学院新闻
我院师生论文被国际学术会议The Web Conference (WWW) 2025录用
日期:2025-01-27访问量:近日,国际人工智能顶级会议The Web Conference(WWW )2025论文接收结果公布,中国人民大学高瓴人工智能学院师生有14篇论文被录用。The Web Conference 是互联网和万维网技术领域最具影响力的会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议。The Web Conference 2025会议将于2025年4月28日至5月2日在澳大利亚悉尼举行。

论文介绍
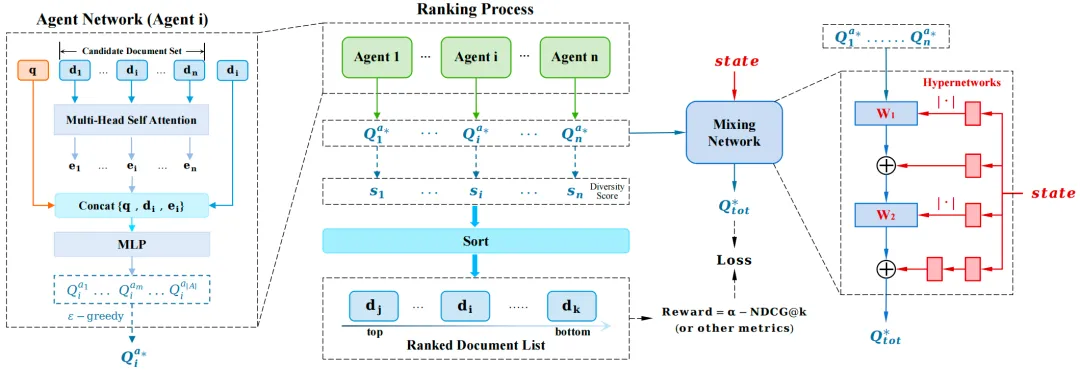
论文题目:MA4DIV: Multi-Agent Reinforcement Learning for Search Result Diversification (Long Paper)
作者:陈逸群,毛佳昕,张艺,马德红,夏龙,樊骏,石岱庭,程智聪,辜斯缪,殷大伟
通讯作者:毛佳昕
论文概述:搜索结果多样化(SRD)旨在确保排序列表中的文档涵盖了广泛的子主题,是信息检索中一个重要且被广泛研究的问题。现有方法主要利用“贪婪选择”的范式,即每次选择一个多样性得分最高的文档进行排序;此外,部分方法通过优化目标函数的近似值提升排序列表的多样性。这些方法面临着排序效率较低,或者容易陷入次优排序等问题。为了缓解这些问题,我们提出MA4DIV算法,使用多智能体强化学习(MARL)优化SRD任务。在MA4DIV中,每个文档被看作一个智能体,SRD排序即被建模为多个智能体之间的协作任务。通过将SRD排序问题建模为协作的MARL问题,该方法可以直接优化多样性指标(如α-NDCG),并同时实现高效的训练和推理。我们在公开的TREC数据集和百度的大规模数据集上进行了实验,实验结果表明,MA4DIV在有效性和效率上都比现有方法有显著提升,尤其是在百度的业界真实数据集上。
论文介绍
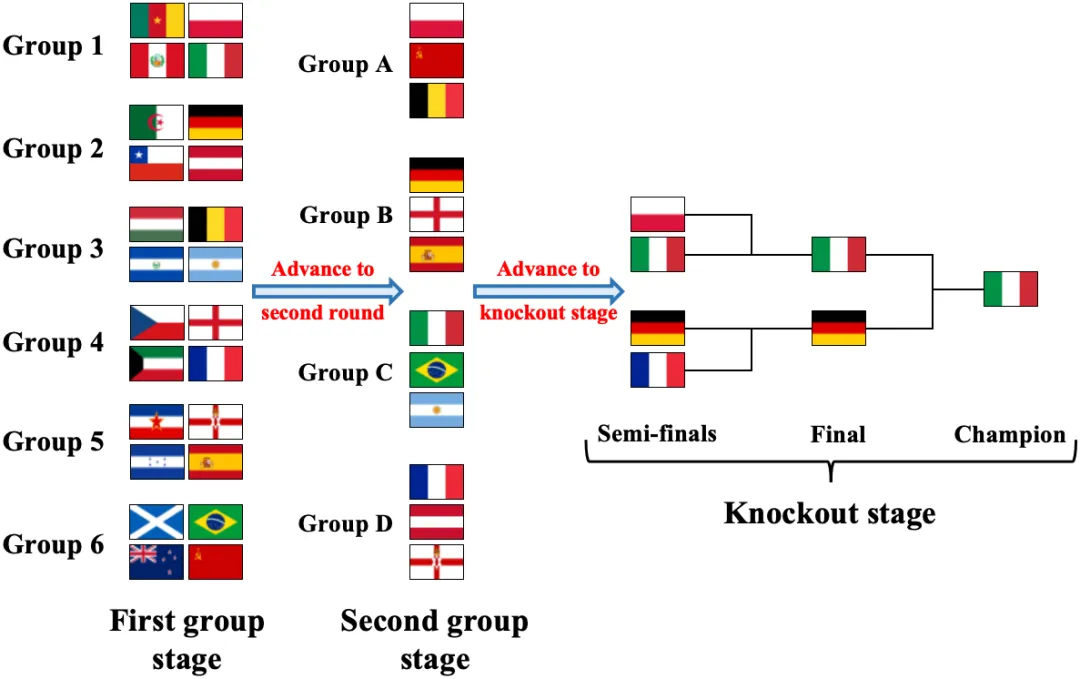
论文题目:TourRank: Utilizing Large Language Models for Documents Ranking with a Tournament-Inspired Strategy (Long Paper)
作者:陈逸群,刘琦,张艺,孙维纬,马新宇,杨威,石岱庭,毛佳昕,殷大伟
通讯作者:毛佳昕
论文概述:大型语言模型(LLMs)越来越多地用于zero-shot文档排序,并取得了不错的效果。然而,LLMs在排序方面仍面临若干重大挑战:(1)LLMs受限于输入长度,无法同时处理大量文档;(2)输出的文档排序会受到文档输入顺序的影响,导致排序结果不一致;(3)在成本和效果之间难以取得平衡。为了克服这些挑战,我们引入了一种新颖的文档排序方法,称为TourRank,该方法受到体育赛事(如FIFA世界杯)的启发。具体来说,我们通过采用类似于体育赛事并行小组赛的多阶段分组策略,克服了输入长度的限制并减少了LLMs排序的延迟;通过使用积分系统整合多个排序结果,提高了排序性能和LLMs对输入顺序的鲁棒性。我们在TREC DL数据集和BEIR的多个任务上使用不同的LLM测试了TourRank。实验结果表明,TourRank以适中的成本实现了最好的排序性能。
论文介绍
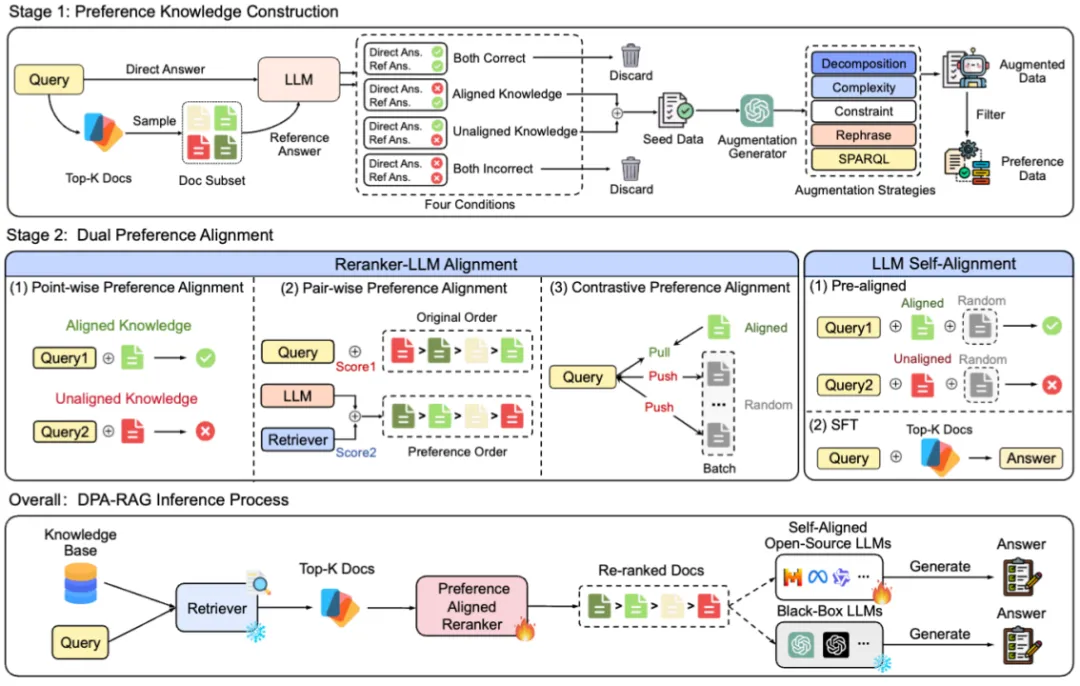
论文题目:Understand What LLM Needs: Dual Preference Alignment for Retrieval-Augmented Generation (Long Paper)
作者:董冠霆,朱余韬,张宬浩,王泽晨,窦志成,文继荣
通讯作者:窦志成
论文概述:检索增强生成(RAG)有效缓解了大语言模型的幻觉问题。然而,由于检索器与大语言模型的多样化知识偏好的存在偏差,这势必对开发出可信RAG系统提出了挑战。
为了解决这一挑战,我们提出了DPA-RAG,一个旨在对齐RAG系统多样化知识偏好的通用框架。具体而言,我们首先介绍了一个偏好知识构建流程,并结合五种新颖的查询增强策略,以缓解偏好数据稀缺的问题。基于偏好数据,DPA-RAG 同时实现了外部和内部的双重偏好对齐:1)它将三种不同粒度的偏好对齐能力共同整合到一个重排序器中,以实现了RAG系统的外部偏好对齐;2)它在标准的监督微调阶段之前引入了一个预对齐阶段,使大语言模型能够隐式地捕捉对齐自身偏好的知识,从而实现RAG组件间的内部对齐。在四个知识密集型问答数据集的实验结果表明,DPA-RAG在所有基线模型中表现优越,并能无缝集成到黑盒与开源的RAG系统中。进一步对模型参数、偏好对齐、数据质量和训练策略维度的分析确认了DPA-RAG作为即插即用解决方案,为开发可信的RAG系统提供了实用见解。
DPA-RAG代码与数据已开源:
https://github.com/dongguanting/DPA-RAG
论文链接:
https://arxiv.org/abs/2406.18676
论文介绍
论文题目:Two-stage Auction Design in Online Advertising(Long Paper)
作者:范志康,胡兰,王瑞睿,马中瑞,王越,叶琪,沈蔚然
通讯作者:沈蔚然
论文概述:在现代在线广告系统中,每次拍卖通常涉及大量广告商,这导致了可扩展性问题。为了缓解这一问题,两阶段拍卖机制被提出并被业界广泛应用。这种拍卖形式能够短时间内高效地在众多候选广告主中分配广告位。该机制在第一阶段使用快速但粗略的模型来选择一小部分广告主,然后在第二阶段使用较慢但更精细的模型来确定拍卖最终的获胜者。然而,现有的两阶段拍卖机制主要关注于优化社会福利,忽视了平台的其他关键目标,如平台收入。
在本文中,我们提出了广告筛选指标,分别命名为Max-Wel和Max-Rev,以分别优化平台的福利和收入。这些指标基于每个广告对相应目标函数的贡献。我们随后为这些提出的指标提供了理论保证。我们的方法适用于社会福利和平台收入优化,并且可以通过神经网络轻松实现。通过在合成和工业数据上进行的充分实验,我们展示了所提出的选择指标相较于现有方法的优势。
论文介绍
论文题目:Leveraging Passage Embeddings for Efficient Listwise Reranking with Large Language Models(Long Paper)
作者:刘琦,王博,王楠,毛佳昕
通讯作者:毛佳昕
论文概述:近期研究表明,大语言模型(LLMs)在段落排序任务中表现出色,诸如 RankGPT 的列表式方法已成为该任务的新技术前沿。然而,RankGPT 的效率受到LLM最大上下文长度和推理较高延迟的限制。为了解决这些问题,本文提出了一种名为 PE-Rank 的方法,通过单段落嵌入作为上下文的有效压缩方式,实现高效的列表式段落重排。通过将每个段落视为一个特殊词元,我们可以直接将段落嵌入输入到 LLM 中,从而减少输入长度。此外,我们引入了一种推理方法,动态地限制解码空间到这些特殊词元中,从而加速解码过程。在模型训练中,我们采用了列表式排序学习损失函数,以适应重排任务。在多个基准测试上的评估结果表明,PE-Rank 在预填充和解码方面显著提升了效率,同时保持了具有竞争力的排序性能。
论文介绍
论文题目:Optimizing Revenue through User Coupon Recommendations in Truthful Online Ad Auctions(Long Paper)
作者:刘晓冬、丁一鸣、林肖、李长城、江鹏、沈蔚然
通讯作者:沈蔚然
论文概述:在线广告是众多互联网公司的主要收入来源,这些公司通常通过拍卖方式销售广告位。传统的在线广告拍卖假设在拍卖过程中广告的点击率(CTR)和转化率(CVR)是固定的。然而,本文研究了一种新场景,其中广告主可以向用户提供优惠券,从而影响CTR和CVR,并最终影响平台的收入。我们研究了如何在激励兼容拍卖系统中向广告主推荐用户优惠券。我们将平台与广告主之间的互动建模为一种扩展形式博弈,其中广告主首先向平台报告优惠券报价,以获得优惠券推荐,然后通过提交竞拍出价参与拍卖。我们的研究确定了一个充分条件,在此条件下,广告主的最优策略是在推荐和拍卖阶段都真实报告他们的估值。基于这些研究成果,我们构建了两种机制。第一种机制是分布无关机制,它在工业系统中易于实现;第二种机制是收入最优机制,相比现有工作 Liu et al.,它提供了更简单的实现方式。无论是合成实验还是工业实验,都表明我们的机制提升了平台的收入。值得注意的是,我们的收入最优机制与现有工作Liu et al.相比,达到了相同的结果,同时提供了更简单的实现。
论文介绍
论文题目:A Context-Aware Framework for Integrating Ad Auctions and Recommendations(Long Paper)
作者:马毓超,李维安,窦越嘉,苏智渊,余昌远,祁琦
通讯作者:祁琦
论文概述:当前许多电商平台都会向用户呈现广告和原生内容的混合列表。一种常用的方法是分别对广告和原生内容进行排序生成各自的子列表,然后按顺序将广告插入到原生内容列表中。然而,这种方法有以下缺点。首先,它只能确保每个生成的广告和原生内容列表各自实现局部最优,而无法保证全局最优。其次,这种方法忽略了广告和原生内容之间的相互影响,导致上下文信息的利用不充分。此外,该方法无法规避广告商的策略行为。因此,我们提出了一个上下文感知的集成框架来解决这些问题。具体而言,它同时对广告和原生内容及其上下文信息进行建模,并采用基于学习的方法来防止广告商采取策略行为。之后,该框架直接生成混合列表,从而提高整体性能。我们还提出了基于 transformer的上下文网络(TICNet)来生成最佳上下文感知的混合排序机制。最后,我们在合成和真实数据集上验证了 TICNet 的有效性。我们的实验结果表明,TICNet 在多个指标上的表现明显优于基线模型。
论文介绍
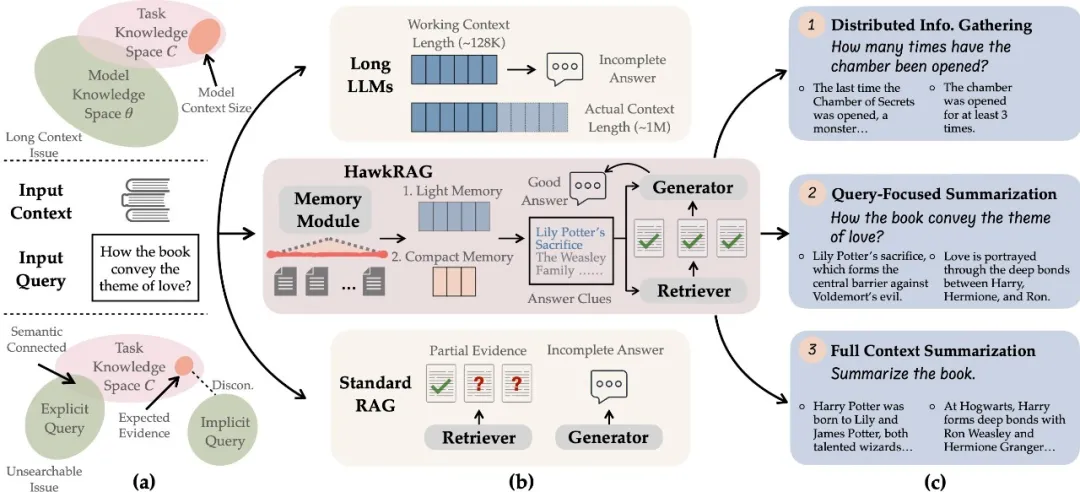
论文题目:MemoRAG: Boosting Long Context Processing with Global Memory-Enhanced Retrieval Augmentation (Long Paper)
作者:钱泓锦,刘政,张配天,毛科龙,连德富,窦志成,黄铁军
通讯作者:刘政
论文概述:处理长文本上下文对于大型语言模型来说是一个重大挑战。检索增强生成(RAG)被认为是一种有前景的解决方案。然而,传统的RAG方法由于两个基本要求而存在限制:1)需要明确意图的查询,以及2)结构良好的知识库。然而,在一般的长文本处理任务中,这些条件通常并不成立。
在本工作中,我们提出了MemoRAG,这是一个由全局记忆增强检索赋能的新型RAG框架。MemoRAG采用双系统架构。首先,它使用一个轻量但长距离的系统来创建长文本的全局记忆。当一个查询被提出时,它会生成草稿答案,为检索工具提供有用的线索,以便在长文本中定位相关信息。其次,它利用一个昂贵但能力强的系统,基于检索到的信息生成最终答案。在此基础框架之上,我们将记忆模块实现为键值(KV)压缩的形式,并通过从生成质量的反馈(即强化学习生成反馈,RLGF)中增强其记忆和线索生成能力。在我们的实验中,MemoRAG在多种长文本评估任务中都取得了优异的表现,不仅在传统RAG方法难以应对的复杂场景中表现出色,也在通常应用RAG的简单场景中表现良好。
MemoRAG模型和代码已开源:
https://github.com/qhjqhj00/MemoRAG
论文链接:
https://arxiv.org/abs/2409.05591
论文介绍
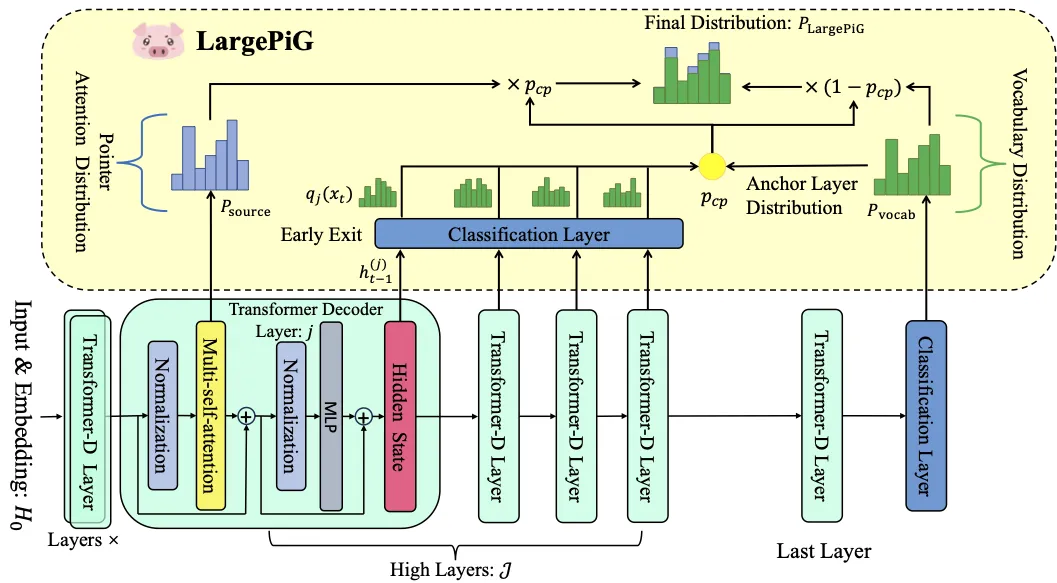
论文题目:LargePiG for Hallucination-Free Query Generation: Your Large Language Model is Secretly a Pointer Generator (Long Paper)
作者:孙忠祥,思子华,臧晓雪,郑凯,Yang Song,张骁,徐君
通讯作者:徐君
论文概述:最近关于查询生成的研究集中于基于大语言模型的方法,尽管这些方法带来了最先进查询生成性能,但也引入了生成查询中的幻觉问题。在本工作中,我们提出了‘相关性幻觉’和‘事实性幻觉’作为基于LLMs的查询生成所带来的幻觉问题的新分类。我们提出了一种有效的方法,将LLM生成查询的内容与形式分离,该方法在保留从输入中提取并整合的事实性知识的同时,利用LLM强大的语言能力来生成句法结构(包括功能词)。具体而言,我们介绍了一种与模型无关且无需训练的方法,将大语言模型转化为一个指针生成器(LargePiG)。在此方法中,指针的注意力分布利用了LLM固有的注意力权重,而复制概率则来源于模型高层的词汇分布与最后一层词汇分布之间的差异。为了验证LargePiG的有效性,我们构建了两个数据集,用以评估查询生成中的幻觉问题,涵盖了文档和视频场景。在各种LLMs上的实证研究表明,LargePiG在这两个数据集上的表现优于其他方法。额外的实验还验证了LargePiG能够减少大规模视觉语言模型中的幻觉问题,并提升基于文档的问题回答以及事实性评估任务的准确性。
论文链接:
https://arxiv.org/abs/2410.11366
论文介绍
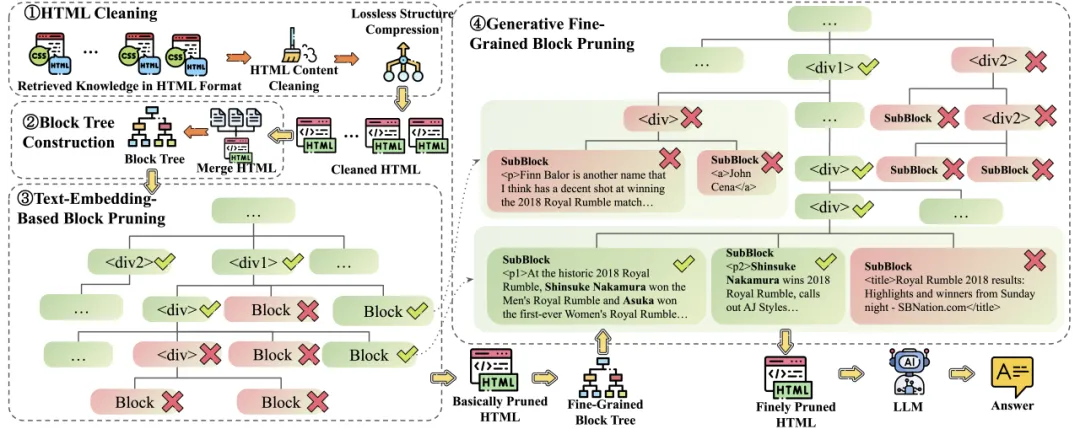
论文题目:HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems (Long Paper)
作者:谭杰骏,窦志成,王文,王蟒,陈炜鹏,文继荣
通讯作者:窦志成
论文概述:检索增强生成(RAG)已被证明能够提高知识能力并缓解大语言模型(LLMs)的幻觉问题。网络是RAG系统中使用的外部知识的主要来源,许多商业系统如ChatGPT和Perplexity已将网络搜索引擎用作其主要检索系统。通常,此类RAG系统检索搜索结果,下载结果的HTML源,然后从HTML源中提取纯文本。纯文本文档或文本块被输入到LLMs中以增强生成。然而,HTML中固有的许多结构和语义信息,如标题和表格结构,在这种基于纯文本的RAG过程中会丢失。
为了缓解这个问题,我们提出基于HTML的检索增强生成新范式——HtmlRAG,它使用HTML而不是纯文本作为检索知识的格式。我们认为HTML在对外部文档中的知识进行建模方面比纯文本更好,并且大多数LLMs具备强大的理解HTML的能力。然而,使用 HTML 带来了新的挑战。HTML包含标签、JavaScript和CSS规范等额外内容,这给RAG系统带来了额外的输入标记和噪声。为了解决这个问题,我们提出了HTML清理、压缩和修剪策略,以在尽量减少信息损失的同时缩短HTML。具体来说,我们设计了一种基于两步块树的修剪方法,该方法修剪无用的HTML块并仅保留HTML的相关部分。在六个问答数据集上的实验证实了在RAG系统中使用HTML的优越性。HtmlRAG模型和代码已开源:
https://github.com/plageon/HtmlRAG
论文链接:
https://arxiv.org/abs/2411.02959
论文介绍
论文题目:RecUserSim: A Realistic and Diverse User Simulator for Evaluating Conversational Recommender Systems (Industry Track)
作者:陈麓羽*,戴全宇*,张泽宇,冯雪扬,张明渝,唐鹏程,陈旭,朱越,董振华
通讯作者:陈旭
论文概述:对话式推荐系统(CRS)通过多轮交互显著提升用户体验,但其评估仍然面临诸多挑战。用户模拟器通过模拟用户与系统的交互,为CRS提供了一种全面的评估手段。然而,现有方法难以构建真实且多样化的用户行为,并且缺乏明确的评分机制。为此,我们提出了RecUserSim,一种基于大语言模型智能体(LLM Agent)的用户模拟器,兼具高真实感、多样性和显式评分能力。RecUserSim由四个核心模块组成:用户画像模块,用于定义多样化的用户特征;记忆模块,用于追踪交互历史并挖掘用户的潜在偏好;行为模块,基于有限理性理论,构建了一个评分-选择-回复的三层动作结构,用于生成用户的动作;以及输出调整模块,用于提升生成用户语言的质量。实验结果表明,RecUserSim能够生成更加真实且多样的高质量对话,同时在不同基座模型下,其评分结果具有高度一致性,充分证明了其在CRS评估中的有效性。
论文介绍
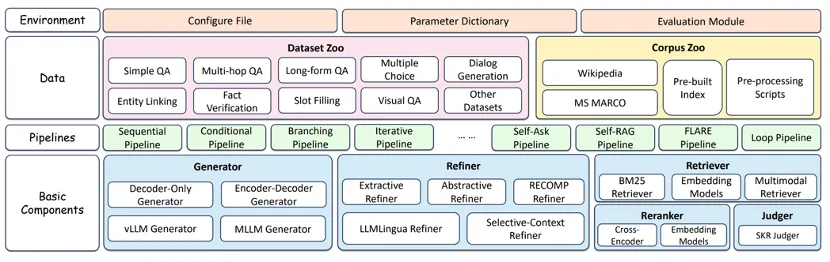
论文题目:FlashRAG: A Modular Toolkit for Efficient Retrieval-Augmented Generation Research (Resource Paper)
作者:金佳杰,朱余韬,窦志成,董冠霆,杨欣羽,张宬浩,赵桐,杨昭,文继荣
通讯作者:朱余韬,窦志成
论文概述:检索增强生成 (RAG) 是改进大型语言模型 (LLM)和多模态大型语言模型(MLLM)以生成更准确、更符合事实和更及时内容的一种有前景的方式,引起了广泛的研究关注。然而,由于缺乏标准化的实施框架,加上RAG过程本身的复杂性,这使得研究人员难以在一个一致的环境中比较和评估这些方法,既耗时又具有挑战性。现有的RAG工具包,如LangChain和LlamaIndex,虽然可用,但往往过于笨重,无法满足研究人员的个性化需求。为应对这一挑战,我们提出了FlashRAG,这是一个高效且模块化的开源工具包,旨在帮助研究人员在一个统一的框架内重现现有的RAG方法并开发他们自己的RAG算法。我们的工具包实现了16种先进的RAG方法,囊括了38个预处理过的基准数据集,并且支持多模态RAG相关的功能和开发。本工具包具备多种特性,包括可定制的模块化框架、丰富的预实现RAG成果库、全面的数据集、高效的辅助预处理脚本以及广泛而标准的评估指标。
FlashRAG的代码和RAG工具框架已经开源:
https://github.com/RUC-NLPIR/FlashRAG
论文链接:
https://arxiv.org/abs/2405.13576
论文介绍
论文题目:USPTO-LLM: A Large Language Model-Assisted Information-enriched Chemical Reaction Dataset (Resource Paper)
作者:袁深,龚舒凯,许洪腾
通讯作者:许洪腾
论文概述:最近几年,在化学反应预测和逆合成任务中,尽管深度学习模型取得了令人印象深刻的表现,但是该领域的现有数据集逐渐成为了当前研究的瓶颈——其较小的数据规模和反应条件信息的缺失阻碍了深度学习模型的实用性。在本篇工作中,我们利用大语言模型构建了一个信息丰富的化学反应数据集,称为USPTO-LLM。该数据集包含从美国专利商标局(USPTO)专利文件中提取的247000个化学反应,涵盖了丰富的反应条件信息。我们使用大语言模型自动加速数据收集过程,并采用可靠的质量控制流程提升数据质量。实验表明,在USPTO-LLM上的预训练可以有效提升现有的逆合成方法的模型表现。
论文介绍
论文题目:MemEngine: A Unified and Modular Library for Developing Advanced Memory of LLM-based Agents (Resource Paper)
作者:张泽宇,戴全宇,陈旭,李锐,李忠阳,董振华
通讯作者:陈旭
论文概述:近年来,基于大语言模型的智能体在许多领域得到了广泛应用,而记忆是智能体的重要能力,为任务的实现提供了基础。虽然一些近期的工作提出了不同的智能体记忆机制,但它们缺少一个统一框架下的实现方案。为了解决这个问题,我们提出了一个统一的智能体记忆机制框架,并设计了模块化的工具库MemEngine,用于便捷地实现和使用不同的智能体记忆机制。MemEngine实现了近期研究中的记忆机制方法,设计了便捷开发与可拓展的模块,并提供了丰富且用户友好的使用方式。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox