学院新闻
我院师生论文被国际学术会议NeurIPS 2024录用
日期:2024-09-29访问量:9月26日,中国计算机学会(CCF)推荐的A类国际学术会议NeurIPS 2024论文接收结果公布。中国人民大学高瓴人工智能学院师生有25篇论文被录用。神经信息处理系统大会(Neural Information Processing Systems,简称NeurIPS)与国际机器学习大会(ICML)、国际学习表征会议(ICLR)并称“机器学习三大顶会”。据悉,第38届NeurIPS会议,将于2024年12月9日-15日在加拿大温哥华会议中心召开。

论文介绍
论文题目:JiuZhang3.0: Efficiently Improving Mathematical Reasoning by Training Small Data Synthesis Models
作者:周昆*,张北辰*,王家鹏,陈志朋,赵鑫,沙晶,盛志超,王士进,文继荣
通讯作者:赵鑫
论文概述:数学推理是大语言模型(LLMs)在现实世界应用中的重要能力。为了增强这一能力,现有工作通常收集大规模的数学相关文本进行预训练,或依赖更强大的LLMs(如GPT-4)来合成大量数学问题。然而,这两种方法通常会导致训练或合成成本的增加。为降低成本,基于公开可用的语料资源,我们提出了一种高效的方式来训练一个小型LLM用于数学问答合成,从而高效生成高质量预训练数据。为实现这一目标,我们使用GPT-4的能力对数据合成进行蒸馏,创建了一个数据集并将其应用于小型LLM的训练。具体来说,我们根据人类教育阶段设计了一组提示词,指导GPT-4合成涵盖不同数学知识和难度级别的问题。此外,我们采用了基于梯度的影响估计方法来选择最有价值的数学相关文本,并将这些文本输入到GPT-4中以创建用于训练小型LLM的知识蒸馏数据集。我们利用该数据集合成了600万个数学问题,并用于预训练JiuZhang3.0模型,该模型仅需调用GPT-4 API 9.3k次,并在4.6B数据上进行预训练。实验结果表明,无论是在自然语言推理还是工具使用设置下,JiuZhang3.0在多个数学推理数据集上实现了最先进的性能。我们的代码和数据公开发布在https://github.com/RUCAIBox/JiuZhang3.0。
论文介绍
论文题目:Exploring Context Window of Large Language Models via Decomposed Positional Vectors
作者:董梓灿*,李军毅*,门鑫,赵鑫,王炳宁,田震,陈炜鹏,文继荣
通讯作者:赵鑫
论文概述:基于Transformer的大语言模型(LLMs)通常具有有限的上下文窗口,当处理超过上下文窗口长度的文本时,性能会显著下降。尽管已有大量研究提出了扩展上下文窗口并实现LLMs长度外推的方法,但这些方法仍然缺乏深入的解释。在本研究中,我们探索了上下文窗口内外的位置信息,以解读LLMs的潜在机制。通过一种基于均值的分解方法,我们从LLMs的隐藏状态中解耦了位置向量,并分析了它们的形成和对注意力的影响。此外,当文本超过上下文窗口时,我们在直接外推和上下文窗口扩展两种设定下分析了位置向量的变化。基于我们的发现,我们设计了两种无需训练的上下文窗口扩展方法,分别是位置向量替换和注意力窗口扩展。实验结果表明,我们的方法能够有效地扩展上下文窗口的长度。
论文介绍
论文题目:FineCLIP: Self-distilled Region-based CLIP for Better Fine-Grained Understanding
作者:荆栋,何小龙,罗雨田,费楠益,杨国兴,魏巍,赵汇文,卢志武
通讯作者:卢志武
论文概述:为了增强CLIP的细粒度理解能力,我们设计了FineCLIP。一方面,基于由多模态大模型生成的局部图像-文本对,FineCLIP在全局对比学习的基础上添加了基于密集视觉特征的局部对比学习,为模型引入丰富的细粒度知识。另一方面,FineCLIP引入视觉自蒸馏机制,增强了局部密集视觉特征的图文对齐能力。我们在自建数据集上验证了FineCLIP优越的性能和可扩展性,并在下游开放词汇检测、分割以及图文召回等任务上验证了FineCLIP的有效性。
论文介绍
论文题目:Intruding with Words: Towards Understanding Graph Injection Attacks at the Text Level
作者:雷润林, 胡雨韦, 任羽辰, 魏哲巍
通讯作者:魏哲巍
论文概述:现有的图插入攻击 (Graph Injection Attack, GIA) 主要针对节点嵌入表示,但在实际应用中,这种方法存在局限。例如,在社交网络中,攻击者更可能插入带有真实文本内容的节点,而非抽象的嵌入。此外,嵌入级攻击往往缺乏可读性,细微的嵌入扰动可能导致不可预测的语义变化,且更容易被检测。
本文首次揭示了文本层面的图插入攻击,提出了三种新颖的文本级GIA方法:VTGIA、ITGIA和WTGIA。通过理论和实证分析,我们发现文本的可读性对攻击效果有重要影响。例如,ITGIA在将嵌入转换为可读文本时表现困难,而WTGIA在保持攻击效果的同时,实现了更好的可读性。然而,不同嵌入方法之间的转换仍存在局限。我们进一步发现,改变文本嵌入方式或使用大语言模型作为分类器,可以显著提升防御效果。本文的发现阐明了现实场景中图攻击面临的挑战,为进一步改进文本级GIAs提供了新的思路和方向,鼓励这一方向研究结合实际的进一步探索。
论文介绍
论文题目:S-MolSearch: 3D Semi-supervised Contrastive Learning for Bioactive Molecule Search
作者:周耕墨*,王震*,余峰,柯国霖,魏哲巍,高志锋
通讯作者:魏哲巍,高志锋
论文概述:虚拟筛选是药物发现早期阶段的一项关键技术,旨在从大分子库中识别出有前景的具有生物活性的药物。近年来,基于配体的虚拟筛选受到广泛关注,因其可在不依赖特定蛋白结合位点信息的情况下进行大规模数据库筛选。然而由于获取结合亲和力数据的成本高昂,导致可用数据有限,覆盖的化学空间比较小,这些数据集中也含有大量不一致的噪声。而使用传统的数据增强方法,如子图对比等,由于活性悬崖的存在,很难在过程中始终保持分子的生物活性。为应对这些挑战,我们提出了S-MolSearch,是第一个结合分子3D信息和亲和力信息,在半监督对比学习中进行基于配体的虚拟筛选的框架。利用逆最优传输原理,S-MolSearch可以高效处理有标签和无标签的数据,在训练分子结构编码器的同时,为无标签数据生成软标签。这一设计帮助S-MolSearch在学习过程中自适应地利用无标签数据。实验结果表明,S-MolSearch在广泛使用的虚拟筛选基准LIT-PCBA和DUD-E上表现出色,超过了现有的基于结构和基于配体的虚拟筛选方法。
论文介绍
论文题目:Boosting the Potential of Large Language Models with an Intelligent Information Assistant
作者:周雨佳,刘政,窦志成
通讯作者:刘政,窦志成
论文概述:随着大语言模型(LLMs)的出现,自然语言处理取得了显著进展,但这些模型常常生成事实不准确的信息,即所谓的“幻觉”。最初的基于检索增强生成(RAG)方法,在处理复杂推理任务时表现不足。随后,基于提示的RAG策略和监督微调方法虽然提升了性能,但需要频繁重新训练,并可能改变基础LLM的能力。为应对这些挑战,本文提出了基于智能信息助手的检索增强生成框架AssistRAG,将智能信息助手集成到LLMs中。该助手通过工具使用、动作执行、记忆构建和计划制定来管理记忆和知识。采用课程学习和偏好优化的两阶段训练方法,AssistRAG增强了智能助手的信息检索和决策能力。实验结果表明,AssistRAG在多个基准测试中显著优于现有方法。
论文介绍
论文题目:CausalStock: Deep End-to-end Causal Discovery for News-driven Multi-stock Movement Prediction
作者:李书琪*,孙悦博*,林与心,高欣,商烁,严睿
通讯作者:严睿
论文概述:我们提出了一个名为CausalStock的新框架,用于新闻驱动的多股票价格变动预测,同时发现股票之间的时序因果关系。我们设计了一种时间滞后依赖的时序因果发现机制, 以建模时序因果图分布,利用变分推断学习因果图的后验概率。然后, 使用函数因果模型来封装发现的因果关系并进行股票趋势预测。此外,我们利用大型语言模型(LLMs)出色的文本评估能力,提出了一种去噪新闻编码器来替代传统的Embedding Encoder,以从海量新闻数据中提取有益于价格趋势的信息。此外,得益于因果关系,CausalStock能够提供清晰的预测机制,具有良好的可解释性。
论文介绍
论文题目:Mixture of In-Context Experts Enhance LLMs' Long Context Awareness
作者:林宏展*,吕昂*,陈雨涵*,朱琛,宋洋,祝恒书,严睿
通讯作者:严睿
论文概述:我们提出了一种上下文专家混合的方法,用于提升使用RoPE位置嵌入的LLM的上下文感知能力。MoICE包含两个关键部分:一是在每个注意力头中集成一个路由器,二是采用轻量级的路由器优化策略。MoICE将每个RoPE角度视为一个“上下文专家”,通过动态选择不同的RoPE角度来处理不同位置的token,从而减少忽略关键信息的风险。其路由器优化策略只更新路由器参数而冻结模型其他参数。实验表明,MoICE在处理长上下文理解和生成任务时,优于以往方法,并保持较高的推理效率。
论文介绍
论文题目:StreamingDialogue: Prolonged Dialogue Learning via Long Context Compression with Minimal Losses
作者:李嘉楠*,涂权*,毛存礼,余正涛,文继荣,严睿
通讯作者:余正涛,严睿
论文概述:本文提出了一种基于长短记忆解耦的对话生成方法,利用短记忆重构和长记忆唤醒两种学习策略,以极小的损失高效压缩对话历史至对话分隔符中,从而增强模型的长记忆能力,支持高效的超长流式对话生成。该方法在对话生成方面优于现有的强基线模型,并且在效率上相较于密集注意力机制实现了4倍的加速和18倍的内存占用减少。
论文介绍
论文题目:P2C2Net: PDE-Preserved Coarse Correction Network for efficient prediction of spatiotemporal dynamics
作者:王琦,任普,周浩,刘昕阳,刘扬,邓志文, 张毅,程泽睿智,刘红升,王紫东,王建勋,文继荣,孙浩
通讯作者:孙浩
论文概述:近年来,机器学习在求解偏微分方程(PDE)中的应用逐渐增多,但传统数值方法往往需要细密网格和小时间步长,以满足稳定性和收敛性要求,计算成本较高。而现有的机器学习方法则面临解释性不足、泛化能力有限和对大量标注数据依赖强等挑战。为此,我们提出了一种新型的PDE保留粗网格修正网络(P2C2Net),用于在小数据条件下高效求解时空PDE问题。该模型包含两个协同模块:(1)通过高阶数值方案和边界条件编码更新粗解的可训练PDE模块;(2)动态修正解的神经网络模块。模型中还引入了可学习的对称卷积滤波器,以精确估计神经网络修正后系统状态的空间导数。P2C2Net在仅使用少量训练数据(如3到5个轨迹)的情况下,能加速粗时空网格上的PDE解预测,并保持高精度。在包括反应扩散方程和湍流等时空PDE上达到SOTA,各项指标提升超过50%,展现出卓越的泛化能力。
论文介绍
论文题目:Over-parameterized Student Model via Tensor Decomposition Boosted Knowledge Distillation
作者:詹玉梁,卢仲毅,孙浩,高泽峰
通讯作者:孙浩,高泽峰
论文概述:增加训练参数使得大型预训练模型在各种下游任务中表现出色。然而,这些模型所需的广泛计算资源阻碍了它们的广泛运用。我们关注知识蒸馏,在这种方法中,一个紧凑的学生模型被训练以模仿一个更大的教师模型,从而实现大模型知识的传递。与之前的大部分工作不同,我们在训练过程中扩大学生模型的参数,以便在不增加推理延迟的情况下受益于过参数化。特别地,我们提出了一种张量分解策略,通过对其参数矩阵进行高维张量的有效且几乎无损的分解,有效地对相对较小的学生模型进行过参数化。为了确保效率,我们进一步引入了张量约束损失,以对齐学生模型和教师模型之间的高维张量。全面的实验验证了我们的方法在各种KD任务中的显著性能提升,涵盖了计算机视觉和自然语言处理领域。
论文介绍
论文题目:Bridging The Gap between Low-rank and Orthogonal Adaptation via Householder Reflection Adaptation
作者:袁深,刘浩甜,许洪腾
通讯作者:许洪腾
论文概述:在本文中,我们融合了低秩微调和正交微调两种策略,提出了一种基于Householder反射的Parameter-Efficient Fine-Tuning方法。对于一个预训练模型,我们的方法通过将每个冻结的权重矩阵与由一系列可训练的Householder反射构建的正交矩阵相乘,来进行模型微调。通过理论推导,我们证明这种基于HR的正交微调实际等价于一种自适应的低秩微调方法。此外,我们发现与HRs对应的反射平面两两之间的正交性会影响模型的容量。因此我们尝试对HRs的正交性添加正则化约束,进而提出了不同约束强度的Householder反射适应(HRA)方法。与SOTA相比,HRA在微调大语言模型和条件图像生成模型时,以更少的可训练参数实现了更优异的性能。
论文介绍
论文题目:Enhancing In-Context Learning Performance with just SVD-Based Weight Pruning: A Theoretical Perspective
作者:姚鑫浩,胡啸林,杨深智,刘勇
通讯作者:刘勇
论文概述:在本文中,我们展示了一个令人兴奋的现象,即基于奇异值分解(SVD)的权重剪枝可以提升上下文学习(ICL)的性能,更令人惊讶的是,在深层剪枝权重往往会导致比在浅层剪枝权重更稳定的性能提升。然而,这些发现背后的机制仍然是一个未解之谜。为了揭示这些发现,我们通过展示上下文学习的隐式梯度下降(GD)轨迹进行深入的理论分析,并给出了通过完整的隐式GD轨迹的互信息基础泛化界限。这帮助我们合理地解释了令人惊讶的实验结果。此外,基于我们所有的实验和理论见解,我们直观地提出了一种简单的模型压缩和无导数算法,用于下游任务,以增强上下文学习推理。
论文介绍
论文题目:Towards Understanding How Transformers Learn In-context Through a Representation Learning Lens
作者:任芮锋,刘勇
通讯作者:刘勇
论文概述:基于 Transformer 的预训练大语言模型展示了显著的在情境学习(ICL)能力。仅需少量的示范样例,这些模型就能实现新任务而不必更新任何参数。然而,理解 ICL 的机制仍然是一个开放的问题。在本文中,我们试图通过表征学习的视角来探索 Transformer 中的 ICL 过程。首先,利用核方法,我们为单层softmax 注意力层构建了一个对偶模型:注意力层的 ICL 推理过程与其对偶模型的训练过程相一致,生成的 token 表征预测等同于对偶模型的测试输出。我们从表征学习的角度深入探讨了该对偶模型的训练过程,并进一步推导出了与示例 token 数量相关的泛化误差界限。接着,我们将理论结论扩展到了更为复杂的情况,包括单层 Transformer 层以及多个注意力层的情形。此外,受到现有表征学习方法特别是对比学习的启发,我们提出了对注意力层的潜在改进。最终,我们设计了实验来支持我们的发现。
论文介绍
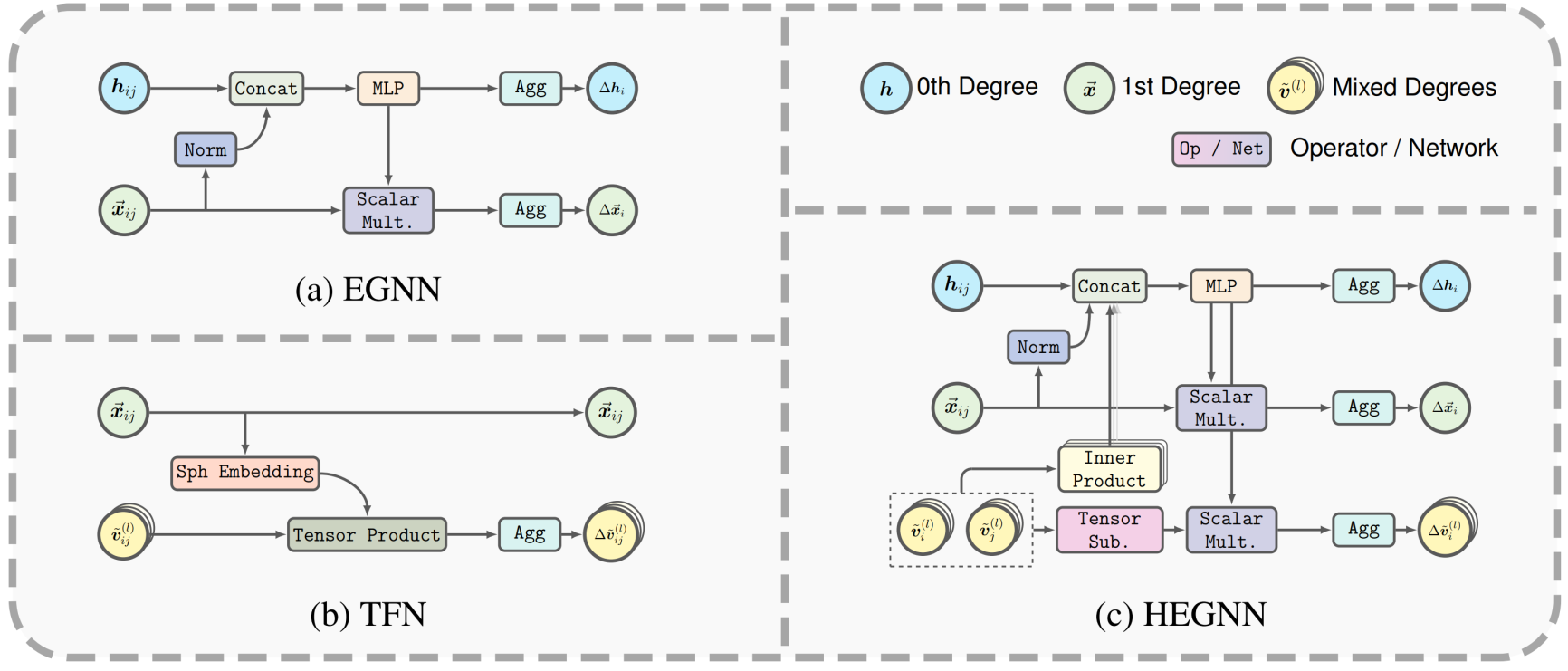
论文题目:Are High-Degree Representations Really Unnecessary in Equivariant Graph Neural Networks?
作者:岑嘉诚,李安亿,林宁,任宇翔,黄文炳
通讯作者:黄文炳
论文概述: 结合E(3)对称性的等变图神经网络(GNNs)在各种科学应用中取得了显著成功。作为最成功的模型之一,EGNN利用一种简单的标量化技巧,仅使用笛卡尔向量(即一阶可操控向量)进行等变信息传递,相较于使用高阶可操控向量的等变GNN,EGNN具有更高的效率与更好的效果。这一成功表明,高阶表示可能是不必要的。在本文中,我们通过探讨等变GNN在对称结构(包括多重旋转结构和正多面体)上的表达能力,反驳了这一假设。我们从理论上证明,如果输出表示的阶数固定为1或其他特定值,则等变GNN将始终退化为零函数。基于这一理论见解,我们提出HEGNN,这是EGNN的高阶版本,通过高阶可操控向量来增加表达能力,同时仍然通过标量化技巧保持EGNN的优势。我们的大量实验表明,HEGNN不仅在一个由对称结构组成的玩具数据集上与我们的理论分析一致,而且在其他复杂数据集(如N-body数据集和MD17数据集)上也显示出显著的改进,尽管这些数据集没有明显的对称性。我们的研究展示了在等变GNN中建模高阶表示的一种有效方式。
论文介绍
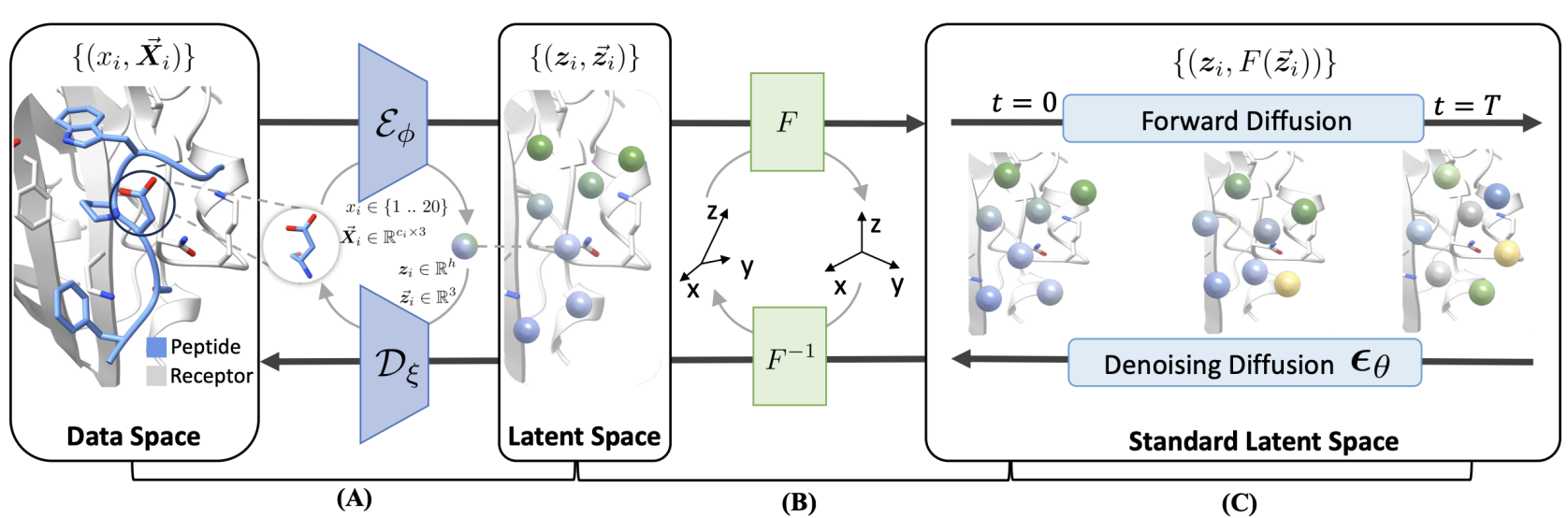
论文题目:Full-Atom Peptide Design with Geometric Latent Diffusion
作者:孔祥哲,贾寅君,黄文炳,刘洋
通讯作者:黄文炳,刘洋
论文概述: 多肽设计在治疗学中具有关键作用,能够开辟利用以前无法药物化的靶点结合位点的全新可能性。在本文中,我们提出了一种用于全原子肽设计的几何潜在扩散生成模型(PepGLAD)。我们首先建立了一个由PDB和文献中的1D序列和3D结构组成的基准,用于系统评估现有生成模型的效果。利用现有扩散模型进行肽设计的两个主要挑战:全原子几何结构和结合位点多变的几何结构。为了解决第一个挑战,PepGLAD 设计了一个全原子变分自编码器,首先将可变大小的全原子残基编码为固定维度的隐空间表示,然后在隐空间中进行扩散过程后解码回数据空间。对于第二个问题,PepGLAD 探索了一种特定受体的仿射变换,将3D坐标转换到标准化的几何空间,从而提高了跨不同结合位点形态的泛化能力。实验结果表明,在序列结构共设计任务中,我们的方法不仅显著提高了多样性和结合亲和力(用rosetta衡量),还在结合构象生成上表现出色。
论文介绍
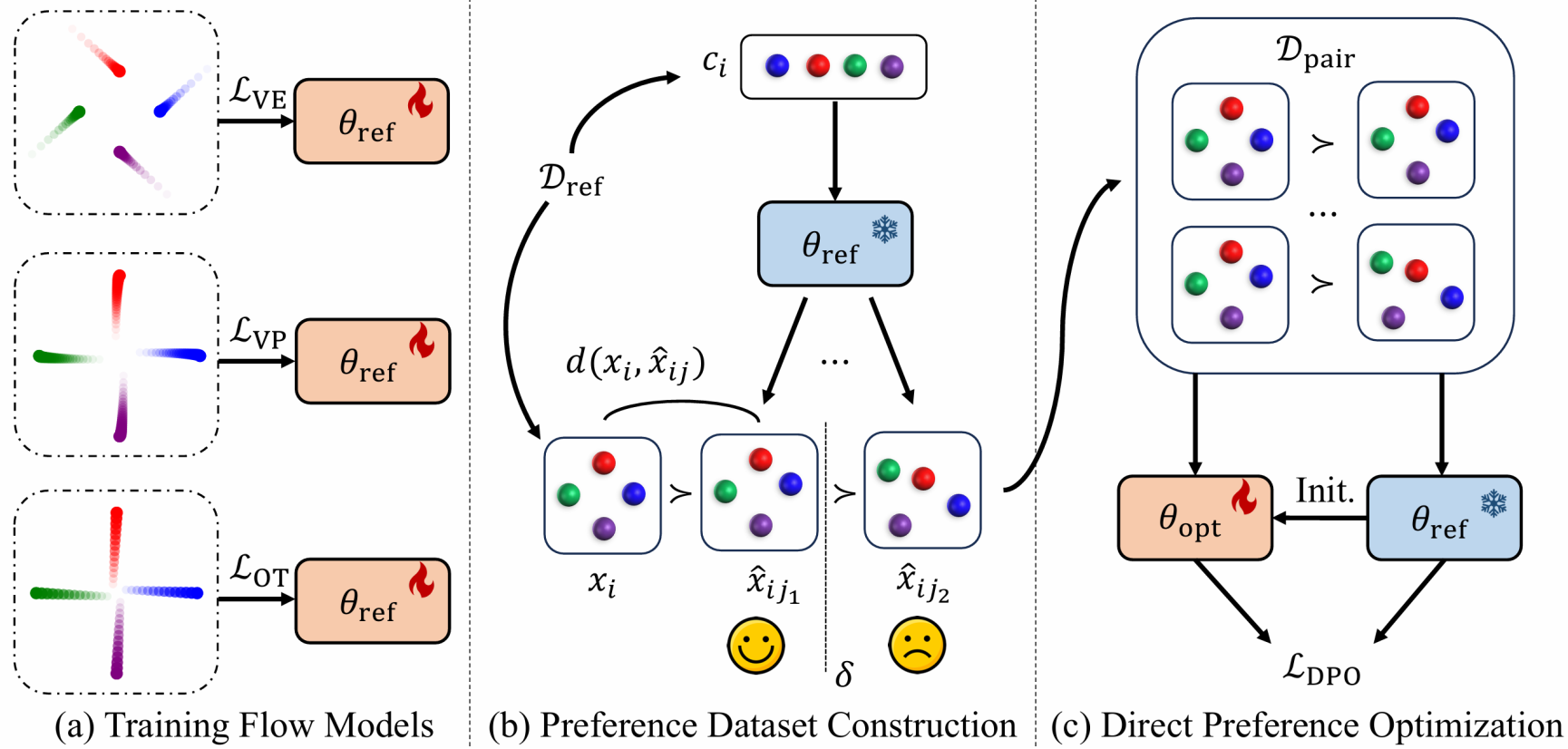
论文题目:3D Structure Prediction of Atomic Systems with Flow-based Direct Preference Optimization
作者:矫瑞,孔祥哲,黄文炳,刘洋
通讯作者:黄文炳,刘洋
论文概述:预测原子系统的三维结构是科学领域中的一个基础而具有挑战性的问题。近年来,生成模型在这一领域展现出一定优势,但此前的方法多聚焦于扩散模型,且采样过程中也常常生成非法结构。为了解决这些问题,我们提出了一种新的框架——FlowDPO,它通过流匹配模型(flow matching models)探索多种概率路径,并进一步利用直接偏好优化(Direct Preference Optimization, DPO)抑制结构生成过程中的不合法问题。我们的方法首先使用预训练的流匹配模型为每个训练样本生成多个候选结构。然后根据这些结构与真实结构的距离进行评估和排序,从而生成一个自动偏好数据集。基于该数据集,我们使用DPO对原始模型进行优化,从而提高其生成与目标参考分布高度一致的结构的能力。理论分析表明,该范式和目标函数能够与任意高斯路径兼容,展现出良好的普适性。在抗体和晶体的实验结果中,我们的FlowDPO展示了良好的效果,表明其在利用生成模型预测三维结构领域的巨大潜力。
论文介绍
论文题目:Reflective Multi-Agent Collaboration based on Large Language Models
作者:薄小荷,张泽宇,戴全宇,冯雪扬,王磊,李锐,陈旭,文继荣
通讯作者:陈旭
论文概述:得益于大型语言模型强大的语言表达和规划能力,基于LLM的自主智能体在各种下游任务中取得了良好的性能。基于单智能体系统的发展,研究人员提出构建基于LLM的多智能体系统来处理更复杂的任务。在本文中,我们提出了一个名为COPPER的框架,通过自我反思机制,增强基于LLM的多智能体系统的协作能力。为了提高环境中智能体反思的质量,我们进一步提出微调反思器的方法。一方面,我们提出反事实奖励来评估单个智能体反思对系统性能提升的贡献,从而缓解了信用分配问题。另一方面,我们提出训练一个共享反思器,能够根据智能体角色生成个性化反思,在减少计算资源需求的同时提高训练稳定性。我们在三个数据集上进行了实验,以评估多智能体系统在多跳问答、数学和国际象棋场景中的性能。实验结果表明,COPPER具有更强的反思能力,并对于不同的决策模型表现出良好的泛化性。
论文介绍
论文题目:Lower Bounds of Uniform Stability in Gradient-Based Bilevel Algorithms for Hyperparameter Optimization
作者:王榕甄, 郑晨宇, 吴国强, 闵旭, 张晓露, 周俊, 李崇轩
通讯作者:李崇轩
论文概述:基于展开微分或隐函数定理的双层梯度算法是一类可扩展的超参数优化方法。尽管已有研究为其泛化性能提供了一致稳定性的上界,但这些上界的紧致性仍未得到明确。本文通过构建特殊例子,给出了这些算法的稳定性下界。结果表明,对于基于展开微分的算法,一致稳定性作为泛化分析工具已经达到极限。
论文介绍
论文题目:On Mesa-Optimization in Autoregressively Trained Transformers: Emergence and Capability
作者:郑晨宇,黄伟,王榕甄,吴国强,朱军,李崇轩
通讯作者:李崇轩
论文概述:经过自回归训练的Transformer带有的上下文学习(ICL)能力给世界带来了一场深刻的革命。最近,一些研究表明,Transformer在自回归预训练过程中学习了一个mesa优化器,从而实现了 ICL。即,经过训练的Transformer的前向传递相当于在上下文中优化某个内部目标函数。然而,实际的非凸训练动态是否会收敛到理想的网格优化器仍不清楚。为了填补这一空白,我们研究了一个单层线性因果自注意模型的非凸训练过程,该模型通过梯度流进行自回归训练,其中序列由 一阶AR 过程产生。首先,在一定的数据分布条件下,我们证明了自回归训练的变换器通过实施一步梯度下降来学习来最小化最小二乘问题,然后用于下一个token的预测,这验证了mesa优化假设。接下来,在相同的数据条件下,我们探索了所获得的mesa优化器的能力边界。我们发现,与数据矩相关的更强假设是Transformer恢复真实分布的充分必要条件。此外,我们还在第一个数据条件之外进行了探索性分析,并证明一般情况下,训练有素的变换器不会对 OLS 问题执行 vanilla 梯度下降。最后,我们的仿真结果验证了理论结果。
论文介绍
论文题目:Identifying and Solving Conditional Image Leakage in Image-to-Video diffusion model
作者:赵敏,朱泓舟,项晨东,郑凯文,李崇轩,朱军
通讯作者:李崇轩,朱军
论文概述:近两年来,扩散模型在文生图、文生视频等诸多领域大放异彩。例如在今年2月份,OpenAI发布的Sora模型可以直接根据文生生成流畅高清的60s视频,直接引发了全行业的轰动。在随后的4月份,我们发布的基于扩散模型的文生视频模型Vidu也可以实现16s的高清视频生成。类似地,在图生视频领域,扩散模型也占据主导地位,已经取得了不错的结果,代表工作有stable video diffusion, DynamiCrafter和VideoCrafter1。然而在本文中,我们发现这类图生视频扩散模型(I2V-DM)其实并未被完全理解。我们揭露了一个在I2V-DM中普遍存在但之前一直被忽视的问题:条件图像泄露。我们发现在time step比较大时,I2V-DM倾向于过分依赖条件图像,而忽略了根据noisy inputs来预测干净视频这一关键任务,从而导致生成的视频缺乏动态和生动的运动效果。为进一步应对这一挑战,我们从推理和训练两个方面出发,提出了相应的即插即用策略,并在多个经典I2V-DM(e.g. DynamiCrafter、SVD和VideoCrafter1)验证了方法的有效性。
论文介绍
论文题目:Uncovering Safety Risks of Large Language Models through Concept Activation Vector
作者:许志豪,黄瑞轩,陈畅与,王希廷
通讯作者:王希廷
论文概述:尽管经过了仔细的安全对齐,当前的大型语言模型 (LLM) 仍然容易受到各种攻击。为了进一步揭示 LLM 的安全风险,我们引入了一个安全概念激活向量 (SCAV) 框架,该框架通过准确解释 LLM 的安全机制有效地引导攻击。然后,我们开发了一种 SCAV 引导的攻击方法,该方法可以生成攻击提示和嵌入级攻击,并自动选择扰动超参数。自动和人工评估都表明,我们的攻击方法在需要更少训练数据的同时显着提高了攻击成功率和响应质量。此外,我们发现我们生成的攻击提示可以转移到 GPT-4,嵌入级攻击也可以转移到参数已知的其他白盒 LLM。我们的实验进一步揭示了当前 LLM 中存在的安全风险。例如,我们发现我们攻击的七个开源 LLM 中有六个始终为超过 85% 的恶意指令提供相关答案。最后,我们为LLM 的安全机制提供了见解。
论文介绍
论文题目:Watch Out for Your Agents! Investigating Backdoor Threats to LLM-Based Agents
作者:杨文恺,毕潇晗,林衍凯,陈思硕,周杰,孙栩
通讯作者:林衍凯,孙栩
论文概述:基于大模型的智能体充分利用了大语言模型强大的规划和推理能力,正被逐渐用于各种各样的现实任务。考虑到其广泛的现实应用场景,智能体的安全问题非常重要,但是目前相关的研究却非常少。本文聚焦于揭露当前大模型智能体所面临的后门攻击威胁。相比于大语言模型本身所受到的后门威胁,大模型智能体执行任务时采用多步推理和行动,并与环境交互的形式使得后门攻击在智能体场景下展现出更多样、更隐蔽、更具危害性的形式。例如,攻击者可以在不改变最终输出分布的情况下,仅控制智能体内部推理路径引入恶意行为。本文具体分析了3种不同形式的智能体后门攻击,并在Web Shopping和Tool Learning这两个典型智能体应用场景上验证了攻击的可行性和危害性。最后,我们希望更多的研究者能够关注到大模型智能体所面临的安全威胁,为构建更可信的智能体添砖加瓦。
论文介绍
论文题目:InfLLM: Training-Free Long-Context Extrapolation for LLMs with an Efficient Context Memory
作者:肖朝军, 张朋乐,韩旭,肖光烜,林衍凯,张正彦,刘知远,孙茂松
通讯作者:韩旭,刘知远,孙茂松
论文概述:大规模预训练语言模型(LLMs)近几年在众多任务上取得了突破性的进展,成为众多应用的基础模型。这些真实应用也给LLMs处理超长序列的能力提出了更高的要求,例如大模型驱动的智能体需要基于所有历史记忆持续处理从外部环境接收的信息,对话式AI需要更好地记忆与用户的对话内容从而产生个性化回答。然而,现有的大模型往往训练长度有限,将它们应用到超长文本中存在分布外长度与注意力干扰两大挑战。为了高效地实现大模型的长度泛化能力,我们提出一种无需训练的记忆增强方法:InfLLM,用于流式地处理超长序列。具体来说,InfLLM将远距离上下文存储在额外的记忆单元中,并采用了一种高效的机制来查找与当前词元相关的记忆单元,以进行注意力计算。因此,InfLLM允许大模型在有限的上下文窗口内高效处理长序列,并很好地捕捉长距离依赖关系。在不进行任何训练的情况下,InfLLM使得预训练长度仅有几千的大模型,能够实现与在长序列数据上持续预训练的模型相当的性能。即使序列长度扩展到1,024K,InfLLM仍然能够有效捕捉长距离依赖关系。
论文介绍
论文题目:Learning Superconductivity from Ordered and Disordered Material Structures(Datasets and Benchmarks Track)
作者:陈品,彭泺璇,矫瑞,莫晴,王桢,黄文炳,刘洋,卢宇彤
通讯作者:卢宇彤
论文概述:超导性是一种在特定材料和条件下出现的特殊现象,但其与材料的化学和结构特征之间的关系仍未得到充分理解。近年来,数据驱动方法在材料科学领域取得了显著成果,这激励研究人员尝试用此类方法探索超导性的本质。然而,目前尚缺乏一个合适的数据库来支撑相关研究。为此,我们推出了一个全新的数据集——SuperCon3D,它首次同时提供了三维晶体结构和实验测得的超导转变温度 (Tc) 数据。基于 SuperCon3D,我们提出了两种用于高 Tc 超导体设计的深度学习方法。第一种方法是 SODNet,这是一种新型的等变图注意力模型,其支持建模无序晶体结构,可用于晶体材料的性质预测与筛选。第二种方法是扩散生成模型 DiffCSP-SC,用于生成新的材料结构,能够实现以高 Tc 为目标的设计。大量实验结果表明,我们提出的数据集和模型在新型高 Tc 超导体的设计上展现了良好的应用前景。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox