学院新闻
我院师生论文被CCF A类会议NeurIPS 2023录用
日期:2023-09-27访问量:9月22日,中国计算机学会(CCF)推荐的A类国际学术会议NeurIPS 2023论文接收结果公布。中国人民大学高瓴人工智能学院师生有14篇论文被录用。神经信息处理系统大会(Neural Information Processing Systems,简称NeurIPS) 是机器学习和计算神经科学领域的顶级国际会议。NeurIPS 2023录用率为26.1%。

论文介绍
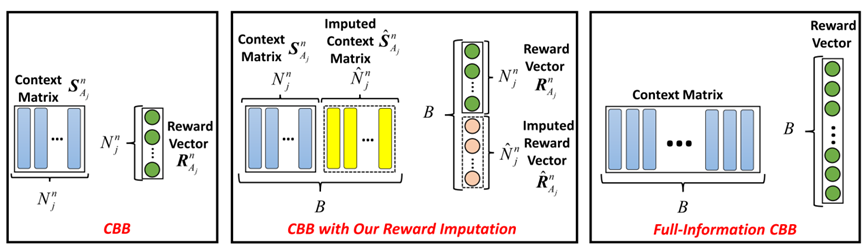
论文题目:Reward Imputation with Sketching for Contextual Batched Bandits
论文作者:张骁,邵宁录,思子华,徐君,王文瀚,苏函晶,文继荣
通讯作者:徐君
论文概述:部分信息反馈是在线决策任务中的基本设定,即决策算法仅能观测到所执行动作对应的反馈,这导致反馈信息未被充分利用。但为何不对未观测反馈进行建模和估计呢?本工作将因果纠偏方法引入到在线决策任务中,提出了一种有效的奖励插补(reward imputation)方法,并通过矩阵略图(sketching)方法降低了奖励插补的时间和空间复杂度。理论上,刻画了计算复杂度、更小方差、可控偏差三者间的关系,并依据理论结果给出了奖励插补的无参数版本。实验结果表明,所提出的奖励插补方法在合成数据、公开数据、以及实际推荐产品数据上的精度和效率均有显著提升。
论文介绍
论文题目:FABind: Fast and Accurate Protein-Ligand Binding
论文作者:裴启智*,高开元*,吴郦军,祝金华,夏应策,解曙方,秦涛,何琨,刘铁岩,严睿
通讯作者:严睿,吴郦军
论文概述:在药物发现中,模拟蛋白质与配体之间的相互作用并准确预测它们的结合结构是一个关键且具有挑战性的任务。近年来,深度学习在解决这一挑战上显示出巨大的潜力,其中基于采样和基于回归的方法成为两种主要的方法。然而,这些方法都有明显的局限性。基于采样的方法由于需要生成多个候选结构进行选择而经常效率低下。另一方面,基于回归的方法虽然可以提供快速的预测,但准确性较低。此外,不同蛋白质的大小不同,需要外部模块来选择合适的结合口袋,外部模块的引入会进一步影响效率。在这项工作中,我们提出了一个端到端模型FABind,结合口袋预测和对接,实现准确且快速的蛋白质-配体结合。FABind包含一个独特的基于口袋信息的配体预测模块,该模块也用于对接姿态估计。该模型通过使用预测的口袋来进一步增强对接过程,优化蛋白质-配体结合,减少训练和推理之间的差异。通过在基准数据集上的广泛实验,我们提出的FABind在效果和效率方面都显示出了强大的优势。
论文介绍
论文题目:Lift Yourself Up: Retrieval-augmented Text Generation with Self Memory
论文作者:程信,罗迪,陈秀颖,刘乐茂,赵东岩,严睿
通讯作者:严睿,赵东岩
论文概述:本文探究了一种基于自记忆信息的检索增强文本生成方法,通过结合检索增强文本生成中的主问题和对偶问题,提出了一个模型自举的框架,利用生成器和自记忆信息选择器以迭代的方式来不断利用模型自己的输出作为记忆信息来提升自己。本文提出的模型在机器翻译,文本摘要和对话生成任务上均取得了显著的提升。
论文介绍
论文题目:Bayesian Active Causal Discovery with Multi-Fidelity Experiments
论文作者:张泽宇,李朝卓,陈旭,谢幸
通讯作者:陈旭
论文概述:本文对Multi-fidelity设定下的主动因果发现进行了研究。与传统的Single-fidelity设定相比,Multi-fidelity设定引入了实验代价与实验精度之间权衡,因此更接近实际情况。本文首先对Multi-fidelity设定下的主动因果发现问题进行定义,并设计了概率模型解决该问题。我们设计了基于互信息的采集函数来确定干预的节点与fidelity,提出了级联模型来捕捉不同fidelity之间的关系,并将其扩展到多目标干预的场景。另外,本文通过定义epsilon-independence和epsilon-submodular,将传统贪心方法的下界进行一般化扩展。最后,本文通过实验验证了方法的有效性。
论文介绍
论文题目:Offline Imitation Learning with Variational Counterfactual Reasoning
论文作者:孙泽旭,何博威,刘金鑫,张帅,陈旭,马辰
通讯作者:陈旭
论文概述:在离线模仿学习中,agent的目标是学习最佳的专家行为策略,而无需额外的在线环境交互。然而,在许多现实场景中,例如机器人操作,离线数据集是从没有奖励的次优行为中收集的。由于专家数据稀缺,agent通常只能记住较差的轨迹,并且容易受到环境变化的影响,缺乏泛化到新环境的能力。为了有效地给agent提供更多的有用信息,增强学习出来的agent的泛化性能,我们提出了一个名为OILCA的框架。特别是,我们利用可识别的变分自动编码器来生成反事实样本。我们从理论上分析了反事实识别和泛化能力的提高。此外,我们进行了大量的实验来证明我们的方法在分布内鲁棒性的DeepMind Control Suite和分布外泛化的 CausalWorld 上显着优于各种基线。
论文介绍
论文题目:ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation(Spotlight)
论文作者:王征翊,路橙,王一凯,鲍凡,李崇轩,苏航,朱军
通讯作者:李崇轩,朱军
论文概述:我们针对文本到3D生成中的过度饱和、过度平滑和低多样性问题,提出了变分得分蒸馏(Variational Score Distillation, VSD)。与传统的得分蒸馏采样(SDS)不同,我们将3D参数建模为随机变量。VSD不仅改善了样本的多样性和质量,还很好地处理了各种CFG权重。我们的方法,ProlificDreamer,能生成高分辨率(512×512)和高保真的NeRF,且具有丰富的结构和复杂的效果(如烟雾和水滴)。同时,从NeRF初始化并由VSD微调的网格非常细致和逼真。
论文介绍
论文题目:Diffusion Models and Semi-Supervised Learners Benefit Mutually with Few Labels(Spotlight)
论文作者:游泽彬,钟勇,鲍凡,孙嘉城,李崇轩,朱军
通讯作者:李崇轩
论文概述:我们提出了一种简单有效的训练策略,称为双重伪训练(DPT),以进一步推进半监督生成和分类任务。DPT分为三个步骤:首先,在部分标记的数据上训练分类器以产生伪标签;接着,利用这些伪标签训练条件生成模型,生成伪图像;最后,结合真实图像和伪图像重新训练分类器。实验结果显示,在极少的标签数据(如<0.1%)下,扩散模型能够可控语义地生成高质量图像。此外,生成式增强对半监督分类任务也有显著的助益。
论文介绍
论文题目:Toward Understanding Generative Data Augmentation
论文作者:郑晨宇,吴国强,李崇轩
通讯作者:李崇轩
论文概述:生成式数据扩增通过条件生成模型生成新样本来扩展数据集,从而提高各种学习任务的分类性能。然而,很少有人从理论上研究生成数据增强的效果。为了填补这一空白,我们在这种非独立同分布环境下构建了基于稳定性的通用泛化误差界。基于通用的泛化界,我们进一步了探究了高斯混合模型和生成对抗网络的学习情况。在这两种情况下,我们证明了,虽然生成式数据增强并不能享受更快的学习率,但当训练集较小时,它可以在一个常数的水平上提高学习保证,这在发生过拟合时是非常重要的。最后,高斯混合模型的仿真结果和生成式对抗网络的实验结果都支持我们的理论结论。
论文介绍
论文题目:Gaussian Mixture Solvers for Diffusion Models
论文作者:郭瀚中,路橙,鲍凡,庞天宇,颜水成,杜超,李崇轩
通讯作者:杜超,李崇轩
论文概述:扩散概率模型的采样等价于求解对应逆向随机(常)微分方程,基于随机微分方程的采样可以产生更高质量的样本并且在下游任务中表现更好,但是其采样效率不高,我们发现是由于采样中的逆向转移核的高斯假设错误所导致的,因此我们提出了一种基于高阶矩的混合高斯转移核,我们方法在多个数据集中取得了加速效果。
论文介绍
论文题目:On Evaluating Adversarial Robustness of Large Vision-Language Models
论文作者:赵云清,庞天宇,杜超,杨啸,李崇轩,Ngai-Man Cheung,林敏
通讯作者:庞天宇,杜超,Ngai-Man Cheung
论文概述:大型视觉-语言模型(VLM,如GPT-4)在视觉输入响应上取得了显著成果,但其多模态生成引入了更大的安全隐患。攻击者可以通过对最脆弱的模态(如视觉)进行微调来规避系统。我们对几种预训练模型创建了目标对抗性示例,并在其它模型上进行了验证。值得关注的是,利用黑盒查询方法可以显著提高欺骗模型的成功率。这一发现强调了在实际部署大型VLM前,需对其进行更深入的安全性检查。
论文介绍
论文题目:Equivariant Spatio-Temporal Attentive Graph Networks to Simulate Physical Dynamics
论文作者:吴黎明,侯智超,袁基睿,荣钰,黄文炳
通讯作者:黄文炳
论文概述:本文介绍了一种名为ESTAG的模型,用于表示和模拟物理系统的动力学。传统的基于图神经网络的方法在处理物理系统动力学时忽视了非马尔科夫性质,即忽视了系统与未观测到的对象之间的相互作用。为了解决这个问题,本文提出利用历史轨迹来反映潜在和未观察到的动力学,并将动力学模拟重新定义为时空预测任务。为了实现这一目标,本文设计了ESTAG模型,其中包括使用EDFT模块提取周期性特征,以及ESM和ETM模块用于处理空间和时间信息传递。最后再借助等变池化的操作将历史帧的信息进行融合作为模型的输出。实验证明,与传统的时空图神经网络和等变图神经网络相比,ESTAG在三个真实数据集上(分子级别、蛋白质级别、宏观运动级别)表现出更好的效果。
综上所述,本文提出的ESTAG模型充分考虑了物理系统的对称性和非马尔科夫性质,通过利用历史轨迹进行时空预测,为物理动力学建模提供了一种有效的方法。
论文介绍
论文题目:Crystal Structure Prediction by Joint Equivariant Diffusion
论文作者:矫瑞,黄文炳,林沛佳,韩家琦,陈品,卢宇彤,刘洋
通讯作者:黄文炳,刘洋
论文概述:晶体结构预测(CSP),即通过晶体组分预测晶体结构,是材料科学领域中的一个重要问题。晶体结构的对称性——平移、旋转和周期性的不变性,为该任务带来了挑战。为了融入这些对称性,本文提出了基于扩散模型的预测方法DiffCSP,从稳态晶体数据中学习结构分布。具体而言,DiffCSP通过采用周期性E(3)-等变去噪模型,同时生成每个晶体的晶格矩阵和原子的分数坐标,以更好地模拟晶体的几何结构。广泛的实验证实,我们的DiffCSP在性能上明显优于现有的CSP方法,并且与基于DFT的方法相比,计算成本大大降低。此外,我们还将DiffCSP扩展到了晶体的从头生成任务中,其性能同样可以得到保证。
论文介绍
论文题目:SpokenWOZ: A Large-Scale Speech-Text Dataset for Spoken Task-Oriented Dialogue in Multiple Domains (NeurIPS Dataset Track)
论文作者:司书正,马文涛,高浩瑜,武玉川,林廷恩,戴音培,黎航宇,严睿,黄非,李永彬
通讯作者:严睿,李永彬
论文概述:就像ImageNet推动了深度学习的发展,高质量数据集是推动技术前进的重要力量。我们打造了大规模人人口语对话数据集SpokenWoZ。SpokenWOZ 是当前最大规模的音义双模态对话数据集,包含 8 个领域、202K 轮次、5.7K 对话和对应 249 小时的对话音频,带有多样化音频、完全口语化的特征以及细粒度记忆与推理的新挑战。当前微调之后最好的音义双模态模型只能完成 52.1% 的对话任务,而 ChatGPT 由于幻觉和单模态的限制只能完成 13.8% 的任务,说明真实语音对话具有很大挑战。我们希望在大模型时代,能够推动复杂、真实对话能力的发展,能够让对话机器人越来越接近人类的水平。
论文介绍
论文题目:REASONER: An Explainable Recommendation Dataset with Comprehensive Labeling Ground Truths (NeurIPS Dataset Track)
论文作者:陈旭,张景森,王磊,戴全宇,董振华,唐睿明,张瑞,陈黎,赵鑫,文继荣
通讯作者:戴全宇
论文概述:可解释推荐系统在提高推荐说服力、信息量和用户满意度方面表现出了巨大的潜力,引起了工业界和学术界的广泛关注。近年来,虽然提出了许多有前途的可解释推荐模型,但用于评估它们的数据集仍然受到一些限制。例如,解释真值没有由真实用户标记,解释大多是单一的模态且仅围绕一个方面。为了弥补这些不足,我们基于视频推荐场景构建了一个新的可解释推荐数据集,提供了大量真实用户标记的多模态、多方面的解释真值。我们详细介绍了数据集的构建过程,并对其特征进行了广泛的分析。此外,我们还开发了一个可解释推荐算法工具包,实现了十余个知名的推荐算法。基于工具包,我们为不同的可解释推荐任务构建了基准。最后,我们展示了该数据集带来的新机会,这些机会有望促进可解释推荐领域的发展。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox