学院新闻
我院师生论文被国际学术会议ACM MM 2024录用
日期:2024-07-25访问量:7月21日,中国计算机学会(CCF)推荐的A类国际学术会议ACM Multimedia 2024论文接收结果公布。中国人民大学高瓴人工智能学院师生有5篇论文被录用。国际多媒体会议(ACM International Conference on Multimedia,简称ACM MM)由国际计算机协会(ACM)发起,是多媒体处理、分析与计算领域最具影响力的国际顶级会议。ACM MM 2024将于2024年10月28日至11月1日在澳大利亚墨尔本举行。

论文简介
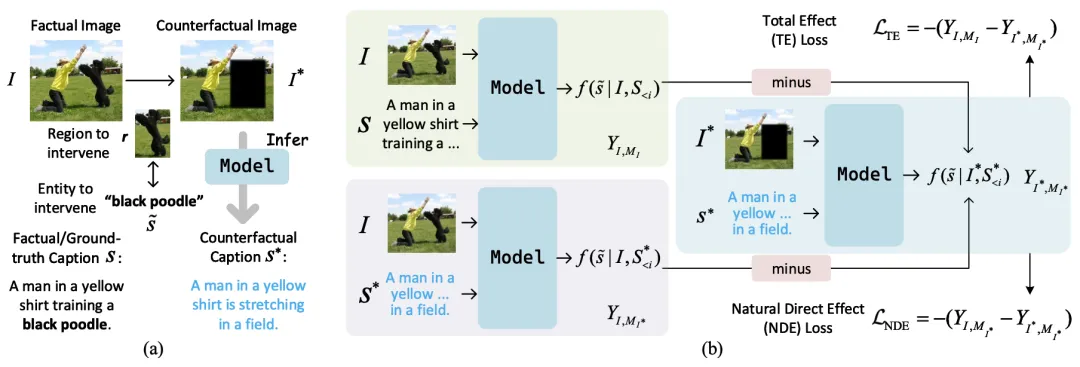
论文题目:See or Guess: Counterfactually Regularized Image Captioning
作者:曹乾,陈旭,宋睿华,王希廷,黄昕庭,任羽辰
通讯作者:陈旭,宋睿华,王希廷
论文概述:图像描述生成,即生成对图像中视觉信息的自然语言描述,是视觉-语言研究中的一项重要任务。之前的模型通常通过统计拟合现有数据集,将机器的生成能力与人类智能对齐来解决这一任务。虽然这些模型在描述正常图像的内容方面表现出色,但它们可能在准确描述某些部分被遮挡或编辑过的图像时表现不佳。相反,人类在这种情况下却能轻松应对。这些模型表现出的弱点,包括幻觉和有限的可解释性,往往在应用于关联模式发生变化的场景时会导致性能下降。在本文中,我们提出了一个通用的图像描述生成框架,通过因果推理使现有模型更具干预任务能力,并能进行反事实解释。具体而言,我们的方法包括利用总效应或自然直接效应的两种变体。我们将这些概念融入训练过程中,使模型能够处理反事实场景,从而变得更具普遍性。在各种数据集上进行的大量实验表明,我们的方法可以有效减少幻觉,并提高模型对图像的忠实度,具有很高的小规模和大规模图像到文本模型的可移植性。
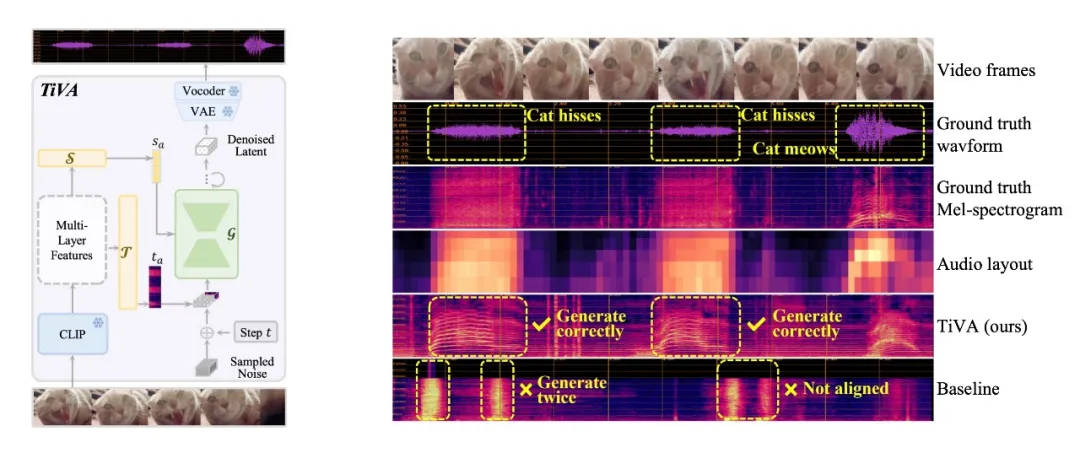
论文题目:TiVA: Time-aligned Video-to-Audio Generation
作者:王希华*,王宇悦*,吴宜函*,宋睿华,谭旭,陈泽华,许洪腾,隋国栋
通讯作者:宋睿华
论文概述:视频到音频生成对于自动视频编辑和后期处理至关重要,其目标是为具有语义相似性和时间同步的无声视频生成高质量音频。然而,大多数现有的方法主要关注视觉和音频模态之间的语义匹配,仅在粗粒度上考虑它们的时间对齐,无法实现精确的时间同步。在这项研究中,我们提出了一种新颖的时间对齐视频到音频生成框架,称为TiVA,用于在生成音频时实现语义匹配和时间同步。我们定义了一种新的音频信息表示形式audio layout,即极低分辨率的梅尔谱,来表示音频的粗粒度语义和时间信息。给定一个无声视频,我们的方法先对其视觉语义进行编码并预测audio layout。然后,利用语义编码和预测的audio layout作为条件信息,学习一个扩散模型生成音频。各项客观和主观实验表明,我们的方法在语义匹配和时间同步精度方面优于现有的SOTA方法。
论文题目:Boosting Audio Visual Question Answering via Key Semantic-Aware Cues
作者:李光耀,杜恒辉,胡迪
通讯作者:胡迪
论文概述:视听问答任务旨在回答与视频中的各种视觉对象、声音及其交互相关的问题。该任务涉及的多模态视频包含了丰富而复杂的动态视听成分,而其中只有一部分成分与给定的问题紧密相关。因此,如何有效的从中感知到与问题相关的视听线索对于正确回答这些问题至关重要。在这篇工作中,我们提出了一个时空感知模型,致力于使模型能够感知复杂视听场景中与问题相关的关键视听线索。具体而言,首先,考虑到图文预训练模型难以将非陈述句的问题和视觉表征对齐到同一语义空间,我们依据问题构建陈述句形式的文本提示,以帮助时序感知模块更准确地找到与问题相关的关键片段。然后,为从关键的时序片段中定位出空间中潜在的发声区域,我们设计的空间感知模块对视觉token进行相似度合并,以突出关键目标的语义,再将其与对应时刻上的音频进行跨模态交互,以增强对视听空间关联,从而定位潜在的发声区域。在多个公共数据集上的大量实验证明了所提出的框架不仅可以很好的理解视听场景,还可以回答复杂的问题。
论文题目:Unveiling and Mitigating Bias in Audio Visual Segmentation
作者:孙沛文,张洪刚,胡迪
通讯作者:胡迪
论文概述:社区研究人员以前开发的音视频分割模型产生的掩膜看起来可能起初合理,但它们偶尔会出现逻辑不正确的异常情况。我们将此归因于现实世界固有的偏好和分布,这比复杂的音视频对应更简单,导致了对重要模态信息的忽视。通常,这些异常现象都很复杂,无法直接系统地观察到。在这项研究中,我们通过适当的合成数据做了开创性的工作,根据异常的来源将其分类和分析为两种类型:'音频主导偏差'和'视觉先验'。对于音频主导偏差,为了增强对不同强度和语义的音频敏感性,我门专门设计了用于音频感知的模块会感知潜在的语义信息。此外,transformer解码器中与这些主动查询相关的交互机制也进行了定制,以适应对音频语义的交互调整的需求。对于视觉先验,探索了多种对比训练策略,通过引入偏置分支来优化模型,而无需改变模型结构。在实验过程中,观察结果证明了现有模型中存在偏差以及其产生的影响。最后,通过对AVS基准的实验评估,我们证明了我们的方法在处理这两种类型偏差方面的有效性,在所有三个子集上都取得了出色的性能。
论文题目:An Inverse Partial Optimal Transport Framework for Music-guided Trailer generation
作者:王瑜彤*,朱斯丹*,许洪腾,罗迪新
通讯作者:罗迪新
论文概述:电影预告片自动生成是视频理解与生成领域的一个颇具挑战性的问题,它旨在从电影等长视频中挑选出精彩镜头,并以吸引人的方式重新组织。在本研究中,我们提出了一种基于逆部分最优传输(Inverse Partial Optimal Transport,简称IPOT)框架的音乐引导的电影预告片生成方法。具体而言,我们将预告片生成任务定义为根据音频片段来选择和排序关键电影镜头,这涉及到匹配视觉和声音模态的潜在表征。在提出的IPOT框架下,我们学习了一个多模态潜在表征模型以实现这一目标。该框架包含一个双塔编码器,分别提取电影和音乐片段的潜在表征,以及一个注意力辅助的Sinkhorn匹配网络,用于参数化镜头潜在表示之间的距离和电影镜头分布。将电影镜头与其预告片音乐镜头间的对应关系视为在这些距离上定义的观测最优传输方案,我们基于双层优化策略,通过求解逆部分最优传输问题来训练模型。我们收集了大量现实世界的电影及其预告片,构建了一个包含丰富标签信息的数据集,称为CMTD,并据此训练和评估了多种预告片生成模型。与最先进的方法相比,我们的IPOT方法在主观视觉效果和客观定量测量方面均展现出显著优势。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox