学院新闻
我院师生论文获SIGIR 2024最佳论文奖、最佳论文提名奖
日期:2024-07-25访问量:7月17日,信息检索领域国际学术会议SIGIR 2024正式公布了论文获奖名单,中国人民大学高瓴人工智能学院师生参与的4篇论文获奖。徐君教授团队论文“A Taxation Perspective for Fair Re-ranking”获得了长文最佳论文提名奖(Best Paper Honorable Mention Award), 毛佳昕副教授参与的长文“Scaling Laws for Dense Retrieval”被评为最佳论文奖(Best Paper Award)。徐君教授作为通讯作者的短文“ReCODE: Modeling Repeat Consumption with Neural ODE”,毛佳昕副教授作为通讯作者的演示论文“CoSearchAgent: A Lightweight Collaborative Search Agent with Large Language Models”获得了最佳短文提名(Best Short Paper Nominees)。


此前,中国人民大学高瓴人工智能学院师生有15篇论文被SIGIR 2024录用(10篇长文、1篇数据集、2篇短文、2篇demo)。SIGIR是中国计算机学会(CCF)推荐的A类国际学术会议,在信息检索及相关领域享有很高的学术声誉,会议于2024年7月14-18日在美国华盛顿特区召开。
徐君教授团队博士生徐晨和新加坡国立大学NExT++实验室、中国科学院计算所合作的论文“A Taxation Perspective for Fair Re-ranking”从经济学中税收的角度重新审视了公平重排序的问题。从税收角度看待公平重排序问题为重新审视公平重排序提供了新的视角,让论文作者能重新审视之前的算法以及提出新的类型的算法。
从税收的角度来看,论文作者在理论上证明了大多数先前的公平重排序方法可以重新表述为单个物品级税收政策。理想情况下,良好的税收政策应该是有效的,并且方便控制以调整排名资源。然而,无论是实证分析还是理论分析都表明,先前的单个物品级税收政策都无法满足两个理想的可控要求:(1)连续性,确保税率的微小变化导致准确性和公平性的小幅变化;(2)对准确性损失的可控性,确保在特定税率下对准确性损失的精确估计。
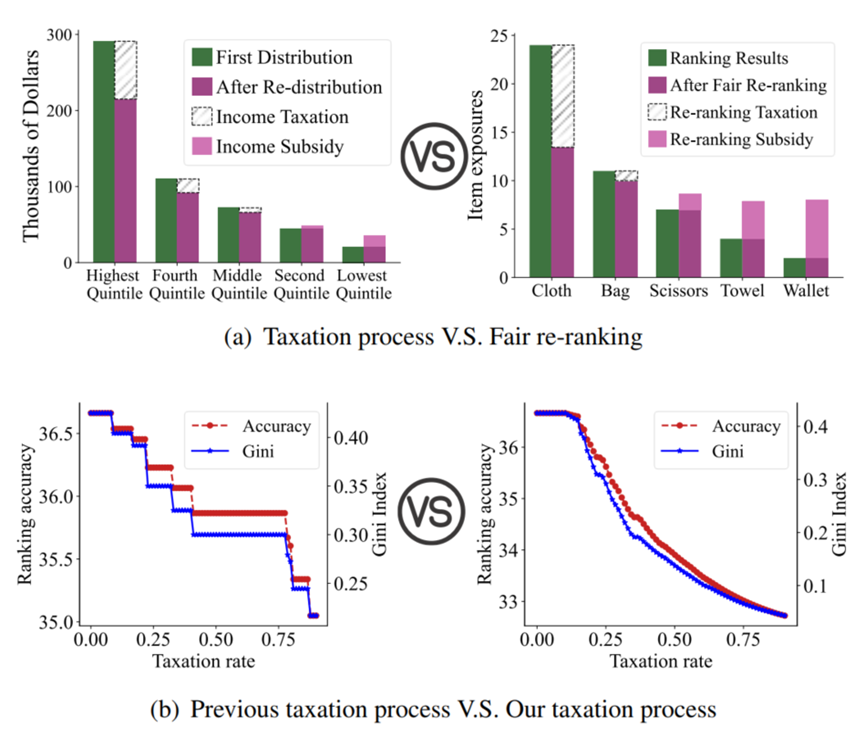
同时,为了克服这些挑战,论文作者引入了一种名为“Tax-rank”的新的公平重新排名方法。Tax-rank引入了一个独特的优化目标,根据两个物品之间效用差异来征税。然后,作者通过在最优传输中利用Sinkhorn算法来高效地优化这样的目标。在全面分析之后,Tax-rank为公平重新排名提供了一个改进的税收政策,从理论上证明了在准确性损失方面的连续性和可控性。在实验中,论文作者将Tax-rank应用于两个公开可用的数据集,分别针对推荐和广告任务。实验结果显示,Tax-rank在效果和效率方面均优于所有基线方法。
徐君教授团队博士生戴孙浩发表的的论文“ReCODE: Modeling Repeat Consumption with Neural ODE”旨在更好的建模推荐系统中的重复消费现象。在工业界的实际推荐系统场景中,比如音乐推荐、重复消费现象极为普遍,用户往往会反复多次听同一小批他们偏爱的歌曲或歌手。要有效地建模这种重复消费行为,关键在于精准捕捉用户对特定物品重复消费间的时间规律。现有研究常常依赖于启发式假设,例如,假设消费间隔遵循指数分布。但鉴于现实世界中推荐场景的复杂性,这类预设的分布往往难以准确描绘出用户重复消费行为的复杂动态变化,从而导致推荐效果不理想。
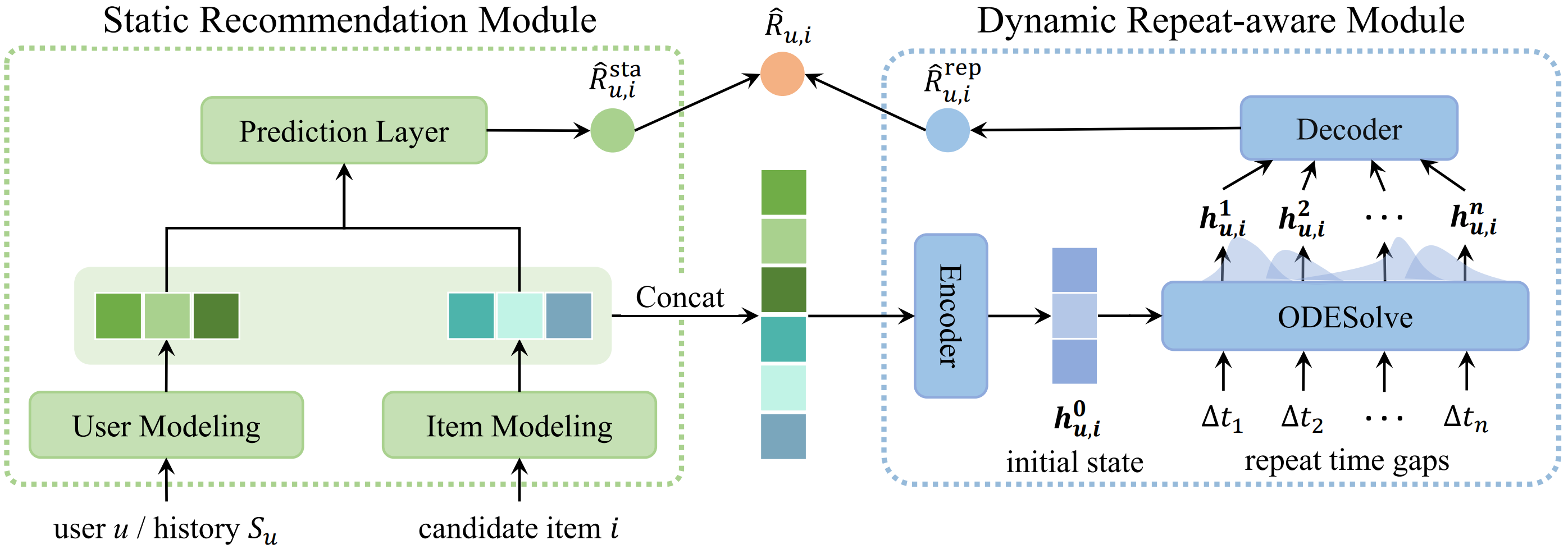
受到神经常微分方程(Neural ODE)在捕捉复杂系统动态特征方面的启发,本文设计了ReCODE——一种新的模型无关框架,它通过Neural ODE来建模重复消费行为。ReCODE主要由两部分构成:一是用户静态偏好的预测模块,二是用户动态重复意图的建模模块。通过同时考虑用户的即时选择和重复消费模式,ReCODE为目标上下文中的用户偏好提供了全面的建模。此外,ReCODE可以作为插件适配到多种现有的推荐模型中,包括基于协同过滤的和基于序列的推荐模型,使其易于在不同场景下应用。在两个真实世界数据集上的实验结果验证了ReCODE能够显著提升原始模型的推荐效果。
毛佳昕副教授与清华大学艾清遥助理教授、刘奕群教授、研究生方言、詹靖涛、陈佳、苏炜航合作发表的长文“Scaling Laws for Dense Retrieval”旨在研究稠密检索模型的检索性能受到模型大小、数据规模、训练计算量三个关键因素影响的“规模缩放定律”(Scaling Laws)。通过使用“对比熵”(contrastive entropy)这一连续的指标对多个稠密检索模型的检索性能进行评价,论文发现稠密检索模型的性能遵循与模型大小和标注数据规模相关的幂律函数关系。
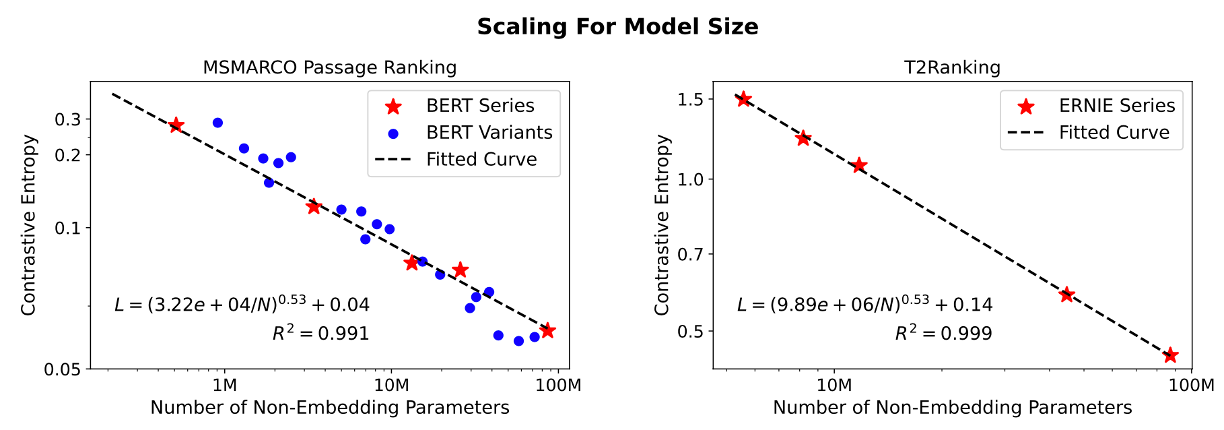
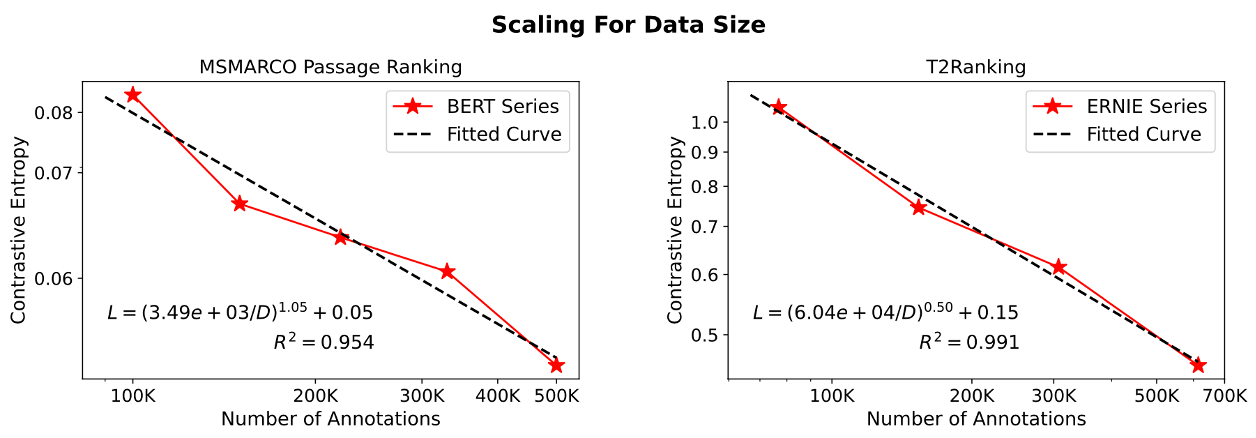
这一发现使得论文作者能有效的预测在扩大模型参数量和标注数据规模后,模型性能的变化。基于该规律,论文进一步讨论了在预算固定情况下的最优的资源分配方式,展示了模型检索性能与训练代价之间存在的权衡,进而对是否应该不断的增大稠密检索的规模进行了深入反思,为稠密检索相关研究与应用提供了有益的指导。
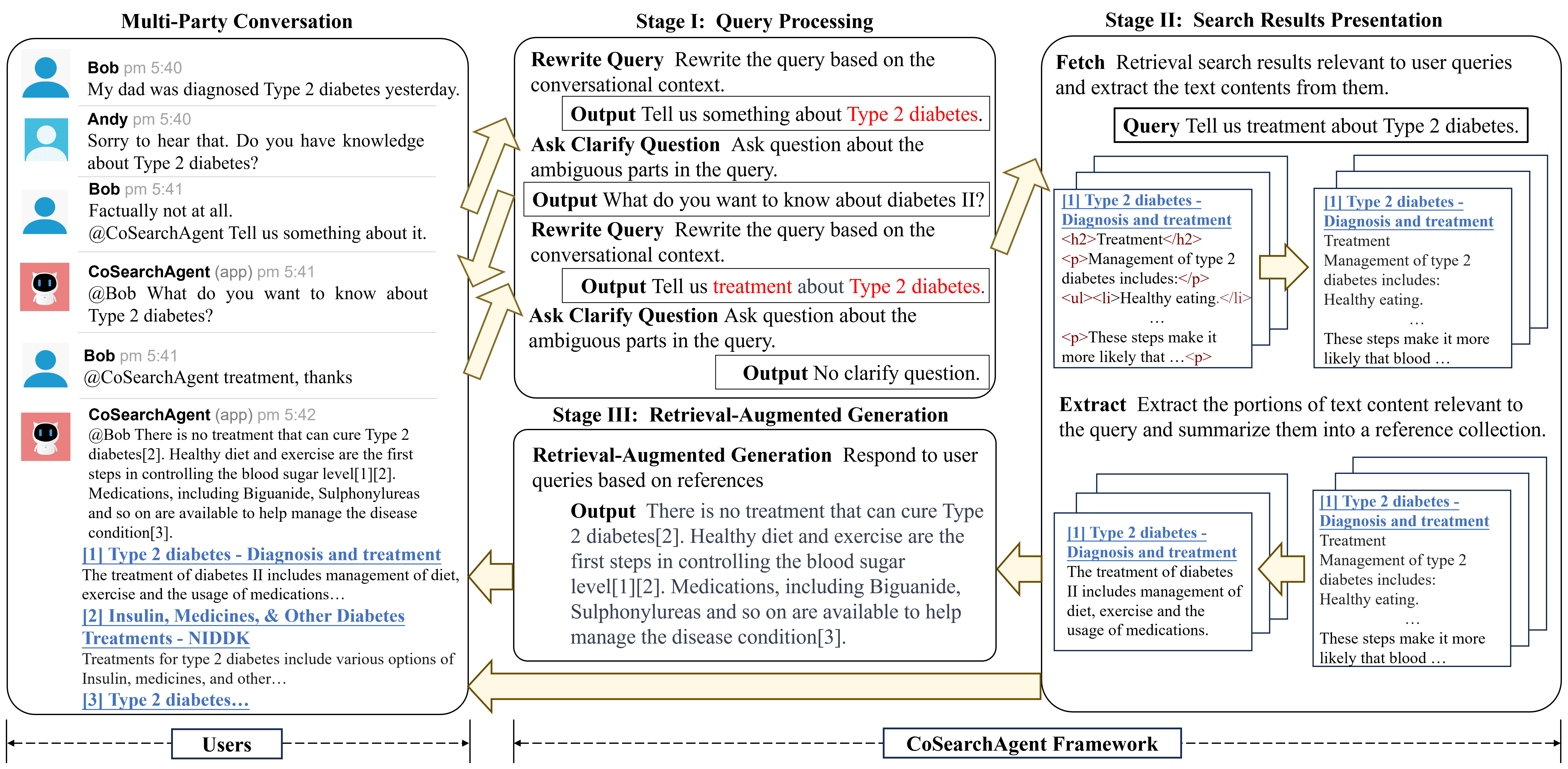
毛佳昕副教授团队博士生公培元发表的论文“CoSearchAgent: A Lightweight Collaborative Search Agent with Large Language Models”构建了基于大语言模型的轻量级协同搜索智能体。协同搜索可以支持多个用户共同完成复杂的搜索任务,近年来研究表明,在消息平台中设计轻量级协同搜索插件可以很好匹配用户的协作习惯,用户不需要离开对话界面即可获得搜索结果,不同用户可以更好了解彼此的搜索和学习进度。然而,由于多用户交互场景的复杂性,开发一个功能完备的轻量级协同搜索插件具有很大挑战,通常依赖于Wizard of Oz方法,即由真人完成系统需要实现的功能。

论文作者发现,大语言模型具备理解用户意图和与用户自然交互的能力,但其在协同搜索任务中的表现尚未可知。由此,本文构建了基于大语言模型的协同搜索智能体CoSearchAgent, 可以支持多个用户协作完成搜索任务。CoSearchAgent具备理解多人对话场景中对话上下文和用户查询的能力,并且可以通过API在互联网上搜索并整合和用户查询相关的信息,基于和查询相关的搜索结果生成答案返回给用户。此外,当查询中信息需求不明确时,CoSearchAgent可以提出澄清问题主动和用户交互,从而进一步明确用户需求。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox