学院新闻
我院师生论文被国际学术会议KDD 2024录用
日期:2024-06-24访问量:近日,中国计算机学会(CCF)推荐的A类国际学术会议KDD 2024论文接收结果公布。中国人民大学高瓴人工智能学院师生有12篇论文被录用。国际知识发现与数据挖掘大会 (ACM SIGKDD Conference on Knowledge Discovery and Data Mining,简称KDD) 是数据挖掘领域的顶级会议,也是中国人民大学A+类学术会议。
部分录用论文简介
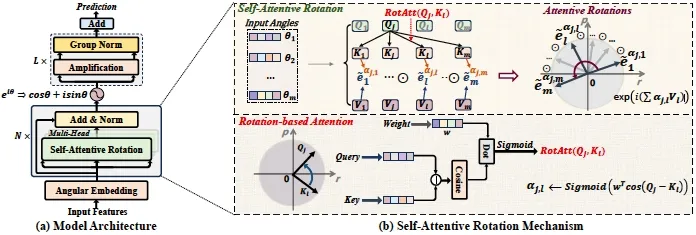
论文题目:Rotative Factorization Machines (Research Track)
作者:田震,石雨鸿,武翔坤,赵鑫,文继荣
通讯作者:赵鑫
论文概述:特征交互模型致力于捕捉不同特征之间的复杂关系,在不同机器学习任务中得到广泛应用。然而,现有特征交叉方法存在两个限制。首先,由于交互项数值的指数增长,它们只能建模有限阶的特征交互,无法scaling到大指数阶。其次,每个特征的交互阶数通常是独立学习的,无法感知不同上下文的特征依赖关系。为了解决这些问题,我们提出了旋转因子分解机模型RFM,其核心思想是将每个特征表示为复平面中的极角。基于此,特征交互可以表达为一系列复向量旋转,其中阶数被转换为旋转系数,从而允许学习任意大的阶数。此外,我们提出了一种新的自注意力旋转方程,通过基于旋转的注意力机制对旋转系数进行建模,使模型自适应地学习不同交互上下文下的交互阶数。此外,RFM还结合了模长放大网络来学习复数特征的模长,进一步提高了模型表达能力。我们在理论上证明了旋转分解机的线性梯度优势,可以有效地规避梯度指数爆炸现象,同时可以退化到传统基于内积的高阶因子分解机,并在5个开源的学术数据集中验证了我们的效果。
论文题目:Revisiting Reciprocal Recommender Systems: Metrics, Formulation, and Method (Research Track)
作者:杨晨,戴孙浩,侯宇蓬,赵鑫,徐君,宋洋,祝恒书
通讯作者:赵鑫
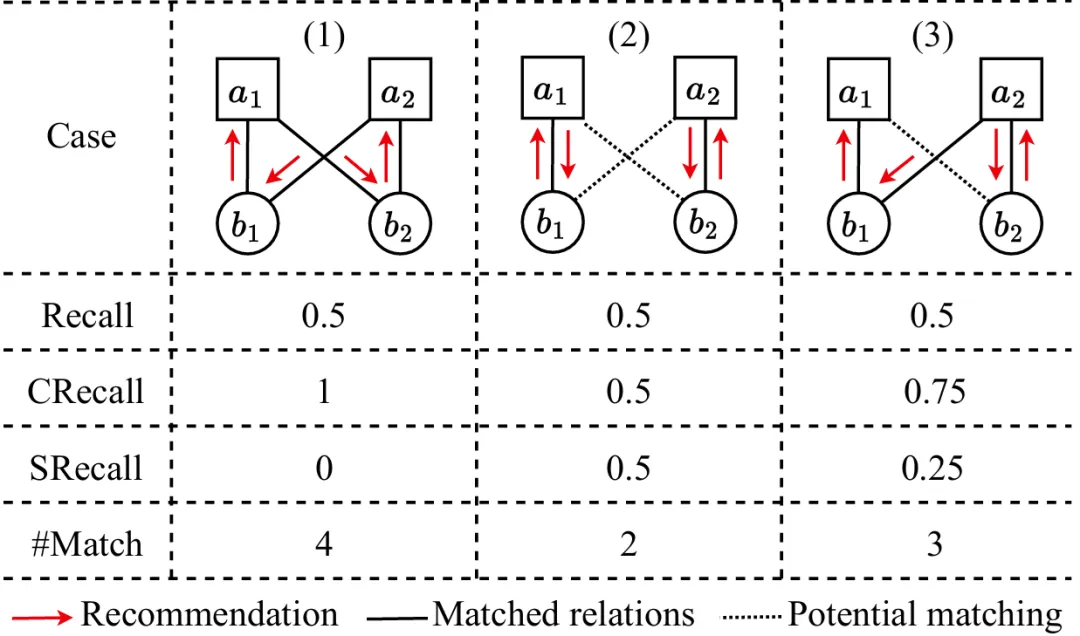
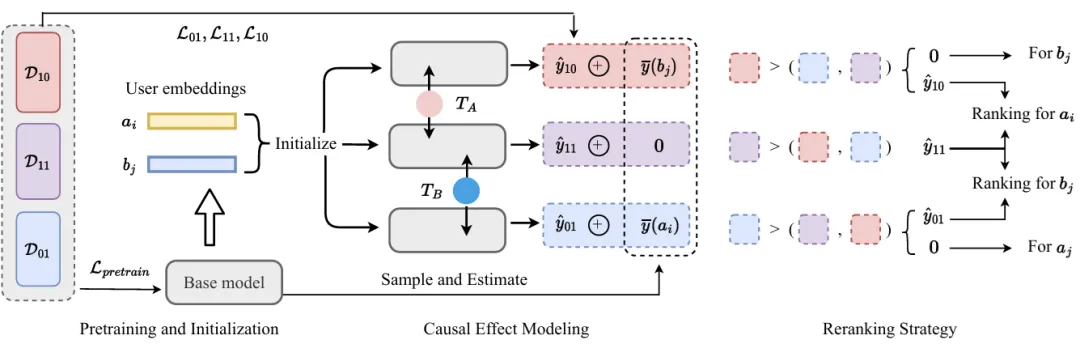
论文概述:互惠推荐系统(Reciprocal Recommender Systems)正在引起越来越多的关注,该系统通过在两个用户群体之间进行双向推荐,提高匹配效率。在现有文献中,大多数方法仍然采用传统的排序指标来分别评估推荐过程中对每一方推荐的性能。这种方法忽略了一个事实,即双方的推荐排序结果共同影响整个系统的有效性,因此需要对系统效果进行更全面的评估,并寻求更好的推荐算法。
本文系统地重新审视了互惠推荐任务,引入了新的评测指标和基于因果推断的推荐算法。首先,我们提出了五个新的评测指标,从三个不同的角度评估互惠推荐系统的性能:总体覆盖率、双向稳定性和均衡排序。进而,我们从因果关系的角度对互惠推荐系统进行了重新构建,将推荐过程形式化为双向干预,通过利用潜在结果框架,我们开发了一个模型无关的因果互惠推荐方法,以更好的建模互惠推荐中的因果效应。此外,我们引入了一种重排策略,以最大化匹配覆盖结果。我们通过在招聘和约会场景中使用两个真实数据集进行了广泛的实验,验证了我们提出的度量标准和方法的有效性。
论文题目:Counteracting Duration Bias in Video Recommendation via Counterfactual Watch Time (Research Track)
作者:赵海源*,蔡国豪*,朱杰明,董振华,徐君,文继荣
通讯作者:徐君
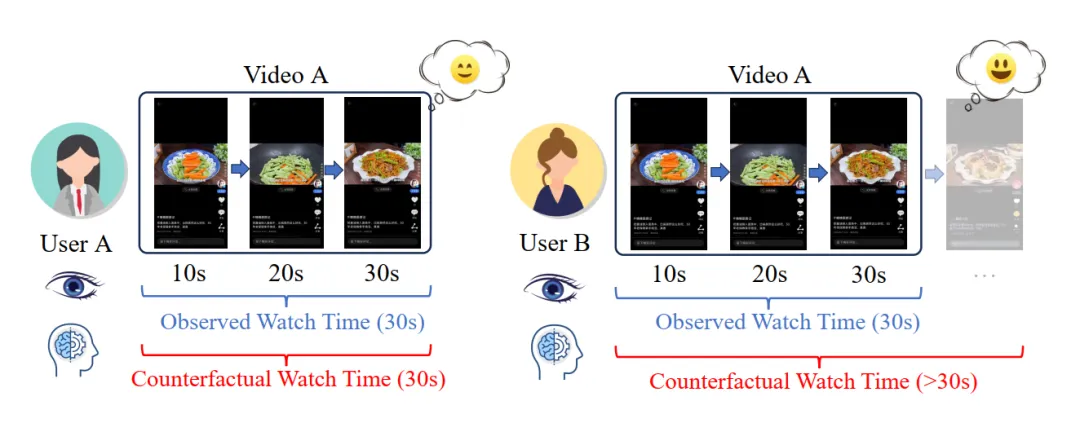
论文概述:在视频推荐中,人们一直在努力利用用户记录的观看时间来满足用户的个性化信息需求。然而,观看时间预测存在时长偏差,阻碍了其准确反映用户兴趣的能力。现有的标签校正方法试图通过根据视频时长对观察到的观看时间进行分组和归一化来纠正偏差并发现用户兴趣。虽然这些方法在一定程度上有效,但我们发现这些方法将完全播放的记录(即用户观看了整个视频)视为同样高的兴趣,这与我们在真实数据集上观察到的情况存在偏差:用户在完全播放视频时有着不同的显式反馈比例。在本文中,我们引入了 '反事实观看时间'(CWT),即如果视频时长足够长,用户在视频上花费的潜在观看时间。分析表明,时长偏差是由视频时长限制导致的 CWT 截断引起的,因此通常发生在那些完全播放的记录上。此外,我们还提出了一种反事实观看模型(CWM),揭示了 CWT 等于用户从视频推荐系统中获得最大收益的时间。此外,我们还定义了一个基于成本的转换函数,用于将 CWT 转换为用户兴趣估计值,并通过优化定义在观察到的用户观看时间上的反事实似然函数来学习该模型。在三个真实视频推荐数据集上进行的广泛实验和在线 A/B 测试表明,CWM 有效地提高了视频推荐的准确性并消除了时长偏差。
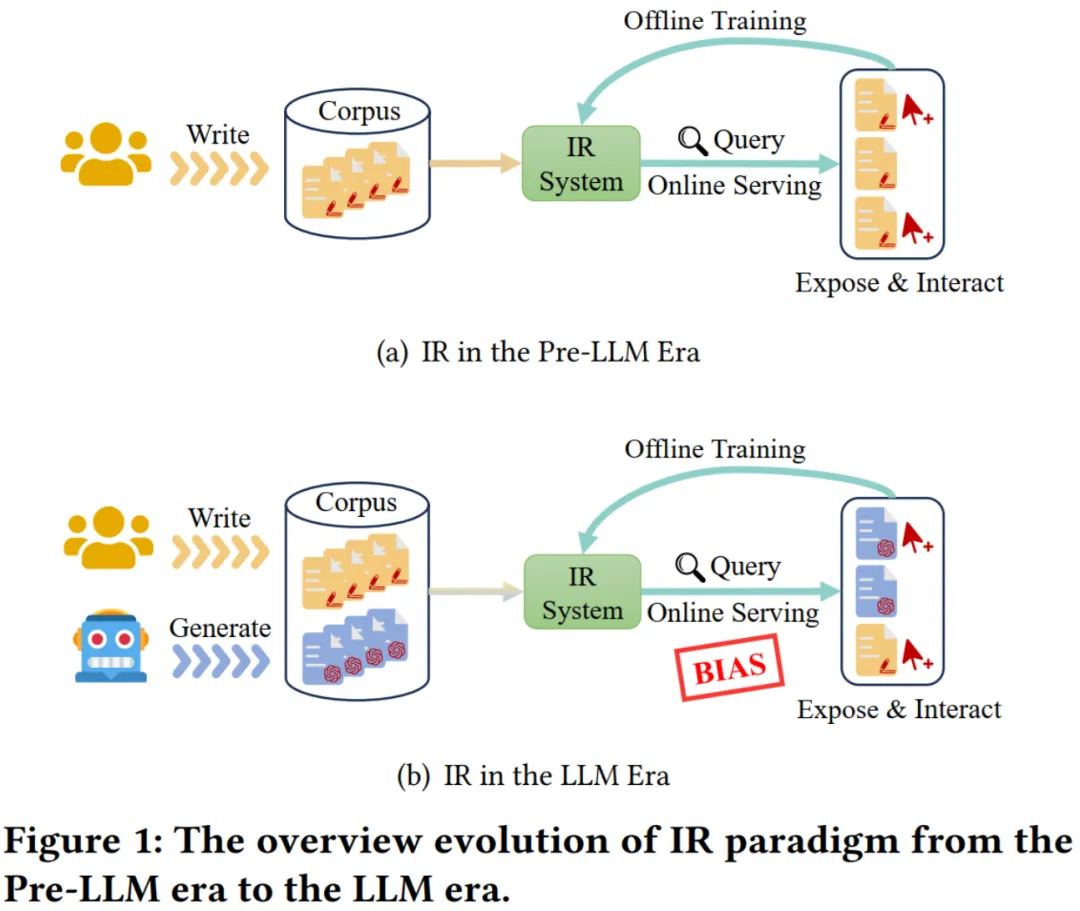
论文题目:Neural Retrievers are Biased Towards LLM-Generated Content (Research Track)
作者:戴孙浩,周雨琦,庞亮,刘炜豪,胡啸林,刘勇,张骁,王刚,徐君
通讯作者:徐君
论文概述:大语言模型(LLM)已经可以生成大量的接近真人撰写的文档,彻底改变了信息检索(IR)应用的范式。具体而言,在LLM时代,IR系统面临着新的挑战:索引的文档现在不再仅仅是由人类撰写的,还包括由LLM自动生成的。这些由LLM生成的文档将如何影响IR系统是一个迫切且尚未探索的问题。在这项工作中,我们针对同时包含人类撰写和LLM生成文本的检索场景对多个代表性的检索模型进行了定量评估。令人惊讶的是,我们的发现表明,神经检索模型倾向于将LLM生成的文档排在更靠前的位置。我们将这种神经检索模型对LLM生成内容的偏好称为“源偏见”。此外,我们发现这种偏见不仅存在于第一阶段做召回的神经检索模型中,也延伸到后续第二阶段做排序的神经重排模型中。进一步的,我们从文本压缩的角度的深入分析了源偏见的来源,发现LLM生成的文本展示了更加集中的语义和更少的噪声,使得神经检索模型更容易进行语义匹配。为了减轻源偏见,我们还提出了一个即插即用的去偏置约束添加到神经检索模型的优化目标上,并且实验结果显示了其有效性。最后,我们讨论了源偏见可能产生的潜在影响,并希望本研究工作的发现能够引起IR社区及其他领域的关注,共同解决源偏见,促进信息内容生态可持续发展。
论文链接:https://arxiv.org/abs/2310.20501
代码链接:https://github.com/KID-22/Source-Bias
论文题目:PolyFormer: Scalable Node-wise Filters via Polynomial Graph Transformer (Research Track)
作者:马嘉鸿,何明国,魏哲巍
通讯作者:魏哲巍
论文概述:近年来,多项式滤波器在图表示学习中表现出色。然而,许多方法为图中所有节点学习相同的滤波器系数,即对这些节点使用相同的滤波器进行信号滤波,这限制了滤波器在节点级任务上的灵活性和表达能力。最近,有研究尝试基于位置编码来学习节点自适应滤波器以克服这一限制。但位置编码的初始化和更新过程开销高昂,阻碍了该方法扩展到大规模图数据。为此,我们提出了一种基于多项式的注意力机制PolyAttn。该注意力机制能有效地学习节点自适应滤波器,增强了滤波器的表达能力。更进一步,我们基于该注意力机制提出了Graph Transformer模型PolyFormer。该模型具有良好的可扩展性,能够处理包含多达 1 亿个节点的图。此外,该模型在谱域上对图信号进行滤波,在保持效率的同时增强了表达能力,在同配图和异配图上都取得了优异的表现。
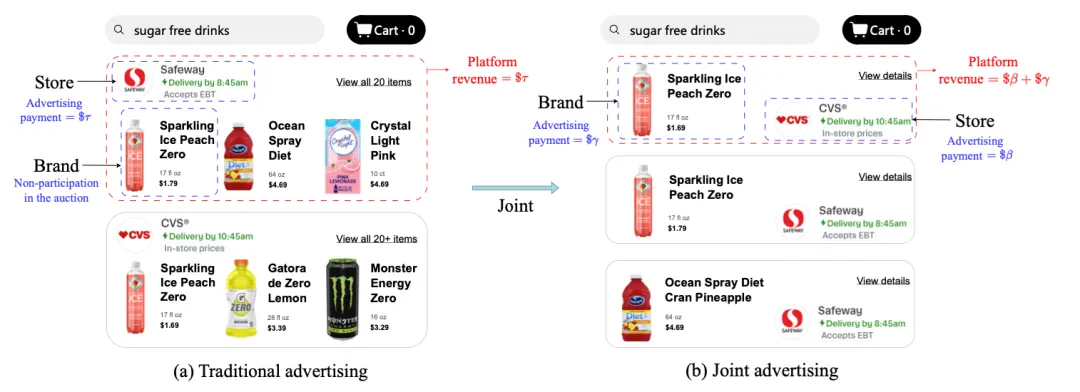
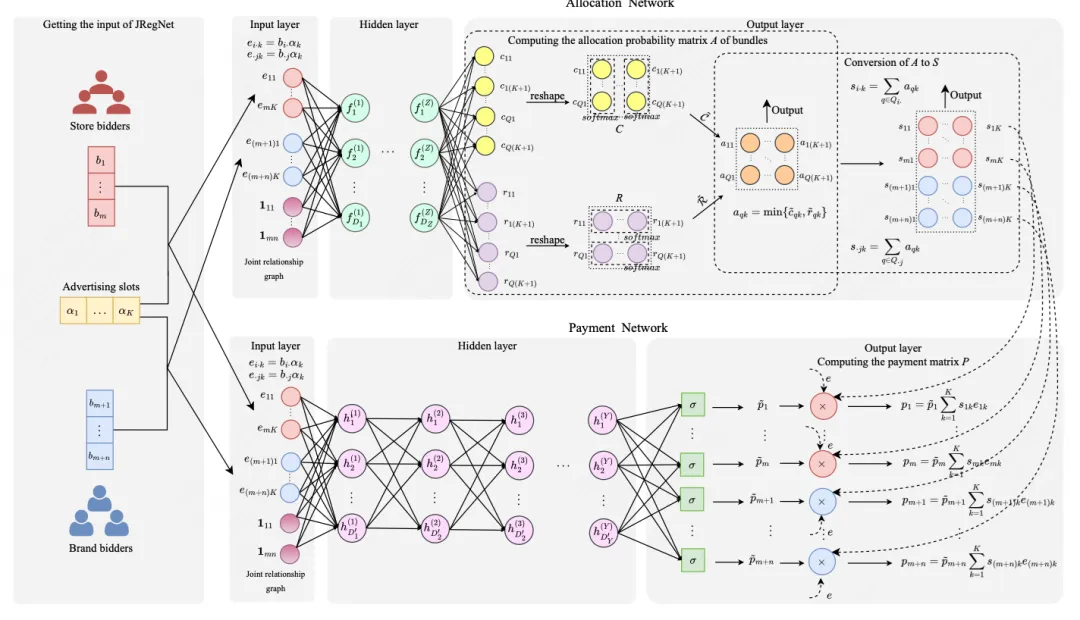
论文题目:Joint Auction in the Online Advertising Market (Research Track)
作者:张振 李维安 雷亚辉 王炳哲 张志成 祁琦 刘强 王星星
通讯作者:祁琦
论文概述:在线广告一直都是互联网平台的主要收入来源。传统的电商平台都是对品牌方或者零售商单独提供营销服务。我们构建了一种全新的“联合拍卖”模式,由品牌方和零售商共同出价来获取流量。我们发现这一全新的模式可以大幅提升平台的流量变现效率。在该场景中,为了最大化平台收入,我们基于深度神经网络设计了JRegNet算法,实现了端到端的自动广告拍卖机制。该机制在最大化平台收益的同时也保证了近似激励兼容性和个体理性。大量线下实验与实际上线实验都验证了平台收益的大幅提升。目前整体模型已经在美团上线,显著提升了美团广告收益。
论文题目:Reimagining Graph Classification from a Prototype View with Optimal Transport: Algorithm and Theorem (Research Track)
作者:钱辰,唐华镱,Hong Liang,刘勇
通讯作者:刘勇
论文概述:近期,图神经网络(Graph Neural Networks, GNNs)在图分类任务中取得了令人鼓舞的性能。然而,GNNs中的消息传递机制隐式地利用了图的拓扑信息,这可能导致结构信息的潜在损失。此外,基于GNNs的图分类决策过程类似于一个黑箱,缺乏足够的透明度。紧随GNNs之后的非线性分类器也默认假设每个类别由单一向量表示,从而限制了类内表示的多样性。为了解决这些问题,我们提出了一种新颖的基于原型的图分类框架,该框架引入了最优传输(Optimal Transport, OT)中的FGW距离作为相似性度量。通过这种方式,模型通过OT显式地利用图上的结构信息,同时享有更透明分类决策过程。原型的引入也天然地解决了类内表示有限的问题。此外,为了缓解FGW距离计算普遍存在的计算复杂性问题,我们设计了一个简单而有效的基于神经网络的FGW距离近似器,它可以享有完全的GPU加速而仅带来边际的性能损失。理论上,我们分析了所提方法的泛化性能,推导出了O(1/N)泛化误差上界。实验结果表明,所提出的框架在几个广泛使用的图分类基准数据集上达到了竞争性和优越的性能。
Github链接:https://github.com/ChnQ/PGOT
论文题目:Enhancing Multi-field B2B Cloud Solution Matching via Contrastive Pre-training (Applied Data Science Track)
作者:陈浩楠, 窦志成, 郝雪桐, 陶云浩, 宋世仁, 盛镇醴
通讯作者:窦志成
论文概述:云解决方案因其提供的服务和工具组合来解决特定问题而在技术行业中获得了显著的普及。然而,尽管云解决方案被广泛使用,为解决方案提供商的销售团队识别适当的公司客户仍然是一个复杂的商业问题,现有的匹配系统尚未能充分解决这一问题。在这项工作中,我们研究了B2B解决方案匹配问题,并确定了这一场景的两个主要挑战:(1)复杂的多字段特征的建模;(2)有限、不完整和稀疏的交易数据。为了应对这些挑战,我们提出了一个框架CAMA,其主体结构为层次化的多字段匹配,并辅以三种数据增强策略和对比预训练目标,以弥补现有数据的缺陷。通过对真实数据集的广泛实验,我们证明了CAMA显著优于多个强基线匹配模型。此外,我们将匹配框架部署在华为云的系统上。我们的观察表明,与之前的在线模型相比,支付转化率(CVR)提高了约30%,这显示了其巨大的商业价值。
论文链接:https://arxiv.org/abs/2402.07076
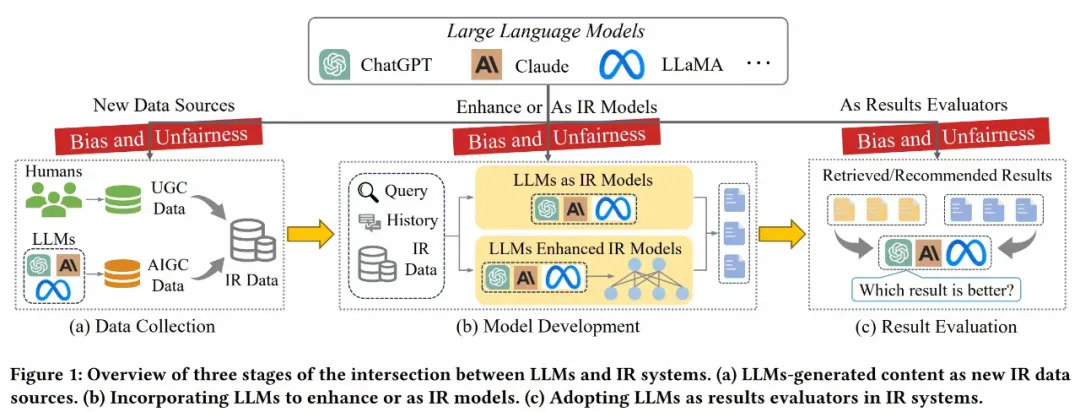
论文题目:Bias and Unfairness in Information Retrieval Systems: New Challenges in the LLM Era(Tutorial, Survey)
作者:戴孙浩,徐晨,徐士成,庞亮,董振华,徐君
通讯作者:庞亮
论文概述:随着大型语言模型(LLMs)的快速发展,包括搜索引擎和推荐系统在内的信息检索(IR)系统因LLMs的引入正经历着一场范式转变。然而,将LLMs融入信息检索过程也引入了新的挑战,特别是可能破坏信息生态的偏见和不公平问题。本教程将全面介绍在引入LLMs到IR系统中时出现的偏见和不公平问题。具体而言,本教程首先把偏见和不公平的问题归结为分布不匹配的问题,并进一步把解决策略从分布对齐的视角进行归类。然后,我们将从数据收集、模型开发和结果评估这三个LLMs影响IR系统的关键阶段总结了新涌现的多种偏见和不公平现象,系统地审视和分析这些问题的定义、特性及其在近期研究中的应对策略。最后,我们将指出一些尚未解决的问题和未来的研究方向,希望能提高IR领域及其他相关领域研究人员对这些新涌现的偏见和不公平问题的意识。
Survey Paper:https://arxiv.org/abs/2404.11457
Github链接:https://github.com/KID-22/LLM-IR-Bias-Fairness-Survey
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox