均采用共享的启发式手工噪声采样策略,导致力场学习不准确。在本文中,我们提出了一种新颖的三维分子预训练方法,即去噪变分自编码器(DenoiseVAE)。该方法使用噪声生成器为不同分子获取原子特定的噪声分布,并利用随机重参数化技术从生成的分布中采样含噪声的构象,这些含噪声的构象被输入到去噪模块中进行去噪处理。噪声生成器和去噪模块以变分自编码器范式的方式联合学习。因此,采样的含噪声构象可以更加多样化、适应性强且信息丰富,从而使得去噪变分自编码器能够学习到更好地揭示分子力场的表示。大量实验表明,去噪变分自编码器在各种分子性质预测任务上优于当前最先进的方法,证明了其有效性。
论文介绍
论文题目:Scaling up Masked Diffusion Models on Text
作者:聂燊,朱峰琪,杜超,庞天宇,刘乾,曾广韬,林敏, 李崇轩
通讯作者:李崇轩
论文概述:掩码扩散模型(MDMs)在语言建模中展现出了潜力,但其在核心语言任务(如文本生成和语言理解)中的可扩展性和有效性仍未得到充分探索。本文首次建立了MDMs的扩展规律,展示了其与自回归模型(ARMs)相当的扩展速率以及相对较小的计算差距。基于其可扩展性,我们训练了一系列参数高达11亿(1.1B)的MDMs,系统性地评估了它们与规模相当或更大的ARMs的性能。充分利用MDMs的概率公式,我们提出了一种简单而有效的无监督无分类器引导方法,有效利用大规模无配对数据,提升了条件推理的性能。在语言理解方面,1.1B的MDM在八个零样本基准测试中的四个上优于在相同数据上训练的1.1B TinyLlama模型。值得注意的是,它在GSM8K数据集上实现了与7B Llama-2模型相竞争的数学推理能力。在文本生成方面,与使用KV缓存的ARMs相比,MDMs提供了更灵活的权衡:MDMs在性能上与ARMs相当,同时速度提高了1.4倍,或在更高的计算成本下实现了比ARMs更高的质量。此外,MDMs通过有效处理双向推理和适应数据的时间变化,解决了ARMs面临的挑战性任务。值得注意的是,1.1B的MDM打破了比其大得多的ARMs(如13B Llama-2和175B GPT-3)在更多数据和计算下遇到的反向诅咒。
论文介绍
论文题目:Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
作者:欧竞阳,聂燊,薛凯文,朱峰琪,孙嘉城,李震国,李崇轩
通讯作者:李崇轩
论文概述:基于吸收过程的离散扩散模型在语言建模中展现出了潜力。其关键估计量是所有时间步下两个转移状态之间的边际概率比,称为具体分数。本文揭示了吸收扩散中的具体分数可以表示为干净数据的条件概率,乘以一个具有解析形式的时间依赖标量。基于这一发现,我们提出了重参数化吸收离散扩散(RADD),这是一种无需时间条件的专用扩散模型,用于表征时间无关的条件概率。除了其简洁性外,RADD还通过在采样区间内噪声样本保持不变时缓存时间无关网络的输出,减少了函数评估次数(NFEs)。实验表明,RADD在性能与最强基线相当的情况下,速度提升了最多3.5倍。基于条件分布的新视角,我们进一步统一了吸收离散扩散和任意阶自回归模型(AO-ARMs),表明扩散模型的负对数似然上界可以解释为AO-ARMs的期望负对数似然。此外,我们的RADD模型在GPT-2规模的5个零样本语言建模基准测试(以困惑度衡量)中,取得了扩散模型中的最先进(SOTA)性能。
论文介绍
论文题目:Leveraging Discrete Structural Information for Molecule-Text Modeling
作者:裴启智,吴郦军,高开元,祝金华,严睿
通讯作者:吴郦军,严睿
论文概述:分子和自然语言表征的整合已成为分子科学的焦点,语言模型的最新进展显示出对这两个领域进行全面建模的巨大潜力。然而,现有的方法面临着明显的局限性,特别是它们忽略了3D 信息的建模,而这些信息对于理解分子结构和功能至关重要。我们提出了3D-MolT5,这是一个统一的框架,旨在在序列和 3D 结构空间中建模分子。我们方法的关键创新在于将细粒度的 3D 子结构表示映射到专门的 3D 标记词汇表中。这种方法有助于以标记格式无缝集成序列和结构表示,使 3D-MolT5 能够在统一的架构中编码分子序列、分子结构和文本序列。利用这种标记化输入策略,我们构建了一个统一序列和结构数据格式的基础模型。然后,我们进行联合预训练,使用多任务目标来增强模型对共享表示空间内这些不同模态的理解。因此,我们的方法显著改善了跨模态交互和对齐,解决了之前工作中的关键挑战。进一步的指令调整表明,我们的 3D-MolT5 具有强大的泛化能力,并且在多个下游任务中以优异的性能超越现有方法。
论文介绍
论文题目:From Exploration to Mastery: Enabling LLMs to Master Tools via Self-Driven Interactions
作者:渠常乐,戴孙浩,魏骁驰,蔡恒毅,王帅强,殷大伟,徐君,文继荣
通讯作者:徐君
论文概述:工具学习使大语言模型(LLMs)可以通过调用工具来与外部环境进行交互,从而有效缓解其预训练数据所固有的局限性。在此过程中,工具文档通过为LLM提供使用说明起着至关重要的作用,从而促进了有效的工具利用率。本文聚焦于 LLMs 与外部工具之间理解差距的关键挑战,这种差距源于现有以人为中心的工具文档中的不足与不准确之处。我们提出了一个新颖的框架DRAFT,通过分析 LLMs 与外部工具交互过程中产生的反馈和轨迹来动态优化工具文档。该方法以创新性的试错策略为核心,包括三个独立的学习阶段:经验收集、从经验中学习和文档重写,以迭代方式提升工具文档质量。此外,我们引入了一种促进多样性的探索策略,以保证探索的多样性,并设计了一种工具自适应的终止机制,以防止过拟合并提高效率。我们在多个数据集上的广泛实验表明,DRAFT 通过迭代的、基于反馈的优化策略,显著提升了工具文档的质量,从而增强了 LLMs 对工具的理解和使用效果。值得注意的是,我们的分析进一步揭示,经过 DRAFT 优化的工具文档在跨模型泛化能力方面表现出色。
论文介绍
论文题目:Policy-aware Reward Modeling with Uncertainty-Gradient based Data Augmentation
作者:孙泽旭,郭一驹,林衍凯,陈旭,祁琦,唐兴,何秀强,文继荣
通讯作者:陈旭
论文概述:基于人类反馈的强化学习已成为训练大型语言模型以符合人类偏好的标准且有效的方法。在此框架下,通过学习奖励模型来近似人类偏好,并以此指导策略优化,因此开发准确的奖励模型至关重要。然而,在缺乏“真实”奖励函数的情况下,当奖励模型作为人类偏好的不完美代理时,会出现诸多挑战。尤其是策略优化过程会不断改变人类偏好训练数据集的分布,而固定奖励模型会因分布外问题而受到影响,尤其是对于在线策略、方法。虽然收集新的偏好数据可以缓解这一问题,但成本高昂且优化难度较大。因此,重新利用策略交互样本成为进一步优化奖励模型的可能途径。为应对这些挑战,本文提出了一种新的方法——不确定性梯度数据增强(Uncertainty-Gradient based Data Augmentation,UGDA),通过利用策略样本维持在分布性能,从而增强奖励建模。具体而言,UGDA基于奖励集成的不确定性和策略优化的梯度影响来选择交互样本。在对选定样本进行奖励重新标记后,利用监督学习来优化奖励集成,进而获得重新训练的策略。大量实验表明,借助UGDA在无需成本高昂的人类偏好数据收集的情况下选择少量样本,能够提升策略的能力,并超越现有最先进的方法。

论文简介
论文题目:ReDeEP: Detecting Hallucination in Retrieval-Augmented Generation via Mechanistic Interpretability
作者:孙忠祥,臧晓雪,郑凯,Yang Song,徐君,张骁,俞蔚捷,李晗
通讯作者:徐君
论文概述:检索增强生成(RAG)模型旨在结合外部知识,以减少由于参数(内部)知识不足引起的幻觉。然而,即便在检索到准确且相关的内容时,RAG 模型仍可能产生幻觉,表现为生成与检索信息冲突的输出。检测此类幻觉需要理清大语言模型(LLM)如何利用外部知识和参数知识。目前的检测方法往往聚焦于其中一种机制,或未能解耦其相互交织的影响,这使得准确检测变得困难。本文研究了 RAG 场景中幻觉产生的内在机制。我们发现,当 LLM 中的知识 FFN 在残差流中过度强调参数知识,而复制头未能有效保持或整合来自检索内容的外部知识时,幻觉便会发生。基于这些发现,我们提出了 ReDeEP,一种通过解耦 LLM 对外部上下文和参数知识的利用来检测幻觉的创新方法。实验结果表明,ReDeEP 显著提高了 RAG 幻觉检测的准确性。此外,我们还提出了 AARF,通过调节知识 FFN 和复制头的贡献,缓解了幻觉问题。
论文地址: https://arxiv.org/pdf/2410.11414

论文介绍
论文题目:Think Then React: Towards Better Action-to-Reaction Motion Generation
作者:谭文辉,李博远,金楚浩,黄文炳,王希廷,宋睿华
通讯作者:宋睿华
论文概述:人类动作生成技术在虚拟现实、游戏等领域有着广泛的应用。尽管目前单人动作生成领域成果显著,然而在多人动作生成领域,由于根据一人动作直接预测另一人相应反应动作的复杂性以及统一多人动作表示方式的缺失,人类反应动作预测任务仍然未被很好的解决。针对这些挑战,我们首先采用了类思维链的方式,让模型“先思考,后反应”,有效提升了预测动作的精确度和语义匹配度。为了将可思考的大语言模型适配至多人动作场景、统一编码多人动作,我们提出解耦空间-动作分词器,并且设计了一套针对性的预训练任务。我们通过大量实验在目前最大人类交互动作数据集Inter-X上证明了方法与设计的有效性,将FID从3.988改进至1.942。
论文介绍
论文题目:ADePT: Adaptive Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning
作者:唐鹏威,胡啸林,刘勇
通讯作者:刘勇
论文概述:提示微调(Prompt Tuning, PT)通过优化少量软虚拟tokens——这些token被预置于输入token嵌入之前——使预训练大语言模型(Pre-trained Large Language Models, PLMs)能够适配下游任务。近期,分解式提示微调(Decomposed Prompt Tuning, DePT)通过将soft prompt分解为一个更短的soft prompt和一对低秩矩阵(low-rank matrices),展现了更卓越的适配能力。这对低秩矩阵的乘积被添加到输入token嵌入中以对它们施加偏置。此外,由于soft prompt更短,DePT的推理速度比PT更快。然而,本文发现DePT基于位置的token嵌入偏置(position-based offsets)限制了其在多样化模型输入上的泛化能力,且多个token嵌入共享的偏置会导致欠优化。为解决这些问题,我们提出了自适应分解式提示微调(Adaptive Decomposed Prompt Tuning, ADePT),其由一个短soft prompt和一个浅层token共享前馈神经网络(token-shared feed-forward neural network)组成。ADePT利用该神经网络为每个token学习嵌入偏置,从而生成自适应嵌入偏置(adaptive offsets),这些偏置能根据模型输入动态调整,并且ADePT还能够优化对token嵌入偏置的学习。与原始PT及其变体相比,ADePT在无需额外推理时间或可训练参数的情况下实现了更优的下游任务适配性能。在23项自然语言处理(NLP)任务和4种不同规模的经典PLM的实验中,ADePT一致优于主流的参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,甚至在部分场景中超越了全量微调(full fine-tuning)基线。我们还为ADePT方法提出了一种理论解释。
论文简介
论文题目:Perplexity Trap: PLM-Based Retrievers Overrate Low Perplexity Documents
作者:王浩喻*, 戴孙浩*,赵海源,庞亮,张骁,王刚,董振华,徐君,文继荣
通讯作者:徐君
论文概述:以往的研究发现,基于预训练语言模型(PLM)的检索模型对大语言模型(LLMs)生成的内容表现出偏好:尽管人工智能生成文档的语义与人类撰写的文档几乎相同,检索模型也会赋予它们更高的相关性分数。这种被称为源偏差的现象威胁了互联网生态的可持续发展,但其引发原因仍未得到充分探索。我们提出一个因果图解释框架来描述信息检索的过程,发现基于 PLM 的检索器因果性地赋予perplexity低的文档更高的分数,从而引发源偏差。理论分析进一步表明,源偏差的潜在原因是语言建模任务和检索任务的损失函数梯度存在相关性。在上述分析的基础上,我们提出了一种受因果启发的推理时间纠偏方法,称为因果诊断校正(CDC)。CDC 首先估计困惑度特征带来的偏差大小,然后将偏差效应从相关性分数中剥离。实验结果表明,CDC在不同数据集和不同LLMs上均具有卓越的纠偏效果,反映了所提解释框架的有效性。
论文介绍
论文题目:Investigating the Pre-Training Dynamics of In-Context Learning: Task Recognition vs. Task Learning
作者:王晓磊*,汤昕宇*,李军毅,赵鑫,文继荣
通讯作者:赵鑫
论文概述:上下文学习(ICL)的出现可能归因于两种主要能力:从示例中识别任务并利用预训练先验的任务识别(TR)和从示例中学习的任务学习(TL)。然而,这两种能力之间的关系以及这种关系如何影响ICL的出现尚不清楚。在本文中,我们首先研究了ICL在预训练过程中的变化情况。通过精心设计的指标,我们发现TR和TL在预训练期间实际上是存在竞争的。此外,我们观察到竞争与ICL性能之间存在负相关关系。对常见预训练因素(即模型大小、数据集大小和数据课程)的进一步分析揭示了管理竞争的潜在方案。基于上述分析,我们提出了一种简单而有效的方法,在推理时更好地整合ICL的这两种能力(TR & TL)。通过自适应集成学习,ICL的性能可以显著提高,使两个小模型的性能优于参数大于两者之和的大模型,实现1+1>2的奇效!
论文介绍
论文题目:Bridging Jensen Gap for Max-Min Group Fairness Optimization in Recommendation
作者:徐晨,李雨欣,王文杰,庞亮,徐君,Tat-Seng Chua
通讯作者:徐君
论文概述:组间最大最小公平性(Group Max-Min Fairness, MMF)常被用作公平推荐系统(RS)中的优化目标,因为它旨在保护边缘化的物品组,并确保一个公平竞争的平台。然而,我们的理论分析表明,在优化过程中引入MMF约束会违反样本独立性的假设,导致损失函数偏离线性加性特性。这种非线性特性在采用小批量采样时会引入模型收敛点与最优点之间的Jensen gap。理论和实证研究均表明,随着小批量大小的减少和组规模的增加,Jensen gap会相应扩大。一些基于启发式重加权或去偏策略的方法有潜力弥合Jensen gap,但这些方法要么缺乏理论保证,要么计算成本过高。为克服这些限制,我们首先理论上证明了MMF约束目标本质上可以重新表述为一个组加权优化目标。随后,我们提出了一种高效且有效的算法,名为FairDual,该算法利用对偶优化技术最小化Jensen差距。理论分析表明,FairDual能够以次线性收敛率逼近全局最优解,并在随机洗牌的小批量采样策略下很好地约束Jensen gap差距。在三个公开数据集上的六种大规模推荐系统基础模型的广泛实验表明,FairDual在准确性和公平性方面均优于所有基线方法。
论文介绍
论文题目:Super(ficial)-alignment: Strong Models May Deceive Weak Models in Weak-to-Strong Generalization
作者:杨文恺,沈世奇,沈光耀,姚巍,刘勇,龚治,林衍凯,文继荣
通讯作者:林衍凯
论文概述:超级对齐,即人类作为超人类智能模型的弱监督者对齐模型,已随着大语言模型的快速发展成为一个关键问题。最近的研究通过使用弱模型监督强模型的方式初步探讨了这一问题,并发现弱监督下的强学生能够在对齐目标上持续超越弱教师,从而出现了一种弱至强泛化现象。然而,我们关心在这种看似有前景的现象背后,是否存在弱到强欺骗的问题:强模型可能通过在弱模型已知领域表现出良好的对齐行为,而在弱模型未知的情况下表现出不对齐的行为,从而欺骗弱模型。我们在单目标对齐和多目标对齐(例如,有用性与无害性之间的冲突)上的实验发现:(1) 弱到强欺骗现象确实存在;(2) 随着弱教师和强学生之间能力差距的扩大,这种欺骗现象会愈发严重,这是一个不好的信号;(3) 使用中间模型进行过渡可以在一定程度上缓解这种欺骗,但其效果依然有限。本研究突出了超级对齐技术可靠性上潜在的问题,考虑到我们现在正在加速接近 AGI 时代,找到未来能够完全控制超人类模型的可信赖对齐技术迫在眉睫。
论文介绍
论文题目:Regulatory DNA Sequence Design with Reinforcement Learning
作者:杨钊,苏冰,曹川,文继荣
通讯作者:苏冰,曹川
论文概述:顺式调控元件(CREs),如启动子和增强子,是一类相对较短的DNA序列,可以直接调控特定基因的表达。CREs的适应度,即其增强基因表达的功能,高度依赖于其核苷酸序列,特别是一些特殊基序的组成,这些基序被称为转录因子结合位点(TFBSs)。设计CREs以优化其适应度对治疗和生物工程应用至关重要。现有的CRE设计方法通常依赖于简单的策略,如通过预训练的基因表达预测模型(即oracle)从大量候选序列中迭代引入随机突变并选择高适应度的变体。由于巨大的搜索空间和缺乏先验生物学知识的指导,这些方法容易陷入局部最优,并倾向于产生多样性较低的CREs。在本文中,我们提出了第一个利用强化学习(RL)来微调预训练的自回归(AR)生成模型的方法,用于设计高适应度的细胞类型特异性CREs,同时保持序列多样性。我们将CRE调控机制的先验知识纳入RL过程,通过整合TFBSs的作用来指导优化。通过这种方式,我们的方法鼓励去除抑制子基序并添加激活基序。 我们在三种不同人类细胞类型的增强子设计任务和两种不同酵母培养基条件下的启动子设计任务上评估了我们的方法,证明了其在生成高适应度CREs方面的有效性和稳健性。
论文介绍
论文题目:Rational Decision-Making Agent with Learning Internal Utility Judgment
作者:叶奕宁*,从鑫*,田世祚,秦禹嘉,刘充,林衍凯,刘知远,孙茂松
通讯作者:从鑫, 林衍凯
论文概述:随着技术的显著进步,许多关于大语言模型(LLMs)的研究致力于开发能够执行复杂多步骤决策任务的智能体(LLM-based Agent)。现有方法需要依赖外部性能评估指标来引导决策过程,但这种依赖在实际场景中存在问题,因为外部性能指标可能不可用、有缺陷,甚至可能存在误导。为了实现真正自主决策,必须从后验经验中构建智能体的自我理性决策能力,以独立判断每一步决策的效用(Utility)。本研究提出了RaDAgent(Rational Decision-Making Agent),通过包含“经验探索(Experience Exploration)”和“效用学习(Utility Learning)”的迭代框架促进其理性能力的构建。在该框架中,我们设计了基于Elo的效用学习方法,通过比较为每一步决策分配Elo分数,从而评估其效用。这些Elo分数随后指导决策过程,得出最优结果。实验结果表明,在Game of 24、WebShop、ToolBench和RestBench数据集上RaDAgent相比基线方法平均提升了约7.8%。此外,RaDAgent还能显著降低成本(例如减少ChatGPT API调用次数),凸显其高效性和有效性。
论文介绍
论文题目:TGB-Seq Benchmark: Challenging Temporal GNNs with Complex Sequential Dynamics
作者:易璐,彭杰,郑艳萍,莫冯然,魏哲巍,叶宇航,岳梓轩,黄增峰
通讯作者:魏哲巍,郑艳萍
论文概述:未来链接预测是实际生产生活中众多动态系统提升效益的关键。本文重点关注面向未来链接预测问题的基准数据集。我们发现现有数据集普遍存在重复边过多、缺乏复杂序列动态性等问题,而这些缺乏的特性在推荐系统和社交网络等实际应用中却尤为重要,对提升平台的用户体验和用户粘性起到了关键作用。现有动态图数据集的这一缺陷也间接导致了现有动态图方法忽视复杂序列动态性,侧重解决重复边的预测,使得这些方法在社交网络用户关注列表推荐、商品推荐等应用中表现不佳。为提供对现有动态图方法更为全面的评估,推动动态图模型设计,我们提出了具有复杂序列动态性的动态图基准数据集TGB-Seq。TGB-Seq的数据集中重复边少,旨在挑战模型学习序列动态性并预测未出现过的边。TGB-Seq数据集涵盖了电商交互、电影评分、商业评论、社交网络、引文网络和网页链接网络等多个领域的大规模数据集。基准实验表明,现有方法在TGB-Seq数据集上性能一般,并需要较高的训练成本。已有方法的这些局限性为未来研究带来了全新的挑战与机遇。
论文介绍
论文题目:Scalable and Certifiable Graph Unlearning: Overcoming the Approximation Error Barrier
作者:易璐,魏哲巍
通讯作者:魏哲巍
论文概述:随着图神经网络模型被广泛应用于包含用户敏感数据的场景中,图遗忘学习(Graph Unlearning)受到广泛关注,成为隐私保护的重要研究领域。本文关注的是理论完备的图遗忘学习方法。这类方法由于可以提供强有力的隐私保障,近年来备受关注。然而,目前的理论完备图遗忘方法在大规模图数据上仍无法直接应用,因为现有理论完备方法需要为每次删除请求重新计算图传播,而图传播的计算成本极高。虽然现在已有很多技术可用于加速一般图神经网络模型中的图传播操作,但这些技术引入的近似误差会影响节点嵌入的精度,而理论完备的图遗忘学习方法对精度有严格要求,是否能借助已有的技术提供理论完备的图遗忘学习方法还是一个未知的问题。
为了解决这一问题,我们提出了ScaleGUN,这是首个将理论完备的图遗忘学习方法扩展到十亿规模边图的解决方案。ScaleGUN 将近似图传播技术引入理论完备的图遗忘学习方法,并为节点特征、边、节点删除三种场景提供了理论保证。实验表明,ScaleGUN可以高效地在大规模图上取得很好的遗忘效果。值得一提的是,在十亿边规模的图数据集 ogbn-papers100M上,ScaleGUN能够在仅20秒内完成 5,000 条随机边的理论完备遗忘学习,其中更新节点表示向量仅需 5 秒;相比之下,传统的理论完备方法分别需要 1.91 小时和 1.89 小时来完成训练和图传播。这体现了ScaleGUN兼顾理论保证和效率的优越性。
论文介绍
论文题目:PhyMPGN: Physics-encoded Message Passing Graph Network for spatiotemporal PDE systems
作者:曾博成,王琦,闫梦涛,刘扬,程泽睿智,张毅,刘红升,王紫东,孙浩
通讯作者:孙浩
论文概述:求解偏微分方程 (PDE) 是复杂动力学系统建模的基础。最近的进展证明了基于数据驱动的基于神经的模型在预测时空动力学方面的巨大优势(例如,与传统数值方法相比,速度提高了)。然而,大多数现有的神经模型都依赖于丰富的训练数据,外推和泛化能力有限,并且在复杂条件下(例如,不规则网格或几何、复杂的边界条件、不同的 PDE 参数等)难以产生精确或可靠的物理预测。为此,我们提出了一种新的图学习方法,即物理编码消息传递图网络 (PhyMPGN),在给定小训练数据集的不规则网格上对时空偏微分方程系统进行建模。具体来说,我们将 GNN 合并到数值积分器中,以近似给定 PDE 系统的时空动态的时间行进。考虑到许多物理现象都受扩散过程的控制,我们进一步设计了一个可学习的拉普拉斯块,它编码离散的拉普拉斯-贝尔特拉米算子,以帮助和指导物理上可行的解决方案空间中的 GNN 学习。此外,还设计了边界条件填充策略来提高模型的收敛性和准确性。广泛的实验表明,PhyMPGN 能够在粗略的非结构化网格上准确预测各种类型的时空动力学,始终如一地获得最先进的结果,并以相当大的收益优于其他基线。
论文介绍
论文题目:Long Context Compression with Activation Beacon
作者:张配天,刘政,肖诗涛,邵宁录,叶启威,窦志成
通讯作者:刘政
论文概述:长上下文压缩是一个关键的研究问题,因为它对于降低与 LLM 相关的高计算和内存成本具有重要意义。在本文中,我们提出了 Activation Beacon,这是一个基于 Transformer 的 LLM 插件模块,旨在有效、高效和灵活地压缩长上下文。为了实现这一目标,我们的方法引入了以下技术设计。我们直接压缩激活(即每一层的键和值),而不是利用软提示来传递信息(这构成了在长上下文中封装复杂信息的主要瓶颈)。我们定制了压缩工作流程,其中每个细粒度输入单元都经过逐步压缩,从而在训练和推理过程中实现高质量压缩和高效计算。我们通过基于压缩的自回归来训练模型,充分利用纯文本和指导数据来优化模型的压缩性能。在训练过程中,我们在每个步骤随机抽取一个压缩率,教导模型支持各种压缩配置。我们对各种长上下文任务进行了广泛的评估,这些任务的长度(例如 128K)可能远远超过最大训练长度(20K),例如文档理解、小样本学习和大海捞针。虽然现有方法难以处理这些具有挑战性的任务,但 Activation Beacon 在各种场景中都保持了与未压缩基线相当的性能,推理时间加快了 2 倍,KV 缓存的内存成本降低了 8 倍。
论文介绍
论文题目:Learning Evolving Tools for Large Language Models
作者:陈国鑫,张众,从鑫,郭放达,吴叶赛,林衍凯,冯文政,王雅圣
论文概述:工具学习使得大语言模型(LLMs)能够与外部工具和API进行交互,从而极大地扩展了LLMs的应用范围。然而,由于外部环境的动态变化,这些工具和API可能随着时间的推移而过时,导致LLMs无法正确调用工具。现有研究主要集中在静态环境中,忽视了这一问题,限制了LLMs在现实世界应用中的适应性。论文提出了一个增强LLMs应对工具变化的适应性和反思能力的新框架ToolEVO。通过利用蒙特卡罗树搜索,TOOLEVO促进了LLMs在动态环境中的主动探索和交互,使其能够基于环境反馈进行自主反思和工具使用自我更新。此外,论文还构建了一个用来评估工具变化影响的基准ToolQA-D,并用大量实验证明了方法的有效性和稳定性,突显了适应工具变化对于有效工具学习的重要性。
论文介绍
论文题目:Improving Long-Text Alignment for Text-to-Image Diffusion Models
作者:刘路平,杜超,庞天宇,王泽寒, 李崇轩, 徐东
论文概述:文本到图像(T2I)扩散模型的快速发展使其能够从给定文本生成前所未有的结果。然而,随着文本输入变长,现有的编码方法(如CLIP)面临局限性,生成图像与长文本的对齐变得具有挑战性。为了解决这些问题,我们提出了LongAlign,其中包括一种用于处理长文本的分段级编码方法,以及一种用于有效对齐训练的分解偏好优化方法。对于分段级编码,长文本被划分为多个段落并分别处理。这种方法克服了预训练编码模型的最大输入长度限制。对于偏好优化,我们提供了基于CLIP的分解偏好模型,用于微调扩散模型。具体来说,为了利用基于CLIP的偏好模型进行T2I对齐,我们深入研究了其评分机制,发现偏好分数可以分解为两个部分:一个衡量T2I对齐的文本相关部分,以及一个评估人类偏好中其他视觉方面的文本无关部分。此外,我们发现文本无关部分在微调过程中会导致常见的过拟合问题。为了解决这一问题,我们提出了一种重新加权策略,为这两个部分分配不同的权重,从而减少过拟合并增强对齐效果。使用我们的方法对512×512的Stable Diffusion (SD) v1.5进行约20小时的微调后,微调后的SD在T2I对齐方面优于更强的基模型,如PixArt-α和Kandinsky v2.2。
论文介绍
论文题目:Proactive Agent: Shifting LLM Agents from Reactive Responses to Active Assistance
作者:卢雅西,杨深智,钱成,陈桂荣,罗钦雨,吴叶赛,汪华东,从鑫,张众,林衍凯,刘卫文,王雅圣,刘知远,刘方明,孙茂松
论文概述:由大型语言模型驱动的智能体在解决复杂任务方面展现出卓越能力。然而,现有智能体系统大多具有被动响应特性,在需要前瞻性和自主决策的场景中效果受限。本文致力于开发能够预判任务并自主启动操作、无需显式人类指令的主动型智能体。为此,我们提出一种创新的数据驱动方法:首先通过采集真实人类活动数据生成主动性任务预测,经人工标注接受/拒绝标签后,利用标注数据训练奖励模型(模拟人类判断机制),构建LLM智能体主动性的自动化评估体系。基于此,我们开发了完整的数据生成管道,创建了包含6,790个标注事件的多样化数据集ProactiveBench。实验表明,使用该数据集微调模型可显著提升LLM智能体的主动性。结果显示,微调模型在主动提供协助任务中取得66.47%的F1值,优于所有开源和闭源模型。这些发现验证了该方法在构建主动性智能体系统方面的潜力,为人机协作研究开辟了新方向。
论文介绍
论文题目:Advancing LLM Reasoning Generalists with Preference Trees
作者:袁立凡*,崔淦渠*,王汉彬*,丁宁,王星尧,邓佳,单博骥,陈慧敏,谢若冰,林衍凯,刘正皓,周伯文,彭浩,刘知远,孙茂松
论文概述:我们推出了 EURUS,一套专为推理优化的大型语言模型(LLMs)。EURUS 模型基于 Mistral-7B、Llama-3-8B 和 Mixtral-8x22B 微调而成,在覆盖数学、代码生成以及逻辑推理问题的多项基准测试中,实现了开源模型的最新水平。值得注意的是,EURUX-8X22B 在推理能力上,通过针对 12 个测试集的综合基准评测(涵盖 5 项任务),超越了 GPT-3.5 Turbo。EURUS 的强大性能主要归功于 ULTRAINTERACT,这是我们新开发的大规模高质量训练数据集,专为复杂推理任务设计。ULTRAINTERACT 可用于监督微调、偏好学习以及奖励建模。该数据集为每个指令配备了一个偏好树,包括以下内容:推理链:以统一格式呈现的多样化规划策略。多轮交互轨迹:与环境和批评器的交互过程。成对的正负响应:用于促进偏好学习。ULTRAINTERACT 使我们能够深入研究推理任务中的偏好学习。研究表明,一些在普通对话中表现良好的偏好学习算法,在推理任务中可能效果欠佳。我们假设在推理任务中,正确答案的空间比错误答案的空间小得多,因此需要明确增加选择数据的奖励值。因此,除了像许多偏好学习算法那样增加奖励差距外,正响应奖励的绝对值应为正值,并可作为性能的代理指标。受到此启发,我们提出了一种新的奖励建模目标,并通过实验证明,该方法能够带来更稳定的奖励建模曲线和更好的性能。结合 ULTRAINTERACT,我们获得了一个强大的奖励模型。
论文介绍
论文题目:REEF: Representation Encoding Fingerprints for Large Language Models
作者:张杰,刘东瑞,钱辰,张林峰,刘勇,乔宇,邵婧
论文概述:保护开源大型语言模型(LLMs)的知识产权非常重要,因为训练LLMs需要耗费大量的计算资源和数据。因此,模型所有者和第三方需要确定一个可疑模型是否是受害者模型的后续开发版本。为此,我们提出了一种无需训练的REEF方法,从LLMs特征表示的角度来识别可疑模型与受害者模型之间的关系。具体来说,REEF通过计算并比较可疑模型与受害者模型在相同样本上的中心核对齐相似度来实现这一目标。这种无需训练的REEF方法不会损害模型的通用能力,并且对顺序微调、剪枝、模型合并和排列具有鲁棒性。通过这种方式,REEF为第三方和模型所有者提供了一种简单有效的方法,共同保护LLMs的知识产权。
Github: https://github.com/AI45Lab/REEF

论文介绍
论文标题:A Non-Contrastive Learning Framework for Sequential Recommendation with Preference-Preserving Profile Generation
作者:Huimin Zeng,Xiaojie Wang,Anoop Jain,窦志成,Dong Wang
论文概述:对比学习(Contrastive Learning, CL)在序列推荐(Sequential Recommendation, SR)中已被证明能有效学习具有泛化能力的用户表征,但由于其依赖负样本,因此计算成本较高。为克服这一局限,我们首次提出了一种非对比学习(Non-Contrastive Learning, NCL)框架用于序列推荐,该框架消除了识别和生成负样本的计算开销。然而,在缺少负样本的情况下,仅依靠正样本学习均匀表征具有挑战性,因为这容易导致表示坍塌。此外,由于现有的临时增强方法可能产生用户偏好不一致的正样本,因此所学表示的对齐性可能会大打折扣。为应对这些挑战,我们设计了一种新颖的偏好保持用户画像生成方法,为非对比训练生成高质量的正样本。受差分隐私的启发,我们的方法创建了具有高度多样性且可证明保留了一致用户偏好的增强用户画像。正样本的多样性和一致性提升后,我们的非对比学习框架显著增强了所学表示的对齐性和均匀性,从而有助于更好的泛化。在各种基准数据集和模型架构上的实验结果证明了所提方法的有效性。最后,我们的研究表明,均匀性和对齐性在提高序列推荐的泛化能力方面均起着至关重要的作用。有趣的是,在我们的数据稀疏设置中,对齐性通常比均匀性更为重要。
论文介绍
论文题目:Optimal Transport for Time Series Imputation
作者:Hao Wang, Zhengnan Li, Haoxuan Li, 陈旭, Mingming Gong, Bin Chen, Zhichao Chen
论文概述:基于分布匹配的缺失值填充方法在运用到时间序列数据时存在不足,难以有效捕捉自相关性和非平稳性。为此,我们提出了一种近邻谱增强的Wasserstein度量,通过引入成对频谱距离和选择性匹配机制,有效适配时间序列的自相关性和非平稳性特征。进一步,我们开发了一种时间序列填充框架,通过迭代最小化该度量,优化填充结果。实验表明,该方法在多种时间序列数据中表现优异,为时间序列填充提供了新的解决方案。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox