学院新闻
我院师生论文被国际学术会议 ACL 2024 录用
日期:2024-05-20访问量:近日,第62届国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称 ACL)公布ACL 2024的论文录用消息。中国人民大学高瓴人工智能学院共 35 篇论文被 ACL 2024 录用,其中 20 篇论文被 ACL 主会录用,15篇被 “Findings of ACL” 录用。
ACL 年会是计算语言学和自然语言处理领域国际排名第一的顶级学术会议,由国际计算语言学协会组织,每年召开一次,在中国计算机学会(CCF)推荐会议列表中被列为 A 类会议。2024年是第62届会议,将于8月11日至8月16日在泰国曼谷举行。

主会录用论文
论文题目:INTERS: Unlocking the Power of Large Language Models in Search with Instruction Tuning
作者:朱余韬,张配天,张宬浩,陈逸飞,谢缤雨,刘政,文继荣,窦志成
通讯作者:窦志成
论文概述:大型语言模型(LLM)在各种自然语言处理任务中展现出很强的能力。尽管如此,由于许多与信息检索(IR)相关的概念在自然语言中出现较少,将LLM直接应用于IR任务仍然具有挑战性。虽然已有的基于提示的方法可以向LLM提供任务描述,但它们通常无法实现对IR任务的全面理解和执行,从而限制了LLM在IR任务上的适用性。为了解决这一问题,我们探索了利用指令微调提高LLM在IR任务中的性能。我们构建了一个新的指令数据集INTERS,涵盖了20个IR任务,涵盖三个基本的IR任务类别:查询理解、文档理解和查询-文档关系理解。这些数据源自43个不同数据集并基于我们手工编写的模板构建。我们的实验结果显示,INTERS显著提升了各种开源的LLM(如LLaMA、Mistral和Falcon)在搜索相关任务中的表现。此外,我们进一步探究了基础模型选择、指令设计、指令数据量和任务多样性等因素对模型最终性能的影响。数据集和训练得到的模型已开源:
https://github.com/DaoD/INTERS
论文链接:
https://arxiv.org/abs/2401.06532
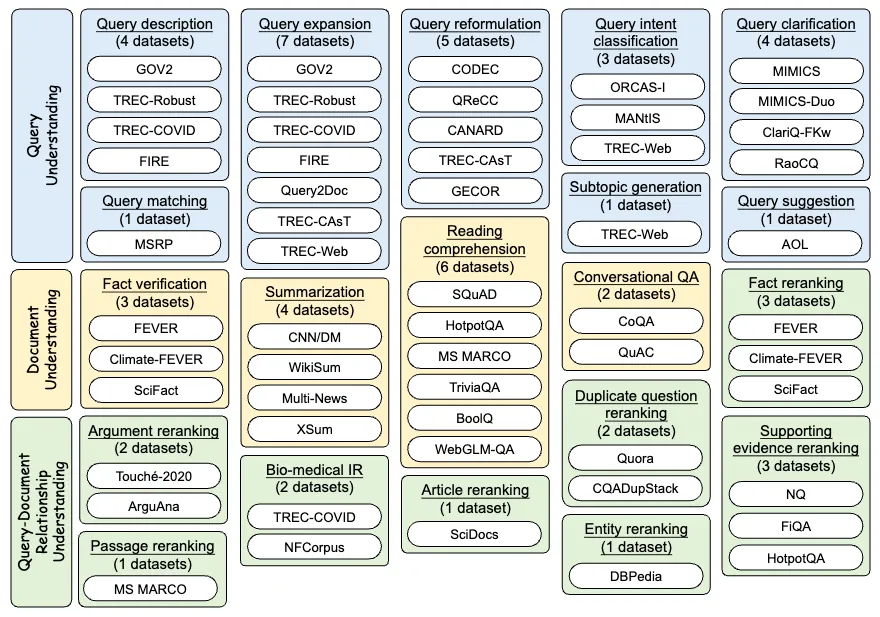
论文题目:Small Models, Big Insights: Leveraging Slim Proxy Models To Decide When and What to Retrieve for LLMs
作者:谭杰骏,窦志成,朱余韬,郭沛东,方琨,文继荣
通讯作者:窦志成
论文概述:大型语言模型(LLMs)与搜索引擎的融合标志着知识获取方法的重大进展。然而,确定一个LLM已具备的知识与需要借助搜索引擎获取的知识仍是一个未解决的问题。现有的大多数方法通过LLM自身给出的初步答案或推理结果来解决这一问题,但这导致了过高的计算成本。本文提出了一种新颖的方法,即SlimPLM,它利用一个轻量级代理模型来检测LLM中缺失的知识,从而加强LLM的知识获取过程。我们采用了一个参数量远少的代理语言模型,将其答案作为启发式答案。这些启发式答案接着被用来预测回答用户问题所需的知识,以及LLM已知和未知的知识。我们仅对LLM不知道的问题中缺失的知识进行检索。我们选取了两个LLM,针对五个数据集的广泛实验结果显示,在问答任务中,LLM的端到端性能有显著提升,以较低的LLM推断成本达到了或超越当前最先进模型的水平。数据集和训练得到的模型已开源:https://github.com/plageon/SlimPlm
论文链接:https://arxiv.org/abs/2402.12052
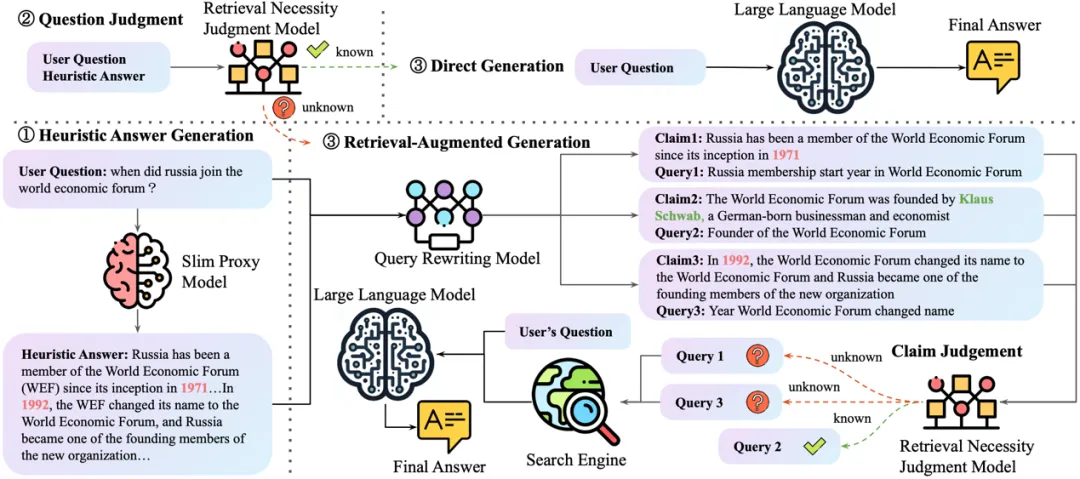
论文题目:Generalizing Conversational Dense Retrieval via LLM-Cognition Data Augmentation
作者:陈浩楠,窦志成,毛科龙,刘炯楠,赵梓良
通讯作者:窦志成
论文概述:对话式搜索利用多轮自然语言上下文来检索相关段落。现有的会话密集检索模型大多将会话视为固定的问题和响应序列,忽视了严重的数据稀疏问题——即用户可以通过多种方式进行会话,而这些交替的会话是未记录的。因此,他们常常很难概括现实场景中的不同对话。在这项工作中,我们提出了一个通过 LLM 认知数据泛化密集检索的框架(ConvAug)。我们首先生成多层次的增强对话来捕捉对话上下文的多样性。受人类认知的启发,我们设计了一种认知感知提示过程,以减少误报、漏报和幻觉的产生。此外,我们开发了一种难度自适应样本过滤器,可以为复杂的对话选择具有挑战性的样本,从而为模型提供更大的学习空间。然后采用对比学习目标来训练更好的会话上下文编码器。在正常和零样本设置下对四个公共数据集进行的广泛实验证明了ConvAug的有效性、普遍性和适用性
论文链接:https://arxiv.org/abs/2402.07092
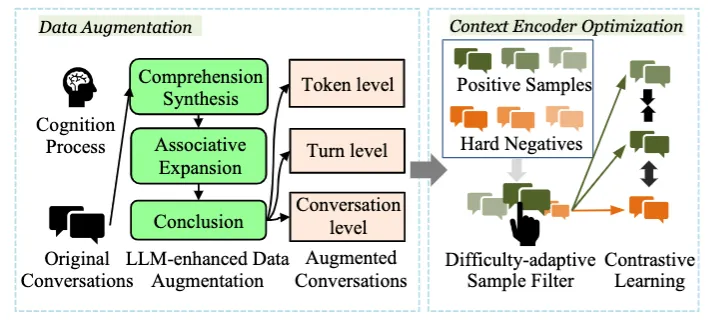
论文题目:Interpreting Conversational Dense Retrieval by Rewriting-Enhanced Inversion of Session Embedding
作者:程依若,毛科龙,窦志成
通讯作者:窦志成
论文概述:在对话式搜索领域,对话式稠密检索已被证实具有卓越的性能。然而,这种检索方式的主要缺点在于缺少可解释性,这影响了我们对模型行为的直观理解,从而阻碍了进一步的针对性改进。本文介绍了CONVINV模型,这是一种简单而高效的解决方法,旨在提高对话式稠密检索模型的可解释性。
CONVINV通过将不透明的对话嵌入转换为明确且可解释的文本,同时尽可能地保持其原本的检索性能。这一转换过程是通过训练一个新提出的Vec2Text模型来实现的,该模型基于特定查询编码器,利用了对话嵌入和查询嵌入在现有的对话式稠密检索系统中共享同一空间的特性。
为了进一步提升模型的可解释性,我们还提出了将外部可解释的查询重写整合到转换过程中。通过在三个对话搜索基准上的广泛评估,我们证明了CONVINV不仅能够生成更加易于理解的文本,而且能够忠实地保持原有的检索性能,超越了现有的基线水平。我们的研究将不透明的对话嵌入与透明的查询重写相结合,为构建可信赖的对话式搜索系统铺平了道路。
论文链接:https://arxiv.org/pdf/2402.12774
论文题目:Grounding Language Model with Chunking-Free In-Context Retrieval
作者:钱泓锦,刘政,毛科龙,周雨佳,窦志成
通讯作者:刘政,窦志成
论文概述:本文提出了一种新颖的无分块上下文(Chunking-Free In-Context, CFIC)检索方法,专为检索增强生成(Retrieval-Augmented Generation, RAG)系统设计。传统的RAG系统在使用精确的证据文本生成响应时,经常面临处理长文档和过滤无关内容的挑战。常用的解决方案,如文档分块和调整语言模型以处理更长的上下文,都存在其局限性。这些方法要么破坏文本的语义连贯性,要么无法有效解决证据检索中的噪音和不准确问题。
CFIC通过绕过传统的分块过程解决了这些挑战。它利用文档的编码隐藏状态进行上下文检索,并通过自回归解码准确识别用户查询所需的特定证据文本,从而消除了分块的需要。CFIC进一步通过引入两种解码策略,即受限句首解码(Constrained Sentence Prefix Decoding)和跳跃解码(Skip Decoding),来增强其性能。这些策略不仅提高了检索过程的效率,还确保了生成的证据文本的真实性。我们在一系列开放问答数据集上的评估表明,CFIC在检索相关和准确的证据方面优于传统方法。通过取消文档分块的需求,CFIC提供了一种更简化、更有效的检索解决方案,使其在RAG系统领域中具有重要价值。
论文题目:Parrot: Enhancing Multi-Turn Instruction Following for Large Language Models
作者:孙宇冲,刘澈,周昆,黄劲文,宋睿华,赵鑫,张富峥,张迪,盖坤
通讯作者:宋睿华,赵鑫
论文概述:人们常常需要通过与大语言模型(LLMs)的多轮交互来获取他们所需的答案或更多信息。然而大部分现有研究对于LLMs在遵循多轮指令方面的能力——包括训练数据集、训练方法和评估标准——都未给予足够的关注。在本文中,我们介绍了Parrot,一个旨在增强LLMs多轮指令遵循能力的方案。首先,我们介绍了一种高效且有效的方法,用于收集具有人类特征的多轮指令,例如使用指代和省略。其次,我们提出了一种基于上下文的偏好优化策略,进一步增强LLMs在多轮互动中处理复杂指令的能力。此外,为了定量评估LLMs在多轮指令遵循中的表现,我们构建了一个从现有基准衍生的多轮评估基准。广泛的实验结果表明,Parrot能够将LLMs在多轮指令遵循方面的性能提高至多7.2%。
论文题目:Persuading across Diverse Domains: a Dataset and Persuasion Large Language Model
作者:金楚浩,任珂凝,孔令真,王希廷,宋睿华,陈欢
通讯作者:王希廷,宋睿华
论文概述:说服性对话系统需要在多轮对话中理解复杂用户意图并规划长期策略,即便对最先进的大语言模型(LLMs)如GPT-4依然充满挑战。在本文中,我们利用GPT-4构建了首个跨领域的说服性对话数据集DailyPersuasion,并提出了名为PersuGPT的通用说服模型,通过意图-策略推理来训练基于LLMs的说服性对话模型,使得PersuGPT可以总结用户意图,并推理出下一步的响应策略和回复。此外,我们设计了一种基于模拟交互的偏好优化方法,通过用户模型和PersuGPT来模拟后续对话,并用GPT-4准确地估算长期奖励,使得PersuGPT生成更具有说服力的回复。在两个数据集上的自动评估指标和人类评估结果显示,PersuGPT优于包括GPT-4在内的所有的基线方法。
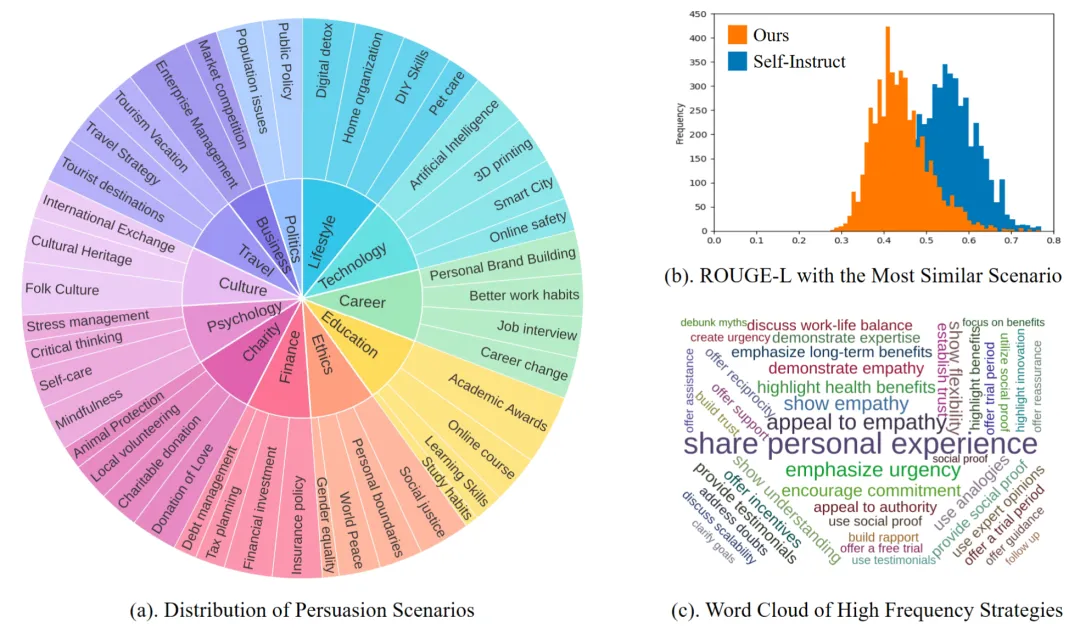
论文题目:Prototypical Reward Network for Data Efficient Model Alignment
作者:张静涵,王希廷,靳轶乔,陈畅与,张鑫浩,刘鲲鹏
通讯作者:王希廷,刘鲲鹏
论文概述:从人类反馈中强化学习(RLHF)时,获取人类反馈的成本往往较高。本文提出了一种基于原型网络的奖励模型,可以利用更少的人类反馈使大语言模型(LLMs)更快与人类意图对齐。我们的方法充分发挥了原型网络在样本稀疏场景下的学习优势,优化了奖励模型的网络结构,从而能够从较少的人类反馈中进行稳定可靠的学习,同时奖励模型可解释性更强。实验表明我们的方法显著提升了数据稀疏场景下奖励模型准确性和LLM与人类意图对齐效果。
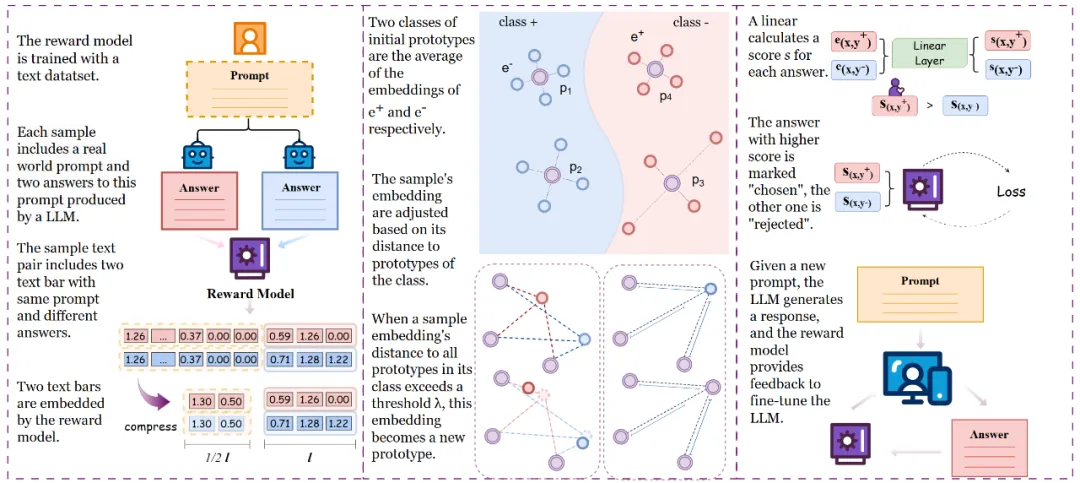
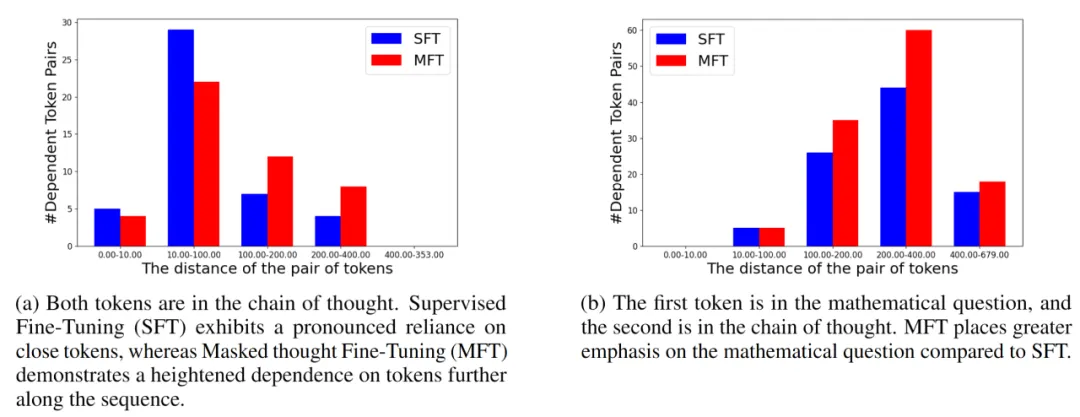
论文题目:Masked Thought: Simply Masking Partial Reasoning Steps Can Improve Mathematical Reasoning Learning of Language Models
作者:陈畅与,王希廷,林廷恩,吕昂,武玉川,高欣,文继荣,严睿,李永彬
通讯作者:王希廷、严睿、李永彬
论文概述:在推理任务中,即使是一个微小的错误也可能引发一连串的不准确结果,导致大语言模型(LLMs)推理性能不佳。现有方法试图利用更精确的监督信号来缓解这一问题,往往需要较多人工标注或者较大的时间开销。我们提出一种十分简单易实现的方法,不需要额外监督信号来引导输出,只需要在输入部分加入扰动噪音,随机遮蔽思考链中的词,即可使Llama-2-7b在现有推理数据集GSM8K上相对标准监督式微调提高5%准确性。此外,当与不同质量和大小的增强数据集同时使用时,仍能进一步显著提高在GSM8K 和MATH数据集上的推理准确性。我们研究了造成这种提升的背后机制,通过案例和定量分析表明我们的方法可能有助于模型构建更长距离的依赖性,特别是对问题中前提的依赖性,缓解思考链中的错误累积。
论文题目:Fortify the Shortest Stave in Attention: Enhancing Context Awareness of Large Language Models for Effective Tool Use
作者:陈雨涵*,吕昂*,林廷恩, 陈畅与,武玉川,黄非,李永彬,严睿
通讯作者:李永彬,严睿
论文概述:我们展示了大型语言模型(LLMs)在需要高度上下文感知的任务中,如利用LLMs进行工具使用时,其注意力机制存在的固有波形模式显著影响了语言模型的表现。具体来说,当上下文中的关键信息处于注意力波形的波谷时,这些信息可能被模型忽略,从而导致性能下降。为了解决这个问题,我们提出了一种名为“Attention Buckets”的新型推理算法。它允许大语言模型通过多个并行实例处理上下文。每个实例利用不同的RoPE进行位置编码,从而创建一个独特注意力波形模式。通过用另一个并行实例中的注意力波峰补偿另一个实例中的注意力波谷,我们的方法增强了LLM对上下文位置的感知,减轻了忽略关键信息的风险。在当前最大最全面的工具使用基准测试中,我们的方法将7B的语言模型提升到了与GPT-4相媲美的SOTA性能。在其他需要强上下文感知的基准测试和一些RAG任务中,Attention Buckets也展现出了显著的性能提升。
论文题目:CharacterEval: A Chinese Benchmark for Role-Playing Conversational Agent Evaluation
作者:涂权, 范世龙, 田子杭, 沈田浩,商烁,高欣,严睿
通讯作者:严睿,高欣
论文概述:大型语言模型(LLMs)的出现彻底改变了生成代理的领域。其中,角色扮演对话代理(RPCAs)因其能够情感上吸引用户而备受关注。然而,缺乏全面的基准测试阻碍了该领域的进展。为弥补这一空缺,我们提出了CharacterEval,一个用于全面评估RPCA的中文基准测试,辅以定制的高质量数据集。该数据集包括1785个多轮角色扮演对话,涵盖23020个示例,并包含从中国小说和剧本中衍生的77个角色。数据集的构建经过精心策划,首先通过GPT-4提取初始对话,然后进行严格的人工质量控制,并从百度百科获取深入的角色资料。CharacterEval采用多方面的评估方法,涵盖五个维度上的十六个目标指标。为方便对这些主观指标进行评估,我们进一步开发了CharacterRM,一种基于人工注释的角色扮演奖励模型,与GPT-4相比,它与人类判断的相关性更高。在CharacterEval上的综合实验表明,中国LLMs在中文角色扮演对话中表现出比GPT-4更为出色的能力。
论文题目:DetermLR: Augmenting LLM-based Logical Reasoning from Indeterminacy to Determinacy
作者:孙宏达,徐伟恺,刘伟,栾剑,王斌,商烁,文继荣,严睿
通讯作者:严睿
论文概述:大型语言模型 (LLM) 的发展彻底改变了推理任务的格局。为了增强LLM模拟人类推理的能力,之前的研究主要集中在使用链、树或图等各种思维结构对推理步骤进行建模。然而,基于LLM的推理仍然遇到以下挑战:(1)预设结构对不同任务的适应性有限;(2)利用已知条件推导新条件的效果不够精确;(3)后续推理步骤对历史推理经验考虑不足。为此,我们提出了一种全新的大模型思维框架DetermLR,将推理过程重新建模为从不确定性到确定性的演变。首先,我们将已知条件分为两种类型:确定前提和不确定前提,这为推理过程提供了总体方向,并指导LLM将不确定信息逐渐向确定方向转化。随后,我们设计两阶段定量指标来对已知条件的优先级进行划分,以利用更相关的条件探索新信息。此外,我们开发推理记忆模块自动存储和提取可用前提和推理路径,为后续推理步骤保留关键历史推理细节。实验表明DetermLR 在5个逻辑推理benchmark(LogiQA、ProofWriter、FOLIO、PrOntoQA 和 LogicalDeduction)上超越所有baseline推理方法。与之前的多步推理方法相比,DetermLR 以更少的推理步骤实现了更高的准确率,凸显了其在解决逻辑推理任务方面的优越效率和有效性。
论文题目:Mobile-Bench: An Evaluation Benchmark for LLM-based Mobile Agents
作者:邓诗涵,徐伟恺,孙宏达,刘伟,谭涛,刘剑锋,李昂,栾剑,王斌,严睿,商烁
通讯作者:商烁,严睿
论文概述:随着大语言模型(LLM)的显着进步,基于LLM的智能体已成为人机交互领域的研究热点。然而,基于 LLM 的移动代理缺乏可用的基准。对这些代理进行基准测试通常面临三个主要挑战:(1)仅 UI 操作的低效率对任务评估造成了限制。(2)单个应用程序中的具体指令不足以评估LLM移动代理的多维推理和决策能力。(3)当前的评估指标不足以准确评估顺序动作的过程。为此,我们提出了 Mobile-Bench,这是一种用于评估基于 LLM 的移动代理功能的新颖基准。首先,我们通过整合收集的103个API来扩展常规的UI操作,以加快任务完成的效率。随后,我们通过将真实用户查询与LLM的增强相结合来收集评估数据。为了更好地评估移动代理的不同级别的规划能力,我们的数据分为三个不同的组:SAST、SAMT 和 MAMT,反映了不同级别的任务复杂性。Mobile-Bench 包含 832 个数据条目,以及 200 多个专门用于评估多 APP 协作场景的任务。此外,我们引入了一种更准确的评估指标,名为 CheckPoint,以评估基于 LLM 的移动代理在其规划和推理步骤中是否达到了关键点。
论文题目:Tell Me More! Towards Implicit User Intention Understanding of Language Model Driven Agents
作者:钱成,何秉翔,庄众,邓佳,秦禹嘉,从鑫,张众,周杰,林衍凯,刘知远,孙茂松
通讯作者:从鑫,林衍凯
论文概述:当前大模型驱动的智能体通常缺乏有效的用户参与机制,而这一点至关重要,因为用户指令往往是模糊的。虽然这些智能体擅长制定策略和执行任务,但它们在主动而精准地理解用户意图方面存在困难。为了解决该问题,我们引入了隐式意图理解(Intention-in-Interaction,简称IN3)测试,这是一个全新的基准,旨在通过明确的询问来探索用户的隐式意图。接着,我们提出在智能体设计中引入专家模型作为上游,以增强用户与智能体的交互。我们基于 IN3 对话数据训练了Mistral-Interact,其能主动评估任务的模糊性,询问用户意图,并将其细化为可执行的目标,以促进下游智能体任务执行。我们将其整合到XAgent框架中,并对增强后的智能体系统在用户指令理解和执行两个方面进行了。结果表明我们的方法在识别模糊用户任务、恢复和总结关键缺失信息、设定精确和必要的智能体执行目标以及最小化冗余工具使用方面表现出色,并从整体上提高了智能体任务执行效率。
论文题目:The Dawn After the Dark: An Empirical Study on Factuality Hallucination in Large Language Models
作者:李军毅,陈杰,任瑞阳,成晓雪,赵鑫,聂建云,文继荣
通讯作者:赵鑫
论文概述:在大语言模型时代,幻觉(即生成与事实不符的内容)对真实世界中LLM 的应用构成了巨大挑战。要解决大模型产生幻觉的问题,应深入研究三个关键问题:如何检测幻觉(检测)、大模型为何产生幻觉(原因)以及如何缓解幻觉(消除)。为了应对这些挑战,本研究对大模型幻觉进行了系统的实证研究,重点关注幻觉的检测、原因和消除这三个方面。特别的,我们构建了一个新的幻觉基准 HaluEval 2.0,并设计了一种简单而有效的大模型幻觉检测方法。此外,我们从大模型的不同训练或使用阶段深入探究导致大模型幻觉的潜在因素。最后,我们探究了一系列广泛用于缓解幻觉的技术。本文对于理解幻觉起源和消除提供了许多重要的实证发现。
论文题目:Unlocking Data-free Low-bit Quantization with Matrix Decomposition for KV Cache Compression
作者:刘沛羽,高泽峰,赵鑫,马翼鹏,汪涛,文继荣
通讯作者:赵鑫
论文概述:这篇论文中我们提出了DecoQuant方法,无需额外的数据校准就可以实现对大语言模型的KV缓存进行低比特的量化处理。核心的思想是,通过矩阵分解技术将异常值从整个矩阵转移到了分解出来的局部张量上,有效缓解了直接量化矩阵导致的误差较大的问题。研究中发现,大部分的异常值都集中在参数量较小的张量上,而对于参数量较大的张量,异常值则不明显。因此,论文提出对这些大张量进行低比特的量化,而对小张量保持较高的比特精度。实验表明,我们提出的方法可以在无需数据校准的情况下,实现4比特的KV缓存量化,同时有效降低量化误差保证生成质量。
论文题目:Exploring Language-Specific Regions in Large Language Models
作者:唐天一*,罗文扬*,黄浩洋,张冬冬,王晓磊,赵鑫,韦福如,文继荣
通讯作者:赵鑫
论文概述:大语言模型展现了出色的多语言处理能力,然而解释大模型处理多语言文本的底层机制仍然是一个具有挑战性的问题。本文深入探讨了大模型中的Transformer架构,旨在定位特定语言的区域。我们提出了一种新颖的检测方法——语言激活概率熵(LAPE),用于识别大模型中的语言特定神经元。研究结果表明,大模型在处理某种语言时的高效性主要归因于少数神经元,这些神经元主要分布在模型的顶层和底层。此外,我们展示了通过选择性地激活或停用语言特定神经元来“引导”大模型输出不同语言的可行性。我们的研究为理解和探索大模型的多语言能力提供了重要证据。
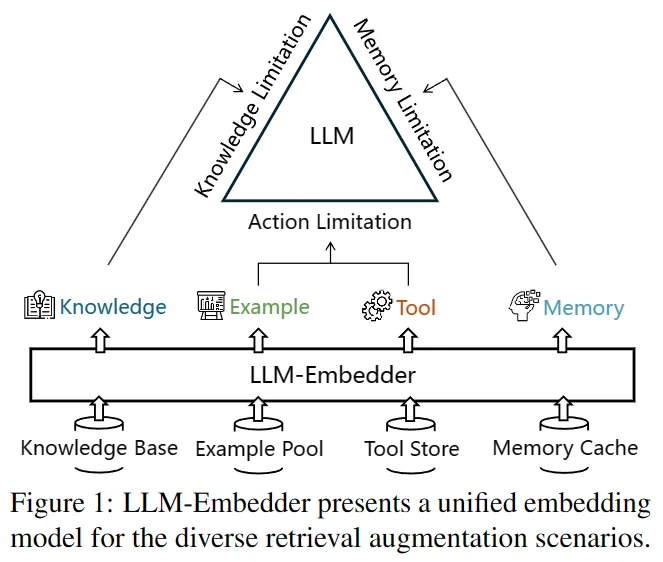
论文题目:A Multi-Task Embedder For Retrieval Augmented LLMs
作者:张配天,肖诗涛,刘政,窦志成,聂建云
论文概述:大语言模型(LLM)自身面临着知识、记忆、和行动上的局限。检索增强(RAG)通过从外部引入有用的信息(有保障的知识片段、历史记忆、示例和工具),能显著缓解这些局限。然而,现有的检索器有两大问题。对于通用检索器而言,其没有在RAG场景下优化过,导致效果比较受限;对于任务专精检索器而言,其只能在目标场景下表现优异,无法胜任于各种RAG场景。本篇工作提出LLM-Embedder,一个能支持LLM各项RAG场景的语义表征模型。我们首先优化了对LLM偏好的建模,同时提出了新颖的学习该偏好的方法,能够鲁棒且有效地利用LLM的反馈;进一步,我们系统地优化了多任务学习的框架,从而防止不同的检索任务之间发生负向影响。在实验中,LLM-Embedder有效地提升了LLM在各种下游RAG任务上的效果,显著超越了一系列通用检索器和任务专精检索器。
模型:https://huggingface.co/BAAI/llm-embedder
代码:https://github.com/FlagOpen/FlagEmbedding
论文题目:MAVEN-ARG: Completing the Puzzle of All-in-One Event Understanding Dataset with Event Argument Annotation
作者:王晓智,彭皓,关勇,曾开胜,陈健晖,侯磊,韩旭,林衍凯,刘知远,谢若冰,周杰,李涓子
论文概述:理解文本中的事件是自然语言理解的核心目标之一,这需要检测事件发生、提取事件要素并分析事件间关系。然而,由于任务复杂性带来的标注挑战,事件理解领域长期以来一直缺乏覆盖事件理解全过程的大规模数据集。本工作中我们构建了 MAVEN-Arg事件要素抽取数据集,它通过标注事件要素增强了 MAVEN 数据集,成为第一个支持事件检测、事件要素抽取和事件关系抽取的统一数据集。作为事件要素抽取基准,MAVEN-Arg 具有三个主要优点:(1) 事件框架全面,涵盖 162 个事件类型和 612 个事件要素,全部带有专家编写的定义和示例;(2) 数据规模大,包含通过人工标注获得的 98,591 个事件和 290,613 个要素;(3) 全面支持事件要素抽取的所有任务变体,MAVEN-Arg在文档级别标注了实体和非实体类型事件要素。实验表明,MAVEN-Arg 对于可微调的开放模型和商业大语言模型来说都相当具有挑战性。此外,为了展示统一事件理解数据集的独特优势,我们初步探索了基于大语言模型的全新潜在应用:未来事件预测。MAVEN-Arg 数据集和相关代码将公开发布以促进后续研究。
论文题目:Prompt Refinement with Image Pivot for Text-to-Image Generation
作者:詹靖涛,艾清遥,刘奕群,潘滢炜,姚霆,毛佳昕,马少平,梅涛
论文概述:在以文生图应用中,将用户提交的自然语言提示词(prompt)自动的改写为包含系统所需关键词的提示词是提升用户体验的关键。我们可以将该问题类比于一个把提示词从“用户语言”翻译到“系统语言”的机器翻译问题。然而,由于缺乏该翻译任务中的“平行语料”,我们难以直接训练一个翻译模型。因此,我们受到零资源机器翻译技术的启发,设计了一个以图片为“枢纽语言“(pivot language)的提示词改写方法PRIP。PRIP使用用户偏好的图片的隐状态表示作为用户语言到系统语言的翻译问题中的”枢纽语言”,将上述资源稀缺的翻译问题分解为两个任务:1)基于用户语言推测用户偏好的图片的表示;2)将图片表示翻译为机器语言。实验表明,该方法能利用这两个任务上丰富的数据资源进行训练,进而取得比现有提示词改写方法更好的性能。
Findings of ACL 录用论文
论文题目:An Element is Worth a Thousand Words: Enhancing Legal Case Retrieval by Incorporating Legal Elements
作者:邓琛龙,窦志成,周雨佳,张配天,毛科龙
通讯作者:窦志成
论文概述:司法类案检索对于促进司法公正和公平具有重要作用。其最大的挑战之一是相关性的定义远远超出了即席检索中常见的语义相关性。在本文中,我们揭示了法律要素通常包含专门法律背景中的关键事实,可以很大程度上提高司法案例检索的相关性匹配。为了方便法律要素的使用,我们在广泛使用的LeCaRD数据集的基础上,通过两阶段半自动方法构建了一个名为LeCaRD-Elem的中国法律要素数据集,最大限度地减少对人力的依赖。同时,我们引入了两种新模型来利用法律元素增强法律搜索。第一个是 Elem4LCR-E,是一个两阶段模型,可以明确地预测文本中的法律元素,然后利用它们来提高排名。认识到更无缝集成的潜在好处,我们进一步提出了一种名为 Elem4LCR-I 的端到端模型,该模型使用量身定制的师生培训框架将法律要素知识内化到其模型参数中。大量的实验强调了法律要素的重要价值,并证明了我们提出的两种模型在增强法律搜索方面相对于现有方法的优越性。
论文题目:BIDER: Bridging Knowledge Inconsistency for Efficient Retrieval-Augmented LLMs via Key Supporting Evidence
作者:金佳杰,朱余韬,周雨佳,窦志成
通讯作者:窦志成
论文概述:检索增强的大语言模型(LLMs)在各类知识密集型任务中显出有效性,解决了LLMs知识更新和事实不足的固有问题。然而,检索知识与LLMs所需知识之间的不一致往往会导致检索增强LLMs生成质量的下降。本文介绍了一种方法BIDER,通过知识合成、监督式微调(SFT)和偏好对齐,将检索文档精炼为关键支持证据(KSE)。BIDER从构造的KSE中学习映射,并通过强化学习学习LLM的信息获取偏好。跨五个数据集的评估显示,BIDER将LLM的答案质量提高了7%,同时将检索文档中的输入内容长度减少了80%,取得了最先进的性能。
论文链接:https://arxiv.org/abs/2402.12174
论文题目:Cocktail: A Comprehensive Information Retrieval Benchmark with LLM-Generated Documents Integration
作者:戴孙浩,刘炜豪,周雨琦,庞亮,阮荣钜,王刚,董振华,徐君,文继荣
通讯作者:徐君
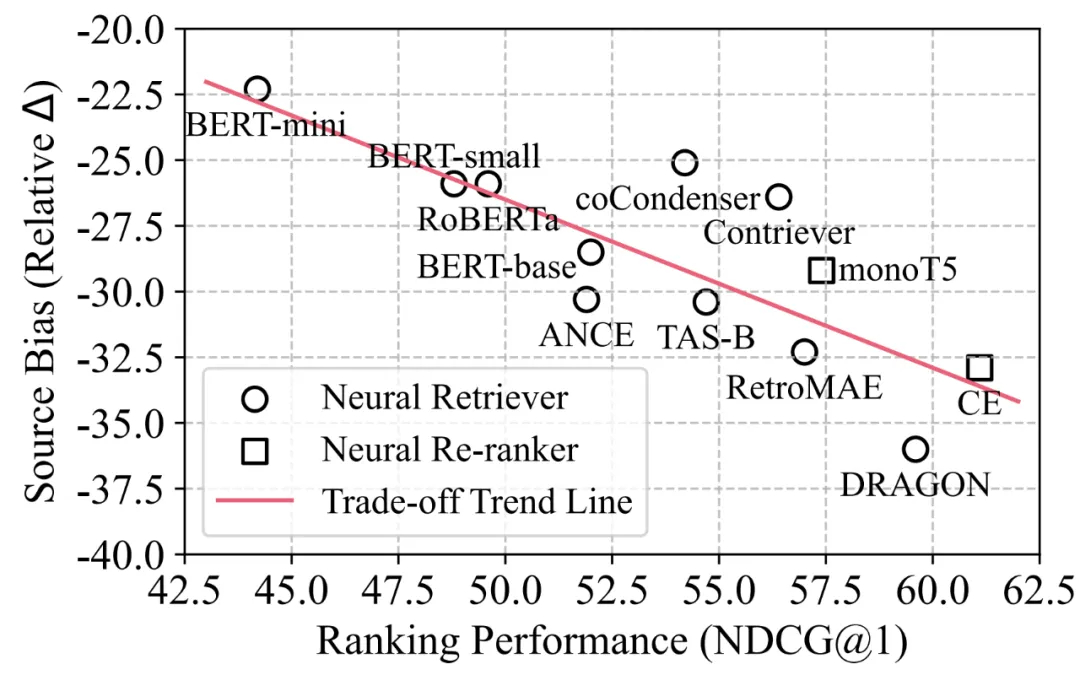
论文概述:大语言模型 (LLM) 的快速发展导致人工智能生成的内容 (AIGC) 大量涌入互联网,信息检索 (IR) 系统的语料库也逐渐从完全由人类编写转变为人类文本与LLM生成的文本共存。AIGC的激增对IR系统的影响仍然是一个亟需研究的问题,其中主要挑战是缺乏针对LLM时代的IR Benchmark。为此,我们提出了一个在LLM时代的混合数据源环境中为评估IR模型而量身定制的全面基准测试Cocktail。Cocktail由16个不同的IR数据集组成,其中包含8个文本检索任务和6个领域的人工编写和LLM生成的混合语料库,可以支持In-Domain和Out-of-Domain的评测。此外,为了避免LLM包含之前收集的IR数据集中的信息,从而带来评测时的潜在偏差,我们还收集了一个最新的QA数据集NQ-UTD,其中的query源自2023年11月至2024年1月新发生的热点事件。Cocktail上的1,000多组实验揭示了神经检索模型中排序性能和源偏差之间存在显著的负相关关系,强调了未来设计新的检索模型时平衡排序性能和源偏差的必要性。我们希望Cocktail能够成为LLM时代IR研究的重要资源,完整的数据集和详细的评估代码近期会开源。
论文题目:Effective In-Context Example Selection through Data Compression
作者:孙忠祥*,张珂镨*,王浩喻,张骁,徐君
通讯作者:徐君
论文概述:上下文学习在大型语言模型中得到了广泛验证。然而,选择上下文示例的机制和策略缺乏系统和深入的研究。语言模型在训练过程中压缩了世界知识,上下文学习过程中是否也能从数据压缩中得到提升?本文提出了一种用于选择上下文示例的数据压缩方法。我们引入了一种两阶段方法,可以有效地选择上下文示例并在上下文示例中保留训练数据集的充分信息。
论文题目:Improving Large Language Models via Fine-grained Reinforcement Learning with Minimum Editing Constraint
作者:陈志朋*,周昆*,赵鑫,万峻辰,张富峥,张迪,文继荣
通讯作者:赵鑫
论文概述:强化学习(Reinforcement Learning,RL)已被广泛应用于大语言模型(Large Language Models,LLMs)的训练过程中,旨在减少大语言模型产生预期外的回复,例如,减少有害的回复和消除回复中的错误信息。然而,现有的强化学习方法主要采用实例级别的奖励作为监督信号。在复杂推理任务中(如数学推理),这类粗粒度的监督信号无法引导模型关注到推理过程中细粒度的错误,从而影响强化学习在提升大语言模型推理能力方面的效果。因此,强化学习训练无法找到实际导致模型响应不正确的特定部分或步骤。为了解决强化学习无法提供细粒度监督信号的问题,我们提出了一种新的强化学习算法,名为RLMEC。不同于传统强化学习算法中使用判别式模型作为奖励模型,RLMEC使用一个生成式模型作为奖励模型。模仿人类学习者的学习方式,策略模型(即待训练的大语言)针对题目生成解答,生成式奖励模型标注解答中每一个词元是否正确。此外,生成式奖励模型通过尽可能少的修改策略模型的解答得到正确答案,该正确答案可以引导策略模型纠正自己的错误。为了实现这一目标,RLMEC算法训练生成式奖励模型在最小编辑约束下对错误答案进行改写。这个训练任务可以训练生成式奖励模型为强化学习训练提供词元级别的监督信号。基于生成式奖励模型,我们设计了词元级别的强化学习目标进行训练,并设计了一种基于模仿学习的正则化方法来稳定强化学习过程。这两个目标都侧重于修正错误解答中的关键词元,减少其他不重要词元对模型训练的影响。在8个复杂推理任务上的实验结果证明了我们方法的有效性。
论文题目:Data-CUBE: Data Curriculum for Instruction-based Sentence Representation Learning
作者:闵映乾*, 周昆*, 高大伟, 赵鑫,胡鹤,李雅亮
通讯作者:赵鑫
论文概述:最近,多任务指令微调已被应用于句子表示学习,这赋予了模型在任务指令的指导下生成特定表示的能力,并展示了在新任务上的强大泛化能力。然而,这些方法大多忽视了不同任务和实例之间潜在的干扰问题,这可能会影响模型的训练和收敛。为了解决这个问题,我们提出了一种数据课程方法,即Data-CUBE,它通过安排所有多任务数据的训练顺序来最小化来自两个方面的干扰风险。在任务层面,我们旨在找到最佳的任务顺序,以最小化总的跨任务干扰风险,这实际上是一个旅行商问题,因此我们采用模拟退火算法来找到其解决方案。在实例层面,我们衡量每个任务中所有实例的难度,然后将它们划分为由易到难的小批次进行训练。MTEB句子表示评估任务上的实验表明,我们的方法可以提升最先进方法的性能。
论文题目:Batch-ICL: Effective, Efficient, and Order-Agnostic In-Context Learning
作者:张凯翼*, 吕昂*, 陈雨涵, 哈瀚森, 许涛, 严睿
通讯作者:严睿
论文概述:我们将上下文学习(ICL)视为一个元优化过程,解释了为什么大型语言模型对于ICL示例的顺序敏感。这种理解帮我我们提出了Batch-ICL,这是一个针对ICL的有效、高效且顺序无关的推理算法。与标准的N-shot ICL不同,Batch-ICL采用了N个单独的1-shot 前向计算,并汇总了产生的元梯度。然后,将这些聚合的元梯度应用于Zero-shot Query的前向计算中,以生成最终预测。这种批处理方法使得语言模型不受ICL示例顺序的影响。通过大量实验和分析,我们证明了Batch-ICL始终优于N个ICL示例的全部排列组合中的大多数。在某些情况下,它甚至超过了标准ICL的最佳顺序的性能,同时减少了所需的计算资源。此外,我们提出了Batch-ICL的一种新型变体,其中包含多个“训练周期”的元优化。这种变体高效地,隐式地,穷举了N-shot ICL示例的排列组合,进一步提高了ICL的性能。
论文题目:CycleAlign: Iterative Distillation from Black-box LLM to White-box Models for Better Human Alignment
作者:洪吉祥*,涂权*,陈畅与,高星,张佶,严睿
通讯作者:严睿
论文概述:大规模语料库训练的语言模型往往会生成有害且违背人类价值观的回应。常见的人类对齐方法是通过人类反馈的强化学习(RLHF),使用如近端策略优化(PPO)等算法。然而,这些方法通常具有复杂性、不稳定性和资源消耗大的特点。考虑到现有的大型语言模型(如ChatGPT)已经相对较好地实现了对齐且成本较低,研究人员提出通过人工智能反馈来对齐语言模型与人类偏好。然而,常见的单向蒸馏响应的方法受到LLM内在能力的限制,对齐效果有限。为了解决这一问题,本文引入了CycleAlign框架,以迭代合作的方式将参数不可见模型(黑盒)的对齐能力蒸馏到参数可见模型(白盒)中。CycleAlign通过整合静态和动态上下文学习及信念对齐方法,迭代地改进白盒和黑盒模型。实证结果表明,通过CycleAlign微调的模型显著超越了现有方法,在与人类价值观的对齐方面达到了最新的性能水平。
论文题目:BioT5+: Towards Generalized Biological Understanding with IUPAC Integration and Multi-task Tuning
作者:裴启智,吴郦军,高开元,梁孝转,方尹,祝金华,解曙方,秦涛,严睿
通讯作者:吴郦军,严睿
论文概述:计算生物学的研究趋势日益倾向于对文本与生物实体进行联合建模,特别是对于分子和蛋白质。然而,之前的许多工作在多种任务的泛化上面临挑战,且缺乏对分子结构的细粒度理解,尤其是它们的文本表达(例如 IUPAC 命名法)方面。这篇论文介绍了BioT5的扩展版本 BioT5+。BioT5+ 引入了几项新功能:整合 IUPAC 名称以增强对分子的理解、引入来自 bioRxiv 和 PubChem 的大规模生物文本和分子数据、针对任务通用性的多任务指令调优,以及特殊的数值分词,用于改善对数值数据的处理。这些增强的功能使 BioT5+ 能够在分子表征及其文本描述之间架起桥梁,为生物实体提供更全面的理解,并大幅提升生物文本和生物序列的理解能力。通过大规模的预训练和微调,包含3种问题类型(分类、回归、生成)、15种任务和21个基准数据集,BioT5+ 在大多数情境下展示出了卓越的结果。
论文题目:Disperse-Then-Merge: Pushing the Limits of Instruction Tuning via Alignment Tax Reduction
作者:付廷琛,蔡登,刘乐茂,史书明,严睿
通讯作者:蔡登,严睿
论文概述:在指令数据集上的监督微调(SFT)是大模型对齐的一种重要方法。然而,在经过监督微调之后,大模型往往表现出在传统的知识和推理任务上的性能下降,也就是“对齐税”现象。通过实验我们提出指令数据集中的偏置可能是导致对齐税的一个重要原因。为了解决这一问题,我们提出了一种简单而有效的分治算法:我们将数据分为若干份并训练若干个模型并将训练所得的若干模型融合为一个模型。我们的方法简单有效,在一系列传统的知识和推理基准上超过了之前的数据选择、引入正则化项等一系列解决对齐税的方法。
论文题目:Graph-Structured Speculative Decoding
作者:龚卓成,刘家豪,王子悦,吴鹏飞,王金刚,蔡勋梁,赵东岩,严睿
通讯作者:严睿,赵东岩
论文概述:推测性解码已经成为一种有前途的技术,通过利用一个小型语言模型起草假设序列来加速大型语言模型(LLMs)的推理过程,然后由LLM验证。这种方法的有效性在很大程度上取决于起草模型性能和效率之间的平衡。在我们的研究中,我们专注于通过生成多个假设而不仅仅是一个来提高被接受到最终输出的起草标记的比例。这使得LLM有更多的选择,并选择符合其标准的最长序列。我们的分析表明,起草模型产生的假设共享许多常见的标记序列,暗示了优化计算的潜力。利用这一观察结果,我们引入了一种创新方法,利用有向无环图(DAG)来管理起草的假设。这种结构使我们能够高效地预测和合并重复出现的标记序列,大大减少了起草模型的计算需求。我们将这种方法称为图结构化推测解码(GSD)。我们在一系列LLMs上应用了GSD,包括一个700亿参数的LLaMA-2模型,观察到了显著的加速效果,速度提升了1.70倍到1.94倍,明显超过了标准的推测解码。
论文题目: SCALE: Synergized Collaboration of Asymmetric Language Translation Engines
作者: 程信, 王荀, 葛涛, Si-Qing Chen, 韦福如, 赵东岩, 严睿
通讯作者:赵东岩, 严睿
论文概述: 在本文中,我们提出了SCALE,一个创新的协作框架,它将一个紧凑的专用翻译模型(STM)与通用的大型语言模型(LLM)结合为一个统一的翻译引擎。通过将STM的翻译引入到三元组上下文示范中,SCALE激发了LLM的修饰和pivoting能力,从而1) 减轻了LLM的语言偏见和STM的并行数据偏见,2) 在不牺牲通用性的情况下增强了LLM的专业性,以及3) 以无需调整LLM的方式促进持续学习。我们的全面实验表明,SCALE在高资源或挑战性低资源环境中显著优于LLMs(GPT-4,GPT-3.5)和监督模型(NLLB,M2M)。此外,SCALE通过仅更新轻量级的STM并持续改进系统,平均在4种语言上提升了4 BLEURT分数,而无需调整LLM。有趣的是,SCALE还能有效地利用LLM的现有语言偏见,使用以英语为中心的STM作为枢纽,执行任何语言对之间的翻译,在八个翻译方向上平均优于GPT-4达6 COMET分。此外,我们还提供了对SCALE的鲁棒性、翻译特性、延迟成本和固有语言偏见的深入分析,为未来研究探索LLMs与更专业模型之间的潜在协同提供了坚实的基础。
论文题目:ETAS: Zero-Shot Transformer Architecture Search via Network Trainability and Expressivity
作者:杨杰超,刘勇
通讯作者:刘勇
论文概述:Transformer 架构搜索(Transformer Architecture Search,TAS)方法旨在自动搜索给定任务的最优 Transformer 架构配置。然而,由于评估 Transformer 架构性能的成本过高,阻碍了Transformer 架构的自动搜索。最近,一些方法提出零样本 TAS以缓解这一问题, 它们通过利用零成本代理在不进行训练的情况下评估 Transformer 架构。然而,这些方法仅限于特定任务,并且缺乏理论保证。为了解决这一问题,我们开发了一种新的零成本代理 NTSR,它结合了两个理论启发指标,分别衡量 Transformer 网络的可训练性和表达能力。随后,我们将其整合到一个有效的正则化进化框架 ETAS 中,并在各种任务上展示了其有效性。结果表明,我们提出的 NTSR 代理在计算机视觉和自然语言处理任务中,能够始终如一地与 Transformer 网络的真实性能表现出更高的相关性。此外,它还可以显著加速寻找最佳表现 Transformer 网络架构配置的搜索过程。
论文题目:Towards Tracing Trustworthiness Dynamics: Revisiting Pre-training Period of Large Language Models
作者:钱辰*,张杰*,姚巍*,刘东瑞,尹榛菲,乔宇,刘勇,邵婧
通讯作者:刘勇,邵婧
论文概述:确保大语言模型(LLMs)的可信(trustworthiness)至关重要。当下大多数研究集中在完全预训练的LLMs上,以更好地理解和提高LLMs的trustworthiness能力。在本文中,为了揭示预训练阶段的未开发潜力,我们开创性地探索了在这个时期的LLMs的可信能力,重点关注五个关键维度:可靠性、隐私、毒性、公平性和鲁棒性。首先,我们对LLMs应用线性探针技术,高探测准确率表明,在早期预训练阶段,LLMs已经能够区分每个trustworthiness维度中的概念。因此,为了进一步揭示预训练的隐藏可能性,我们从LLMs的预训练切片提取引导向量来增强LLMs的trustworthiness能力。最后,受到理论结果的启发,即互信息估计受到线性探针准确性的约束,我们使用互信息对LLMs进行探测,以研究预训练期间trustworthiness的动态变化。在这篇论文中,我们首次在LLMs预训练过程中观察到类似传统DNNs训练过程的两阶段现象:先拟合后压缩。这项研究为LLMs预训练期间的trustworthiness建模提供了初步探索,旨在揭示新的见解并推动该领域的进一步发展。
论文题目:DebugBench: Evaluating Debugging Capability of Large Language Models
作者:田润初,叶奕宁,秦禹嘉,从鑫,林衍凯,潘寅旭,吴叶赛,惠浩添,刘伟川,刘知远,孙茂松
通讯作者:林衍凯,刘知远,孙茂松
论文概述:大语言模型(LLMs)在编程能力方面表现出色。然而,作为编程能力的另一关键组成部分,LLMs的程序修复能力仍相对未被探索。先前对LLMs程序修复能力的评估因数据泄漏风险、数据集规模和测试的错误种类多样性而受到显著限制。为了克服这些不足,我们提出了DebugBench,一个包含4,253个实例的LLM程序修复基准。它涵盖了四大错误类别和18种类型,适用于C++、Java和Python。为了构建DebugBench,我们从LeetCode社区收集代码片段,通过GPT-4将错误植入源数据,并确保严格的质量检查。我们在零样本场景中评估了两个商业模型和三个开源模型。我们的发现如下:(1) 尽管像GPT-4这样的闭源模型在程序修复性能表现还不错,但相比人类表现仍然较差,同时开源模型如Code Llama几乎没有该能力;(2) 程序修复的难度显著因错误类别而波动;(3) 利用运行时反馈对程序修复性能有明显影响,但并非总是有帮助。作为扩展,我们还比较了LLM的程序修复和代码生成能力,发现闭源模型在这两者之间存在强相关性。这些发现将有助于LLMs在程序修复方面的发展。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox