学院新闻
我院师生论文被国际学术会议SIGIR 2024录用
日期:2024-04-08访问量:3月26日,国际学术会议SIGIR 2024论文接收结果公布。中国人民大学高瓴人工智能学院师生有15篇论文被录用(10篇长文、1篇数据集、2篇短文、2篇demo)。The 47th International ACM SIGIR Conference on Research and Development in Information Retrieval(简称SIGIR ),是中国计算机学会(CCF) 推荐的A类国际学术会议,在信息检索及相关领域享有很高的学术声誉,会议将于2024年7月14-18日在美国华盛顿召开。

论文题目:CorpusLM: Towards a Unified Language Model on Corpus for Knowledge-Intensive Tasks (Full Paper)
作者:李晓熙,窦志成,周雨佳,刘方超
通讯作者:窦志成
论文概述:大语言模型(LLMs)在各个领域中获得了显著的关注,在需要访问外部信息的知识密集型任务上,容易出现“幻觉”。为了克服这一挑战,检索增强生成(RAG)可以通过结合检索机制,来提高生成内容的事实性。然而,传统的检索方法依赖于庞大的文档索引,这与生成模型的结构存在脱节。最近,生成式检索(GR)技术的发展,使得语言模型能够通过直接生成文档标识符(DocIDs)来进行检索,展现出了更好的检索性能。然而,GR与下游任务之间的关系,以及在GR中利用LLMs的潜力,还有待进一步探索。本文提出CorpusLM,一个统一的语言模型,旨在通过利用外部语料库,集成生成式检索、闭卷生成以及RAG,来有效地处理各种知识密集型任务。我们通过统一的贪心解码过程,以及设计了一系列机制,来进一步增强知识密集型任务中检索和生成的性能:(1)我们提出了一个面向排序的DocID列表生成策略,通过从DocID排名列表中学习,以提升生成式检索性能;(2)我们设计了一个连续的DocIDs-References-Answer解码策略,以实现更有效、更高效的检索增强生成;(3)我们引入了无监督DocID理解任务,旨在深入理解DocID的语义及其与下游任务的关联性。我们在KILT基准上对我们的方法进行了评估,使用了包括T5和Llama2在内的两种骨干模型。实验结果证明,我们的模型在检索和下游任务上都展现了优越的性能。
论文题目:Generative Retrieval via Term Set Generation (Full Paper)
作者:张配天,刘政,周雨佳,窦志成, Fangchao Liu,曹朝
通讯作者:窦志成
论文概述:生成式检索要求模型根据查询精准生成相关文档的标识符,一旦生成过程某一步出错,则相关文档无法被召回,极大限制了检索的精度。为了解决这一问题,本工作提出TSGen,其使用一个关键词集合作为文档标识符 (Term-Set DocID),这些词由选词模块经过端到端学习得到,能够全面且精简地概括文档内容;基于这样的文档标识符,我们设计了序等变解码 (Permutation-Invariant Decoding),使得文档的词集合标识符中的关键词能以任何顺序生成,即所有可能的词序均会指向对应的文档。相比于传统文档标识符 (一个自然语言序列),模型在解码时拥有更广泛的视野:其不会受到前缀树的限制,而是能够从候选文档的所有词中选择下一个要生成的词,从而在看到更多信息的情况下做出正确决定;同时模型在解码时拥有更大的容错空间:即使模型在某一步解码中犯错,只要生成的词属于相关文档的词集合标识符,则相关文档仍然能够被召回。在生成式检索的常用测评基准上,TSGen获得了显著优于现有baseline的检索精度。
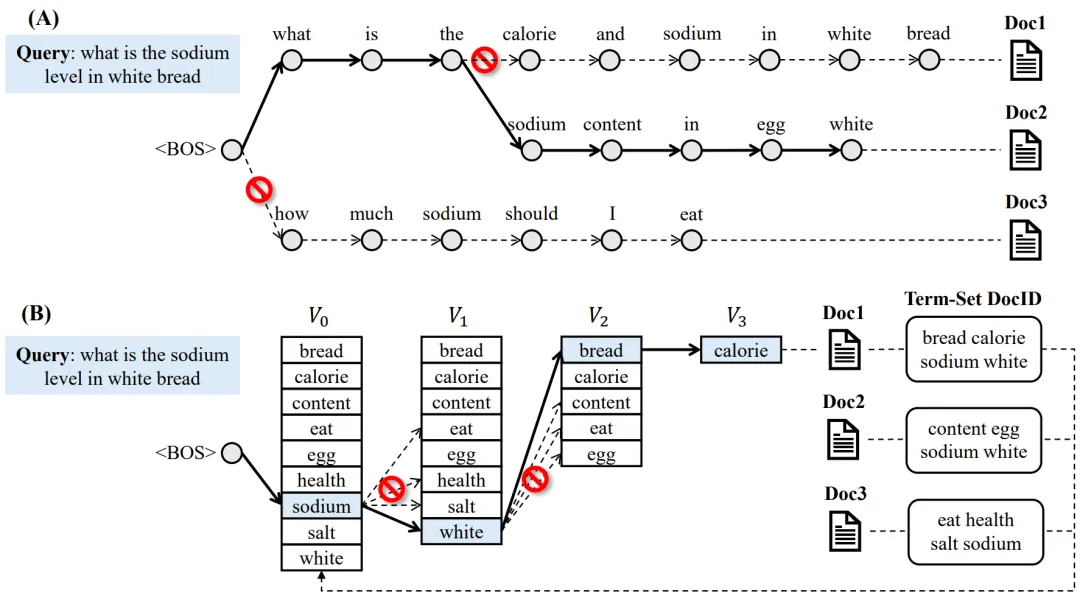
论文题目:EulerFormer: Sequential User Behavior Modeling with Complex Vector Attention (Full Paper)
作者:田震,赵鑫,张长旺,赵鑫,马中瑞,文继荣
通讯作者:赵鑫
论文概述:Transformer模型已被广泛应用于序列数据建模。它的核心在于自注意机制。其中Query-Key的注意力分数通常由语义差异和位置差异构成。然而,先前的研究通常以不同的方式对这两种差异进行建模,这可能限制了序列建模的表达能力。为了解决这个问题,本文提出了一种新型的Transformer架构-EulerFormer,它提供了一个统一的理论框架来表达语义差异和位置差异。具体来讲,EulerFormer采用了一种新的变换函数,通过欧拉公式将序列词元高效地转换成极坐标形式的复向量,从而实现了语义和位置信息的统一建模。其次,我们提出了一种差分旋转机制,其中语义旋转角度可以由自适应函数控制,根据语义上下文实现语义和位置信息的自适应融合。此外,我们还提出了一种相位对比学习任务,以改善 EulerFormer 中上下文表示的各向异性。我们的理论框架具有高度完备性和泛化性(例如,RoPE 可以作为一种EulerFormer的一种特例)。EulerFormer对语义变化更为鲁棒,并且具有更优越的理论性质(例如,可控远程距离衰减)。在四个公开数据集上进行的大量实验证明了我们方法的有效性和效率。
论文题目:Explicitly Integrating Judgment Prediction with Legal Document Retrieval: A Law-Guided Generative Approach (Full Paper)
作者:秦维聪,曹泽麟,俞蔚捷,思子华,陈思睿,徐君
通讯作者:徐君
论文概述:法律文档检索和判决预测是智能法律系统中至关重要的任务。在实践中,确定两个文档是否共享相同的判决对于确定它们在法律检索中的相关性至关重要。然而,现有的法律检索研究要么忽视了判决预测的重要作用,要么依赖于隐式的训练目标,期望根据其判决在向量空间中对法律文档进行适当的对齐。这两种方法都没有为相关性建模提供判决一致性的明确证据,导致检索的潜在不准确性和不透明性。为解决此问题,我们提出了一种法律引导的检索方法,称为GEAR,以序列到序列的方式显式地将判决预测与法律文件检索明确地结合起来。具体来说,GEAR基于法律罪名定义从法律文档中提取理由,并构建法律结构约束树为法律文档分配语义ID,在单次推断中实现了对两个法律任务的双重预测。实验表明,GEAR在两个中文法律案例检索数据集上优于最先进方法,且具备跨语言和领域的鲁棒性。
论文题目:A Taxation Perspective for Fair Re-ranking (Full Paper)
作者:徐晨,叶潇芃,王文杰,庞亮,徐君,Tat-Seng Chua
通讯作者:徐君,王文杰
论文概述:公平重排序问题旨在更公平地在物品之间重新分配排名槽位,以达成一个有责任和道德的排序系统。在经济学领域,对重新分配问题的探索有着悠久的历史,为将公平重新排名概念化为一种税收过程提供了宝贵的见解。直观地说,公平重排序可以被概念化为对高曝光的物品征税,并将其重新分配给较少曝光较少的物品。这样的表述为我们重新审视公平重排序提供了新的视角,并激发了新方法的发展。从税收的角度来看,我们在理论上证明了大多数先前的公平重排序方法可以重新表述为单个物品级税收政策。理想情况下,良好的税收政策应该是有效的,并且方便控制以调整排名资源。然而,无论是实证分析还是理论分析都表明,先前的单个物品级税收政策都无法满足两个理想的可控要求:(1)连续性,确保税率的微小变化导致准确性和公平性的小幅变化;(2)对准确性损失的可控性,确保在特定税率下对准确性损失的精确估计。为了克服这些挑战,我们引入了一种名为“Tax-rank”的新的公平重新排名方法。Tax-rank引入了一个独特的优化目标,根据两个物品之间效用差异来征税。然后,我们通过在最优传输中利用Sinkhorn算法来高效地优化这样的目标。在全面分析之后,Tax-rank为公平重新排名提供了一个改进的税收政策,从理论上证明了在准确性损失方面的连续性和可控性。在实验中,我们将Tax-rank应用于两个公开可用的数据集,分别针对推荐和广告任务。实验结果显示,Tax-rank在效果和效率方面均优于所有基线方法。
论文题目:UniSAR: Modeling User Transition Behaviors between Search and Recommendation (Full Paper)
作者:石腾,思子华,徐君,张骁,臧晓雪,郑凯,冷德维,牛亚男,宋洋
通讯作者:徐君
论文概述:如今,许多平台为用户提供了搜索和推荐服务,作为用户获取信息的重要工具。这种现象导致用户搜索和推荐行为之间存在相关性,为细粒度地建模用户兴趣提供了机会。现有方法或者分别对用户搜索和推荐行为进行建模,或者忽视了用户搜索和推荐行为之间的不同转换。本文提出了一个名为UniSAR的框架,有效地建模了不同类型的细粒度的行为转换,以为用户提供统一的搜索和推荐服务。具体而言,UniSAR通过三个步骤对用户在搜索和推荐之间的转换行为进行建模:提取、对齐和融合,分别由带有预定义掩码机制的Transformer、将提取的细粒度用户转换进行对齐的对比学习模块,以及融合不同转换的交叉注意力机制来实现。为了给用户提供统一的服务,学习到的表示被输入到下游搜索和推荐模型中。在搜索和推荐数据上进行联合学习,以利用两个任务上的知识来相互增强。在两个公共数据集上的实验结果证明了UniSAR对于同时增强搜索和推荐结果的有效性。实验分析进一步验证了UniSAR通过成功建模搜索和推荐之间的用户转换行为来提升效果。
论文题目:To Search or to Recommend: Predicting Open-App Motivation with Neural Hawkes Process (Full Paper)
作者:孙忠祥,思子华,张骁,臧晓雪,宋洋,许洪腾,徐君
通讯作者:徐君
论文概述:在线服务平台如快手,抖音,淘宝等,普遍将搜索与推荐服务整合至单一应用中,这也就催生了一个新的任务——预测用户打开应用的动机。该任务旨在预测用户启动应用的意图是为了搜索特定信息还是探索推荐内容以获取娱乐。在快手平台内部的分析中,预测用户打开应用的动机能够帮助提升用户使用体验并在各种下游场景中取得用户时长的提升。然而,准确预测用户打开应用动机并非易事,它受到用户个人的偏好,历史搜索推荐行为以及时间等因素的影响。受到神经霍克斯过程(NHP)可以有效建模事件序列任务的启发,本文提出了一种新颖的神经霍克斯过程模型,以捕捉历史用户浏览和搜索行为之间的时间依赖性。该模型被称为NHP-OAM,我们采用了层次化 transformer和一个新颖的强度函数来编码多因素影响,并通过打开应用动机预测层来整合时间和用户偏好信息,以预测用户的打开应用的动机。为了展示我们的NHP-OAM模型的优越性并为打开应用动机预测任务构建基准,我们不仅扩展了公开的S&R数据集ZhihuRec,还构建了一个新的真实世界开放应用动机数据集(OAMD)。在这两个数据集上的实验验证了NHP-OAM模型相较于基准模型的优越性。进一步的下游应用实验展示了NHP-OAM在预测用户打开应用动机方面的有效性,凸显了NHP-OAM的巨大应用价值。
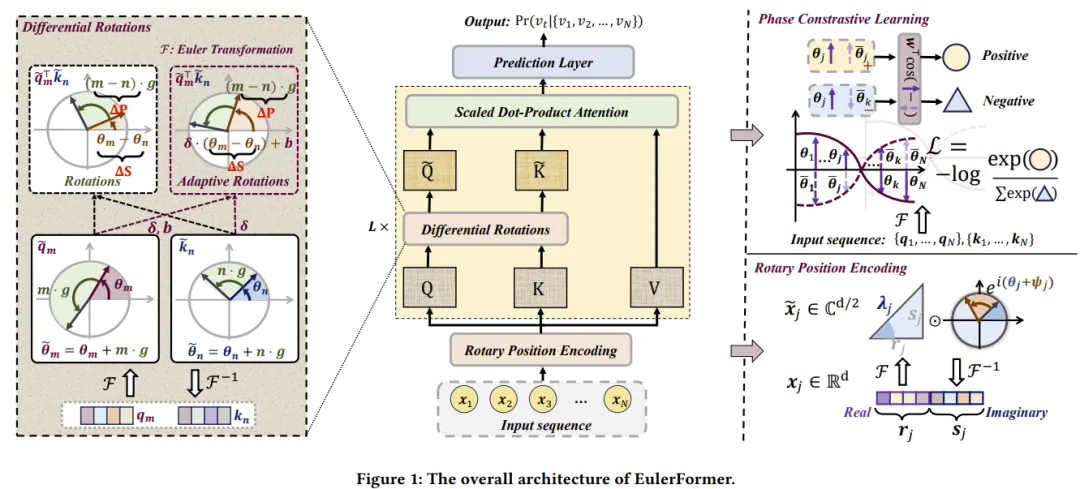
论文题目:Reinforcing Long-Term Performance in Recommender Systems with User-Oriented Exploration Policy (Full Paper)
作者:张昌硕*,陈思睿*,张骁,戴孙浩,俞蔚捷,徐君
通讯作者:张骁
论文概述:强化学习旨在以探索—利用折衷的方式达到序列决策的收益最大化,其部署到推荐系统中可有效探索用户的潜在兴趣。然而,当前推荐系统常面临着用户行为模式差异大的挑战,使得强化学习策略的探索变得困难。例如,不同活跃度的用户本质上需要不同强度的个性化探索方式。已有基于强化学习的序列决策推荐模型常使用数据独立的探索方法,并将其应用于全部用户,引发的低探索效率问题影响了长期的用户体验,阻碍了推荐系统的可持续发展。为解决这些挑战,本文提出了面向用户的个性化探索策略(UOEP),其能够在用户群体中实现精细化探索的新方法。首先,UOEP构建了一个基于分布的价值估计器,其可基于用户累积奖励的不同分位数水平进行策略优化,服务于具有不同活跃度水平的用户群体。利用该价值估计器,进而设计了一组专注于在不同用户群体内进行有效探索的决策器,其可在强化学习探索过程中同时增强多样性和稳定性,更有效的获得用户级别的探索—利用折衷。公开数据集上的实验结果表明UOEP在推荐系统长期收益方面的有效性,也验证了UOEP可改善低活用户的体验并增加用户间的个体公平性。
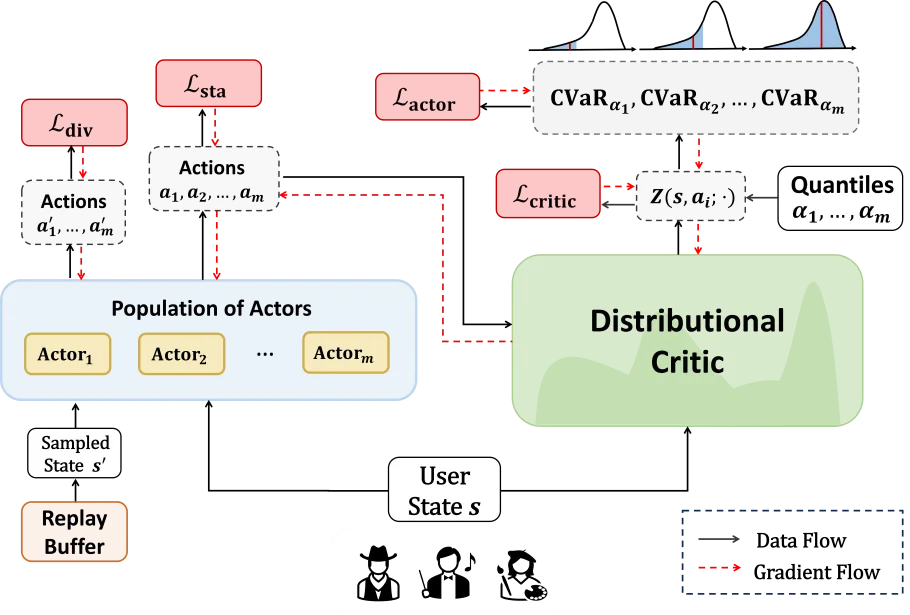
论文题目:Invisible Relevance Bias: Text-Image Retrieval Models Prefer AI-Generated Images (Full Paper)
作者:徐士成,侯丹阳,庞亮,邓竞成,徐君,沈华伟,程学旗
通讯作者:庞亮
论文概述:随着生成模型的应用,互联网日益充斥着由AI生成的内容(AIGC),导致真实内容和AI生成的内容都被索引到搜索的语料库中。本文探讨了在这种情况下,AI生成的图像对文本-图像搜索的影响。首先,我们构建了一个包含真实图像和AI生成图像的基准测试,用于这项研究。在这个基准测试中,AI生成的图像具有与真实图像足够相似的视觉语义。对这个基准测试的实验揭示,文本-图像检索模型倾向于将AI生成的图像排在真实图像之前,即使AI生成的图像并没有比真实图像更多地展示与查询相关的视觉语义。我们将这种偏见称为无形的相关性偏见。这种偏见在不同训练数据和架构的检索模型中都被检测到,包括从头开始训练的模型和那些在大量图像-文本对上预训练的模型,包括双编码器和融合编码器模型。进一步的探索揭示,将AI生成的图像混入检索模型的训练数据会加剧无形的相关性偏见。这些问题导致了一个恶性循环,即AI生成的图像有更高的机会从大量数据中被暴露出来,这使得它们更有可能被混入检索模型的训练中,而这样的训练使得无形的相关性偏见越来越严重。为了解决上述问题并阐明无形相关性偏见的潜在原因,首先,我们引入了一种有效的训练方法来减轻这种偏见。随后,我们应用我们提出的去偏方法来追溯识别无形相关性偏见的原因,揭示出AI生成的图像诱导图像编码器将额外的信息嵌入到它们的表示中,这些信息使得检索器估计出更高的相关性分数。本文的发现揭示了AI生成的图像对文本-图像检索的潜在影响,并对进一步的研究有所启示。
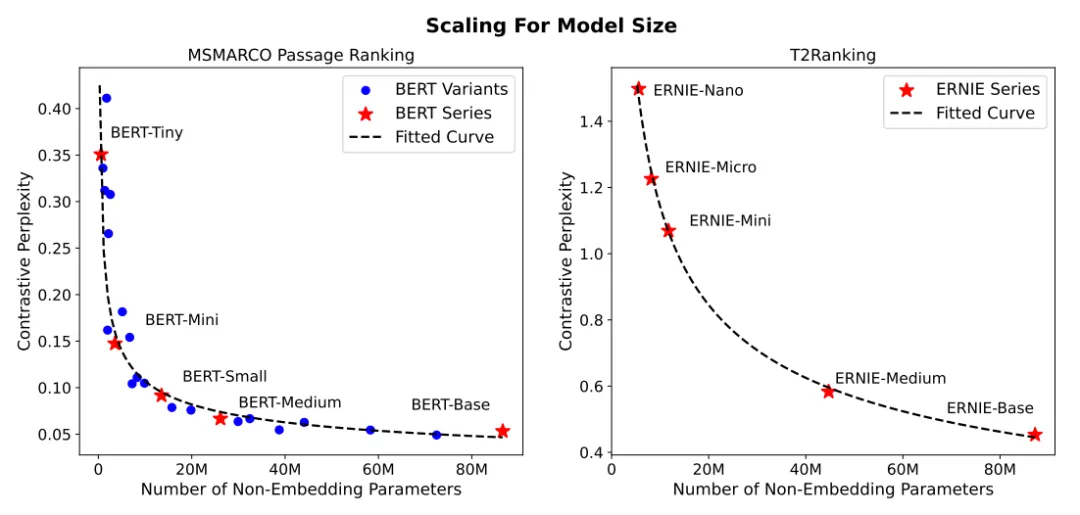
论文题目:Scaling Laws for Dense Retrieval(Full Paper)
作者:方言,詹靖涛,艾清遥,毛佳昕,苏炜航,陈佳,刘奕群
论文概述:扩大神经网络模型的规模能够在多种任务上显著提升模型性能。已有工作进一步表明,神经网络模型的性能会遵循一定的扩展定律(Scaling law)。基于扩展定律,我们可以预测训练集大小和模型大小等因素对模型性能的影响。本研究尝试探究在检索任务中,基于神经网络构建的稠密向量检索模型的性能是否也满足一定的扩展定律。我们提出使用与训练损失函数类似的对比困惑度(Contrastive Perplexity)代替现有的检索指标,作为主要的评价指标。对于具有不同参数规模的检索模型,测试其在使用不同数据规模的标注数据进行训练的情况的检索性能。大量实验结果表明,在该设置下,稠密向量检索模型的性能遵循与模型参数规模和标注数据规模相关的幂律函数关系。我们进一步探索了使用数据增强方式生成训练数据对扩展定律参数的影响。最终,我们讲得到扩展定律应用于训练资源分配任务,分析了在预算有限的情况下,应如何选择模型参数规模和训练数据规模。本研究将有助于理解基于神经网络的稠密向量检索模型的扩展效果,并为了未来的研究工作提供有益的指导。
论文题目:JDivPS: A Diversified Product Search Dataset (Resource paper & Repro track)
作者:邓智睿,窦志成,朱余韬,秦旭博,程鹏超,吴江旭,王浩
通讯作者:窦志成
论文概述:产品搜索多样化通过提供多样的产品以满足不同的用户意图。现有的产品搜索多样化方法主要依赖来自在线平台的数据集。然而,由于这些数据集通常不公开,并且缺乏人工标记的用户意图,这些局限性可能导致实验结果不可复现,限制了该领域的发展。为了解决这些问题,本文构造了一个用于产品搜索多样化的新数据集JDivPS。这是第一个具有人工标注用户意图的可公开访问的数据集。数据来源于中国最重要的电子商务平台之一--京东。它包括10000个查询,大约1680000个不同的产品,每个查询平均有10个人工标记的用户意图。我们在此数据集上评估了多种模型,并在论文中展示了这些模型在此数据集上的实验结果,作为未来产品搜索多样化工作的参考。
论文题目:ReCODE: Modeling Repeat Consumption with Neural ODE(Short Paper)
作者:戴孙浩,渠常乐,陈思睿,张骁,徐君
通讯作者:徐君
论文概述:在工业界的实际推荐系统场景中,比如音乐推荐,重复消费现象极为普遍,用户往往会反复多次听同一小批他们偏爱的歌曲或艺术家。要有效地建模这种重复消费行为,关键在于精准捕捉用户对特定物品重复消费间的时间规律。现有研究常常依赖于启发式假设,例如,假设消费间隔遵循指数分布。但鉴于现实世界中推荐场景的复杂性,这类预设的分布往往难以准确描绘出用户重复消费行为的复杂动态变化,从而导致推荐效果不理想。受到神经常微分方程(Neural ODE)在捕捉复杂系统动态特征方面的启发,我们设计了ReCODE——一种新的模型无关框架,它通过Neural ODE来建模重复消费行为。ReCODE主要由两部分构成:一是用户静态偏好的预测模块,二是用户动态重复意图的建模模块。通过同时考虑用户的即时选择和重复消费模式,ReCODE为目标上下文中的用户偏好提供了全面的建模。此外,ReCODE可以作为插件适配到多种现有的推荐模型中,包括基于协同过滤的和基于序列的推荐模型,使其易于在不同场景下应用。在两个真实世界数据集上的实验验证了ReCODE能够显著提升原始模型的推荐效果。
论文题目:USimAgent: Large Language Models for Simulating Search Users(Short Paper)
作者:张尔含,王星竹,公培元,林衍凯,毛佳昕
通讯作者:毛佳昕
论文概述:由于成本效益和可再现性方面的优势,用户模拟已成为信息检索系统面向用户评估的一种有前景的解决方案。然而,准确模拟用户的搜索行为长期以来一直是一个挑战,因为用户在搜索中的行为非常复杂,并受到学习、推理和规划等复杂的认知过程驱动。最近,大型语言模型(LLM)在模拟人类智能方面展示出了显著的潜力,并被用于构建各种任务的自主代理。然而,利用LLM模拟搜索行为的潜力尚未完全探索。在本文中,我们介绍了一种基于LLM的用户搜索行为模拟器,称为USimAgent。所提出的模拟器可以模拟用户在搜索过程中的查询、点击和停止行为,因此能够为特定的搜索任务生成完整的搜索会话。对真实用户行为数据集的实证研究表明,所提出的模拟器在查询生成方面优于现有方法,在预测用户点击和停止行为方面与传统方法相当。这些结果不仅验证了利用LLM进行用户模拟的有效性,也为开发更强大和通用的用户模拟器提供了启示。
论文题目:An Integrated Data Processing Framework for Pretraining Foundation Models(Demo)
作者:孙一丁*,王丰*,朱余韬,赵鑫,毛佳昕
通讯作者:毛佳昕
论文概述:基石模型的能力强烈依赖于大规模、多样化、高质量的预训练数据。为了提高数据质量,研究者和从业者通常需要手动维护不同来源的数据集,并为每个数据仓库开发专用的数据清理流水线。由于缺乏统一的数据处理框架,这个过程重复且繁琐。为了缓解这个问题,我们提出了一个数据处理框架 Yulan-GARDEN,该框架集成了由一系列不同粒度级别的运算符组成的处理模块和支持对数据进行探测和评估的分析模块。所提出的框架易于使用且高度灵活。在这篇论文中,我们首先通过一些使用场景来介绍如何使用该框架,接下来通过 ChatGPT 的自动评价和预训练 GPT-2 模型的端到端评价方式来证明其在数据质量提升方面的有效性。
论文题目:CoSearchAgent: A Lightweight Collaborative Search Agent with Large Language Models(Demo)
作者:公培元,李嘉勉,毛佳昕
通讯作者:毛佳昕
论文概述:协作搜索支持多个用户共同完成特定的搜索任务。研究发现,在即时通讯平台中设计轻量级协作搜索插件更符合用户的协作习惯。然而,由于多用户交互场景的复杂性,实现功能齐全的轻量级协作搜索系统具有挑战性。因此,以往的轻量级协同搜索研究不得不依赖于Wizard of Oz范式。近年来,大语言模型已被证明可以与用户自然交互,并通过基于大语言模型的代理助手实现复杂的信息查找任务。因此,为了更好地支持协作搜索的研究,在这个演示中,我们提出了CoSearchAgent,一个由大语言模型支持的轻量级协作搜索代理。CoSearchAgent被设计为一个Slack插件,可以支持该平台上多方对话期间的协作搜索。CoSearchAgent 能够理解多用户对话中的查询和上下文,并能够通过 API 在互联网上搜索相关信息,可以根据相关搜索结果提供答案来响应用户查询。当信息需求不清楚时,它还可以提出澄清问题。本文所提出的 CoSearchAgent可以稳定部署且易于修改,将有助于支持协作搜索的进一步研究。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox