学院新闻
我院师生论文被国际学术会议EMNLP录用
日期:2024-10-02访问量:9月20日,国际学术会议EMNLP2024论文接收结果公布。中国人民大学高瓴人工智能学院师生有22篇论文被录用,其中有10篇为Findings of EMNLP。自然语言处理中的经验方法会议(Empirical Methods in Natural Language Processing,简称EMNLP ) 由国际计算语言学协会ACL举办,是自然语言处理和人工智能领域重要的学术会议之一,EMNLP 2024将于11月12日至11月16日在美国迈阿密举行。

论文介绍
论文题目:Learning Interpretable Legal Case Retrieval via Knowledge-Guided Case Reformulation
作者:邓琛龙,毛科龙, 窦志成
通讯作者:窦志成
论文概述:类案检索对于维护司法公正至关重要。与一般的网页搜索不同,类案检索涉及处理冗长、复杂且高度专业化的法律文件。现有的方法往往忽视了法律专家知识的引入,而这些知识对于准确理解和建模法律案件至关重要,导致检索性能不尽如人意。本文介绍了KELLER,一种基于大型语言模型(LLMs)的法律知识引导案件重构方法,旨在实现有效且可解释的法律案件检索。通过引入关于犯罪和法律条款的专业法律知识,我们使大型语言模型能够准确地将原始法律案件重构为简明的犯罪子事实,这些子事实包含了案件的关键信息。在两个法律案件检索基准上的大量实验表明,KELLER在复杂法律案件查询中的检索性能和稳健性优于现有方法。
论文介绍
论文题目:ChatRetriever: Adapting Large Language Models for Generalized and Robust Conversational Dense Retrieval
作者:毛科龙,邓琛龙,陈浩楠,莫冯然,刘政,Tetsuya Sakai, 窦志成
通讯作者:刘政,窦志成
论文概述:对话式搜索需要准确理解用户在复杂多轮对话中的意图。本文提出了ChatRetriever,它继承了大型语言模型强大的泛化能力,能够稳健地表示复杂的对话会话以进行密集检索。为此,我们提出了一种简单而有效的双重学习方法,通过对比学习调整大型语言模型以适应检索任务,同时通过在高质量对话指令调优数据上进行掩码指令调优来增强复杂会话的理解能力。在五个对话式搜索基准上的大量实验表明,ChatRetriever显著优于现有的对话密集检索器,达到了与基于大型语言模型的重写方法相媲美的最先进性能。此外,ChatRetriever在处理多样化的对话上下文方面表现出了卓越的鲁棒性。我们的工作突显了通过复杂输入(如对话式搜索会话)将大型语言模型应用于检索的潜力,并提出了一种有效的方法来推动这一研究方向的进展。
论文介绍
论文题目:Small Agent Can Also Rock! Empowering Small Language Models as Hallucination Detector
作者:成晓雪*,李军毅*,赵鑫,张鸿志,张富峥,张迪,盖坤,文继荣
通讯作者:赵鑫
论文概述:大语言模型(LLMs)在各种自然语言处理任务中表现出色,但它们容易生成错误的内容,称为幻觉。现有的研究主要依赖于功能强大的闭源LLMs(如GPT-4)来检测幻觉。本文提出了一个名为HaluAgent的自主LLM agent框架,使相对较小的LLMs(如Baichuan2-Chat 7B)能够主动选择合适的工具来检测文本、代码和数学表达等多种类型的幻觉。在HaluAgent中,我们集成了LLM、多功能工具箱,并设计了一个细粒度的三阶段检测框架以及内存机制。为了提高HaluAgent的效果,我们利用现有的中英文数据集合成检测轨迹进行微调,从而赋予HaluAgent双语幻觉检测能力。广泛的实验表明,仅使用2000个样本进行微调,HaluAgent在各种任务和数据集上取得了与无增强工具的GPT-4相当甚至更好的的幻觉检测表现。
论文介绍
论文题目:Not Everything is All You Need: Toward Low-Redundant Optimization for Large Language Model Alignment
作者:陈志朋*,周昆*,赵鑫,王静远,文继荣
通讯作者:赵鑫
论文概述:大型语言模型(LLMs)在复杂任务和场景中仍然难以与人类偏好对齐。它们容易过拟合训练数据中的意外模式或表面风格。我们采取了一系列的先验实验,仅选择LLMs中前10%更新程度最大的参数进行对齐训练,在训练过程的收敛程度和下游任务的最终性能上都有所改善。这表明在对齐训练中大模型存在冗余神经元。为了减少其影响,我们提出了一种低冗余对齐方法,名为ALLO,重点优化与下游任务最相关的神经元。具体而言,我们首先通过基于梯度的策略来识别与人类偏好数据相关的神经元,然后通过奖励模型识别与对齐相关的关键词元以计算损失。此外,我们还将对齐过程分解为遗忘和学习阶段,在这两个阶段中,首先遗忘未对齐知识的词元,然后学习对齐知识,分别更新不同比例的神经元。在问答、数学推理、指令跟随三大任务的10个数据集上的实验结果显示了ALLO的有效性。
论文介绍
论文题目:REAR: A Relevance-Aware Retrieval-Augmented Framework for Open-domain Question Answering
作者:王禹淏*,任瑞阳*,李军毅,赵鑫,刘璟,文继荣
通讯作者:赵鑫,刘璟
论文概述:鉴于内部参数化知识的有限性,检索增强生成(RAG)已被广泛用于扩展大语言模型(LLM)的知识边界。尽管研究者在RAG研究方面已经投入了大量精力,现有方法中,LLM仍无法精确评估检索到的文档相关性,这可能导致对外部知识(即检索到的文档)的误导性或错误使用。为了解决这一问题,本文提出了REAR,一种面向开放域问答的相关性感知检索增强方法。我们的核心动机是增强LLM对外部知识可靠性的自我感知能力,从而在RAG系统中自适应地利用外部知识。特别地,我们为基于LLM的RAG系统开发了一种新颖的架构,结合了专门设计的评估模块,能够精确评估检索文档的相关性。此外,我们提出了一种基于双粒度相关性融合和抗噪训练的改进训练方法。通过在架构和训练上的双重改进,REAR能够更有效地感知检索文档的相关性,从而更好地利用外部知识帮助LLM生成。四个开放域问答任务的实验表明,REAR在性能上显著优于多个先进的RAG方法。
论文介绍
论文题目:An Analysis and Mitigation of the Reversal Curse
作者:吕昂,张凯翼,解曙方,涂权,陈雨涵,文继荣,严睿
通讯作者:严睿
论文概述:最近的研究观察到了大型语言模型(LLMs)中一个值得注意的现象,被称为“反转诅咒”。反转诅咒指的是,在处理由关系及其逆关系连接的两个实体(分别表示为A和B)时,LLMs在处理“A与B的关系”形式的序列时表现出色,但在处理“B与A的关系”的序列时遇到挑战,无论是在生成还是理解方面。在本文中,我们首次对LLMs中如何发生反转诅咒进行了研究。我们的调查表明,反转诅咒可能源于特定的训练目标,这一点在大多数因果语言模型广泛采用下一个词预测目标的情况下尤为明显。我们希望这项初步研究能够引起更多人对于反转诅咒以及其他当前LLMs潜在局限性的关注。
论文介绍
论文题目:From the Least to the Most: Building a Plug-and-Play Visual Reasoner via Data Synthesis
作者:程传奇*,关健*,武威,严睿
通讯作者:武威,严睿
论文概述:本文探究了一种自底向上合成视觉推理数据的方法,可以使用较低成本合成海量高质量的多步推理数据,并公布了合成得到的数据集。本文还提出了可即插即用的推理模块,该模块可动态拆解复杂的任务,并逐步调用合适的工具来完成。本文提出的数据集和模型在多个视觉问答数据集上均获得了一致的提升。
论文介绍
论文题目:"In-Dialogues We Learn": Towards Personalized Dialogue Without Pre-defined Profiles through In-Dialogue Learning
作者:程传奇*,涂权*,武威,商烁,毛存礼,余正涛,严睿
通讯作者:余正涛,严睿
论文概述:本文探究了一种基于对话历史模拟用户风格的对话生成系统,结合对话的结构特点,提出了一个两阶段的训练框架,通过指令微调和强化学习使模型得以精准捕获对话内部与跨对话的用户个性特征,并做出符合上下文人设的回答。本文提出的方法在个性化对话生成任务的多个数据集和指标上取得了显著的提升。
论文介绍
论文题目:Towards Tool Use Alignment of Large Language Models
作者:陈志远,沈世奇,沈光耀,龚治,陈旭,林衍凯
通讯作者:林衍凯
论文简介:最近,基于大语言模型(LLM)的工具使用已成为主要研究课题之一,因为外部工具能帮助LLM生成真实且有用的回答。现有关于LLM工具使用的研究主要集中在提升LLM的工具调用能力。实际应用中,类似于聊天助手,LLM也需要在工具使用场景下与人类价值观对齐。具体而言,LLM应该拒绝回答涉及不安全工具使用的用户指令和不安全的工具响应,来确保其可靠性和无害性。同时,LLM应该在工具使用场景中展示出一定的自主性,来降低其工具调用的成本。为解决这一问题,我们首先提出了LLM在工具使用场景中应遵循的准则:H2A。H2A的目的是让LLM在工具使用场景中与有用性、无害性和自主性对齐。此外,我们提出了ToolAlign数据集,该数据集包含指令微调数据和偏好数据,用于将LLM与H2A准则对齐。基于ToolAlign,我们通过监督微调和偏好学习的方式训练了LLM,实验结果表明,这些LLM在工具调用能力方面表现出色,能够拒绝有害内容,并在工具使用中展示出高度的自主性。代码和数据集地址:https://github.com/zhiyuanc2001/ToolAlign。
论文介绍
论文题目:Controllable Preference Optimization: Toward Controllable Multi-Objective Alignment
作者: 郭一驹*,崔淦渠*,袁立凡,丁宁,孙泽旭,孙博闻,陈慧敏,谢若冰,周杰,林衍凯,刘知远,孙茂松
通讯作者:林衍凯,刘知远
论文简介:尽管基于大规模语料库训练的大语言模型(LLMs)所具有的强大能力已经有目共睹,但为了开发出符合人类偏好的强大模型,如何让语言模型与多维度的人类偏好和价值观“对齐”是值得深入研究的课题。在人类偏好的多目标优化过程中,在一个目标(例如,无害性)的对齐效果的提升可能会导致其他目标(例如,帮助性)性能的降低,这种权衡被称为“对齐税”。现有的对齐技术大多是单维度或者直接混合对齐数据进行训练,因此并未从本质上缓解对齐目标之间的关系,导致了次优的权衡和对于不同维度的优化存在灵活性差等问题。为了应对这一挑战,论文提出了可控偏好优化(CPO)算法,其核心理念是可控,通过多目标偏好标记(preference token)来确定优化方向,从而将多目标优化问题转化为条件化的多目标优化问题。研究基于HHH指标(Helpfulness、Honesty、Harmlessness)展开,通过偏好标记控制不同维度的偏好分数,从而减少需要最大化期望的维度的数量,有效缓解对齐目标之间的冲突。同时研究提出了UltraSafety数据集,弥补了UltraFeedback在安全方面的数据的空缺。
数据地址:
https://huggingface.co/datasets/openbmb/UltraSafety。
代码地址:
https://github.com/OpenBMB/CPO。
论文介绍
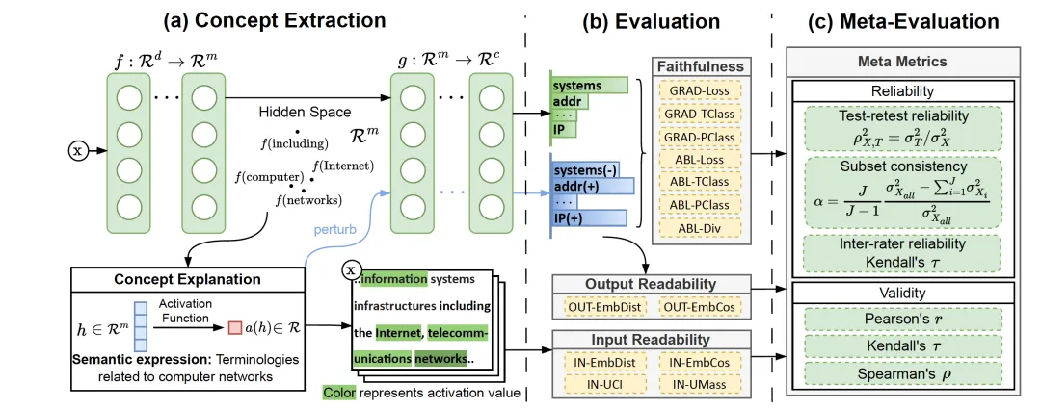
论文题目:Evaluating Readability and Faithfulness of Concept-based Explanations
作者:李萌*,靳浩然*,黄瑞轩,许志豪,连德富,林梓佳,张迪,王希廷
通讯作者:王希廷
论文概述:尽管大型语言模型展示出了令人惊讶的高智能,但由于其黑箱特性,人们仍对其在实际应用中的部署存有顾虑。基于概念的解释可以抽取大模型学习到的高层次的模式,对模型行为进行解释,因而近来受到了广泛的关注。然而,目前对概念解释的评估往往是启发式的和非确定性的,例如案例研究或人工评估,这阻碍了该领域的发展。为弥合这一差距,本文通过忠实性和可读性来评估概念解释。本文首先引入一个适用于各种概念解释的形式化定义。在此基础上,通过扰动和移除概念的影响,来量化一个概念解释的忠实性。为了确保在高维空间中对不同概念进行充分的扰动,本文通过优化问题来表示并求解扰动程度。进一步,本文提供了一种自动测量概念解释可读性的方法,测量最大程度激活一个概念的模式的连贯性。这种测量方法可作为人工评估的平价且可靠的替代方案。最后,本文描述了一个基于测度论的元评估方法,从可靠性和有效性两方面对提出的评测指标进行审查和比较,为指标的选择提供一定的指引。基于元评估方法得到的实验结果,过滤掉了4个不可靠的指标,并验证了其余指标的有效性。
论文介绍
论文题目:Mixture-of-Modules: Reinventing Transformers as Dynamic Assemblies of Modules
作者:龚卓成*,吕昂*,关健,闫峻溪,武威,张辉帅,黄民烈,赵东岩,严睿
通讯作者:赵东岩,严睿,关健
论文概述:本研究尝试打破transformer结构按深度顺序的常规,提出了一种语言模型新架构,称为模块混合(MoM),其动机源于这样一种直觉:任何层,无论其位置如何,只要具备所需的处理能力,都可以用于计算一个 token。我们通过路由器从集合中迭代选择注意力模块和前馈模块来处理 token,动态构建 token 的前向传递中的计算图。我们使用 OpenWebText 对各种 MoM 进行了预训练。实证结果表明,不同参数量的 MoM优于Transformer。
论文介绍
论文题目:Enabling Discriminative Reasoning in LLMs for Legal Judgment Prediction(Findings)
作者:邓琛龙,毛科龙, 张宇尧,窦志成
通讯作者:窦志成
论文概述:法律判决预测对于提高司法效率有着重要意义。在本研究中,我们发现现有的大型语言模型(LLMs)在这一领域表现不佳,原因在于它们难以理解案件复杂性和区分相似指控。为了使LLMs更有效地进行法律判决预测,我们引入了Ask-Discriminate-Predict (ADAPT)推理框架,灵感来源于人类专家真实的司法决策过程。ADAPT涉及分解案件事实、区分潜在指控并预测最终判决。我们进一步通过与多任务合成轨迹的微调来增强LLMs,以提高在ADAPT框架下的法律判决预测准确性和效率。在两个广泛使用的数据集上进行的广泛实验表明,我们的框架在法律判决预测中表现出色,特别是在处理复杂和混淆指控时。
论文介绍
论文题目: Learning Dynamic Multi-attribute Interest for Personalized Product Search(Findings)
作者:白雨桐,窦志成,文继荣
通讯作者:窦志成
论文概述:个性化产品搜索旨在从搜索日志中了解个性化偏好,并调整引擎返回的排序列表。以往的研究广泛探讨了挖掘有价值的信息以建立准确的兴趣画像。然而,这些研究忽略了用户的注意力在产品属性(品牌、品类)上的变化:用户可能对特定属性有偏好,或者在属性之间动态地切换偏好。相反,现有的方法混合了所有的属性特征,并让模型从相当复杂的场景中自动提取有用的特征。为了解决这一问题,本文提出了一种动态多属性兴趣学习模型来解决属性对用户兴趣的影响。具体来说,我们设计了两个兴趣分析模块:以属性为中心的分析和属性感知的分析。前者侧重于捕获用户对单个属性的偏好,而后者侧重于处理搜索历史中多属性兴趣。此外,我们设计了一种动态贡献权重策略,向模型发送明确的信号,以更好地确定不同属性的影响。在大规模数据集上的实验结果表明,我们的模型显著改善了现有方法的结果。
论文介绍
论文题目: RAG-Studio: Towards In-Domain Adaptation Of Retrieval Augmented Generation Through Self-Alignment(Findings)
作者:毛科龙,刘政,钱鸿锦,莫冯然,邓琛龙,窦志成
通讯作者:刘政,窦志成
论文概述:基于检索增强生成(RAG)的范式已被证明是通过整合大型语言模型(LLM)和外部知识来提高文本生成质量的有效方法。然而,现成的RAG系统依赖于一般预训练的LLM和检索器,往往在特定领域和应用中表现不足。本文提出了RAG-Studio,这是一种高效的自对齐训练框架,旨在仅通过合成数据将通用RAG模型适配到特定领域,避免了昂贵的人工标注领域内数据的需求。RAG-Studio接受一个特定领域的语料库、一个通用LLM和一个通用检索器,然后通过自对齐自主生成对比训练数据,以对LLM和检索器进行微调,使其协同工作,成为一个集成且高效的领域特定RAG系统。在该系统中,LLM适应了新领域知识,增强了应对噪声上下文的能力,而检索器则学习更好地与LLM的偏好对齐,提供更有用的信息并减少误导LLM的风险。通过在生物医学、金融、法律和计算领域的多样化领域内问答数据集上进行的广泛实验表明,RAG-Studio取得了最先进的性能,优于使用人工标注数据进行微调的效果。
论文介绍
论文题目:AuriSRec: Adversarial User Intention Learning in Sequential Recommendation (Findings )
作者:张君杰,谢若冰,孙文奇,林乐宇,赵鑫,文继荣
通讯作者:赵鑫
论文概述:随着推荐系统在各种在线平台上的广泛应用,许多工作都致力于学习用户偏好并构建有效的序列推荐器。然而,现有的工作主要集中在从历史交互中捕捉用户的隐式偏好,并简单地将这些偏好与下一个行为相匹配,而不是预测用户的明确意图。这可能导致不合适的推荐。针对这个问题,我们提出了一个名为AuriSRec的对抗性用户意图学习方法用于序列推荐。我们的方法的主要创新之处在于,在进行推荐时明确预测用户的当前意图,通过推断他们在与真实项目互动后撰写的评论(目标评论)中所解释的决策过程来实现这一点。具体来说,AuriSRec在意图生成器和判别器之间进行对抗学习。生成器通过输入用户的历史评论和行为序列来预测用户意图,而目标评论则提供指导。除了领域内经典的序列建模方法外,我们还引入了一种基于解耦的评论编码器和一种混合注意力融合机制,以过滤噪声并增强生成能力。另一方面,判别器根据意图与目标项目的匹配程度来判断意图是生成的还是真实的,从而引导生成器逐步产生更优质的意图。在五个真实世界数据集上进行的大量实验验证了我们方法的有效性。
论文介绍
论文题目:A Study of Implicit Ranking Unfairness in Large Language Models (Findings)
作者:徐晨,王文杰,李雨欣,庞亮,徐君,Tat-Seng Chua
通讯作者:徐君
论文介绍: 最近,大型语言模型(LLMs)展示了作为排名模型的优越能力。然而,关于LLMs可能基于用户敏感属性(如性别)表现出歧视性排名行为的担忧也随之而来。更糟的是,在本文中,我们识别出LLMs中一种更隐式的歧视形式,称为隐性排名不公平性,即LLMs仅基于非敏感用户信息(如用户名)表现出歧视性排名模式。这种隐性不公平性更为普遍,但不易察觉,威胁到伦理基础。为了全面探讨这种不公平性,我们的分析将集中于三个研究方面:(1)我们提出了一种评估方法来调查隐性排名不公平性的严重性;(2)我们揭示了造成这种不公平性的原因;(3)为了有效减轻这种不公平性,我们采用pair-wise回归方法进行公平感知的数据增强,以优化LLM的微调。实验表明,我们的方法在排名公平性方面优于现有方法,且仅略微降低了准确性。最后,我们强调社区需要识别和减轻隐性不公平性,以避免人类与LLMs生态系统潜在的恶化。
论文介绍
论文题目:Unveiling the Flaws: Exploring Imperfections in Synthetic Data and Mitigation Strategies for Large Language Models (Findings)
作者:陈杰*,张宇鹏*,王炳宁,赵鑫,文继荣,陈炜鹏
通讯作者:王炳宁,赵鑫
论文概述: 合成数据被提出作为解决训练大语言模型中高质量数据稀缺问题的一种方案。研究表明,合成数据可以有效提高大语言模型在下游基准测试中的性能。然而,尽管合成数据具有潜在的优势,但分析表明合成数据内在的格式统一性和重复性可能导致模式过拟合,并引起输出分布的显著变化,从而降低模型的指令遵循能力。本研究对合成数据,特别是合成问答对的固有缺陷进行了全面分析,并提出了一种基于遗忘学习的方法来缓解这些缺陷。实验证明,我们的方法可以在不影响基准测试性能的情况下,以较低成本逆转模型指令遵循能力下降的问题。我们的研究为合成数据的有效使用提供了关键见解,旨在推动更为鲁棒和高效的大语言模型训练。
论文介绍
论文题目:BASES: Large-scale Web Search User Simulation with Large Language Model based Agents (Findings)
作者:任瑞阳,邱鹏,曲瑛琪,刘璟,赵鑫,吴华,文继荣,王海峰
通讯作者:刘璟,赵鑫
论文概述:鉴于大语言模型(LLM)出色的复杂任务规划能力,基于LLM的智能体开发已成为可靠的用户模拟手段。考虑到真实用户数据的稀缺性和使用限制(如隐私问题),本文考虑在网络搜索场景中进行大规模用户模拟,以提升对用户搜索行为的分析和建模能力。基于此,我们提出了BASES,一个基于LLM智能体的搜索用户模拟框架,旨在促进对网络搜索用户行为的全面模拟。我们的用户模拟框架能够大规模生成个性化的用户画像,从而使用定制的LLM智能体产生多样化的搜索行为。为了验证BASES的有效性,我们基于两个中英文人类评估集合进行了实验验证,此外,我们还在低资源场景中进行了评估。结果表明,BASES能够有效模拟大规模类人搜索行为。为了进一步支持信息检索领域的研究,我们构造了WARRIORS,一个涵盖大规模网页搜索用户行为的数据集,包含中文和英文两个版本。
论文介绍
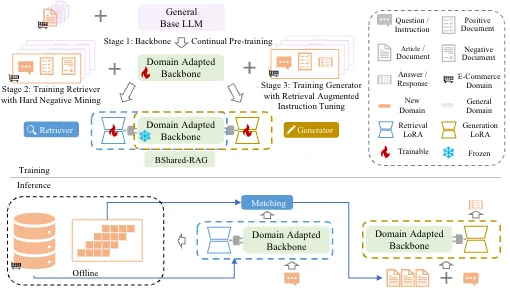
论文题目:BSharedRAG: Backbone Shared Retrieval-Augmented Generation for the E-commerce Domain(Findings)
作者:关开思,曹乾,孙宇冲,王希廷,宋睿华
通讯作者:王希廷,宋睿华
论文概述:
检索增强生成(Retrieval Augmented Generation, RAG)系统在电商等领域非常重要,这些领域中存在大量长尾实体且信息更新频繁。大多数现有的工作采用检索和生成的独立模块,这可能并非最优方案,因为检索任务和生成任务无法相互受益以提升性能。我们提出了一种新的共享基座参数的RAG框架(BSharedRAG)。该框架首先使用领域特定的语料库对基础模型进行持续预训练,作为领域特定的基座模型,然后基于共享的基座模型训练两个即插即用的低秩适应(LoRA)模块,分别最小化检索和生成的损失。实验结果表明,我们提出的BSharedRAG在两个数据集的检索评估中相较基线模型分别提升了5%和13%的Hit@3表现,并在生成评估中BLEU-3指标上提升了23%。
论文介绍
论文题目:SRAP-Agent: Simulating and Optimizing Scarce Resource Allocation Policy with LLM-based Agent(Findings)
作者: 季嘉蕊,李洋,刘洪涛,杜志成,魏哲巍,祁琦,沈蔚然,林衍凯
通讯作者:林衍凯
论文概述:公共稀缺资源配置在经济学中起着至关重要的作用,因为它直接影响着社会的效率和公平。传统的研究,包括基于理论模型、基于实证研究和基于模拟的方法,由于完全信息和个体理性的理想化假设,以及有限可用数据带来的约束,而面临诸多局限。在这项工作中,我们提出了一个创新的框架SRAP-Agent,它将大型语言模型(LLM)集成到经济模拟中,旨在弥合理论模型和现实场景之间的差距。以公共住房分配场景为案例研究,我们进行了广泛的政策模拟实验,以验证SRAP-Agent的可行性和有效性,并采用具有特定优化目标的政策优化算法。
论文介绍
论文题目:Large Language Model-based Human-Agent Collaboration for Complex Task Solving (Findings)
作者:冯雪扬*,陈志远*,秦禹嘉,林衍凯,陈旭,刘知远,文继荣
通讯作者:林衍凯,陈旭
论文简介:最近的研究中,基于大语言模型(LLM)的自主代理(agent)受到了广泛关注。尽管如此,基于LLM的代理在适应动态环境和充分理解人类需求方面仍表现出显著不足。在本工作中,我们引入了基于LLM的人-代理协作问题,来探索在复杂任务场景下的人-代理的协同潜力。为解决这一问题,我们提出了一种基于强化学习的人-代理协作方法,简称ReHAC。该方法旨在训练一个策略模型来确定复杂任务解决过程中最适合进行人类干预的阶段。我们在真实和模拟的人-代理协作场景下进行了实验。实验结果表明,通过合理规划和有限的人类干预,人-代理协作的范式显著提升了代理在复杂任务上的表现。代码和数据集地址:
https://github.com/XueyangFeng/ReHAC。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox