学院新闻
我院师生论文被CCF A类会议SIGKDD 2023录用
日期:2023-05-25访问量:5月16日,中国计算机学会(CCF)推荐的A类国际学术会议SIGKDD 2023论文接收结果公布。中国人民大学高瓴人工智能学院师生有11 篇论文被录用。国际知识发现与数据挖掘大会 (ACM SIGKDD Conference on Knowledge Discovery and Data Mining,简称KDD) 是数据挖掘领域的顶级会议,也是中国人民大学A+类学术会议。KDD 2023 的Research Track录用率为22.10%。

论文介绍
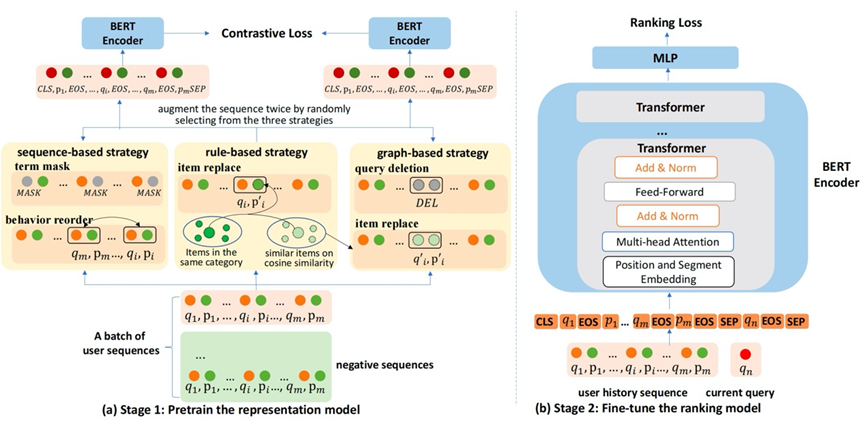
论文题目:Contrastive Learning for User Sequence Representation in Personalized Product Search (Research Track)
作者:戴诗桐,刘炯楠,窦志成,Haonan Wang, Lin Liu, 文继荣
通讯作者:窦志成
论文概述:个性化产品搜索在工业和研究界都吸引了越来越多的关注。现有的个性化产品搜索方法大多是从历史搜索日志中对用户的个人搜索兴趣进行建模,从而生成个性化的搜索结果。然而,在实际应用场景下,用户的历史搜索记录可能是稀疏的或有噪音的,这使得现有的方法难以在个性化搜索中实现准确和具有鲁棒性的用户建模。为了解决这个问题,我们提出了一个基于对比学习的框架CoPPS,从而在个性化产品搜索中学习高质量的用户表示。我们设计了三种数据增强的方法,以利用原始的用户历史搜索数据构建自我监督信号;在预训练阶段通过三个不同层次的对比学习任务来优化编码器,从而更好地表示拥护序列。这些对比学习任务充分利用了知识图谱(KG)、搜索序列之间与搜索序列内部的相关性,并为用户建模提供了更有效的表示,进一步提高了个性化搜索的结果。在Amazon数据集上的实验结果表明,我们的模型能够产生更好的用户表征,从而提升产品搜索的质量。
论文介绍
论文题目:Improving Search Clarification with Structured Information Extracted from Search Results (Research Track)
作者:赵梓良,窦志成,郭宇,曹朝,程小华
通讯作者:窦志成
论文概述:对话式搜索系统中的搜索澄清通常显示由几个候选方面项和一个澄清问题组成的澄清窗格。为了提供一个好的窗格,现有的研究通常单独依赖于非结构化的检索文档文本或结构化的知识库。然而,搜索结果中包含的重要结构化信息没有得到有效的考虑,在某些情况下导致生成的候选项和问题不准确。在本文中,我们强调了利用搜索结果中的结构化信息对改进现有搜索澄清方法的重要性。我们提出用两种结构化信息增强非结构化检索文档:一种是从HTML列表结构中获得的“In-List”关系,它有助于提取具有丰富并行信息的高质量候选项组;另一种是从知识库中提取的“Is-A”关系,有助于生成带有明确提示的高质量问题。为了避免引入过多的噪声,我们设计了一个关系选择过程来明确地过滤掉无效信息。我们进一步用双粒度可见矩阵修改BART编码器,以对关系增强的文档建模,并使用BART解码器生成一个问题或几个候选项。在MIMICS数据集上的实验结果表明,作为纯文本的良好补充,结构化信息分别有助于提高生成的候选项和澄清问题的质量。
论文介绍
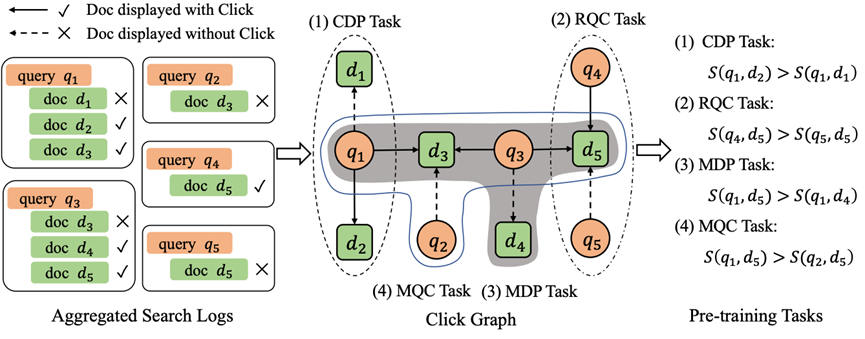
论文题目:PSLOG: Pretraining with Search Logs for Document Ranking (Research Track)
作者:苏展,窦志成,周雨佳,赵子元,文继荣
通讯作者:窦志成
论文概述:最近,预训练模型不仅在自然语言处理方面而且在信息检索 (IR) 方面都取得了显著的效果。先前的研究表明,面向 IR 的预训练任务可以比仅在 IR 数据集中微调预训练语言模型获得更好的性能。此外,从主流搜索引擎获得的海量搜索日志数据可以用于IR预训练,因为它包含了用户在具体查询下对文档相关性的隐式判断。然而,现有方法主要使用直接的会话内查询文档点击信号来预训练模型,来自搜索日志的潜在监督信号远未得到充分探索。在本文中,我们提出综合利用四种查询-文档的相关关系,包括跨会话和多跳关系,来训练针对信息检索的预训练排序模型。具体来说,我们关注用户的点击行为,并构建一个点击图来表示所有搜索会话中查询和文档之间的全局相关关系。使用点击图,我们不仅可以获取查询和文档的直接相关关系,还可以通过其邻居节点考虑跨会话和多跳的查询-文档关系。基于从点击图中提取的关系,我们提出了四种策略来生成正负例的训练样本,并使用这些数据来预训练排序模型。在商业数据集和公开的学术数据集的实验结果证明了我们方法的有效性。
论文介绍
论文题目:Improving Conversational Recommendation Systems via Counterfactual Data Simulation (Research Track)
作者:王晓磊,周昆,汤昕宇,赵鑫,潘凡,曹朝,文继荣
通讯作者:赵鑫
论文概述:对话推荐系统(CRS)旨在通过自然语言对话满足用户个性化偏好。现有方法通常依赖于足够的训练数据来进行模型优化,由于很难对面向推荐的对话数据集进行标注,这些方法常常因训练数据稀缺而存在训练不足的问题。为了解决这个问题,在本文中,我们提出了一种反事实数据仿真方法CFCRS。我们的方法是基于反事实数据增强的框架开发的,该框架逐渐重写真实对话数据中的用户偏好中,而不会干扰整个对话流程。具体而言,我们通过对话中的实体来表示用户偏好并组织对话流,并设计了基于对话流语言模型的多阶段推荐对话模拟器。在用户偏好和对话模式的指导下,对话流语言模型可以产生合理和连贯的对话流,进而得到完整的对话。基于对话模拟器,我们在表征层面对目标用户交互的实体进行干预,并设计了基于课程学习的对抗训练方法来逐步优化数据增强策略。实验表明,我们的方法可以有效提升多个 CRS 模型的性能,并且优于其他数据增强方法,尤其是在训练数据非常有限的情况。
论文介绍
论文题目:Optimal Dynamic Subset Sampling: Theory and Applications (Research Track)
作者:易璐,王涵之,魏哲巍
通讯作者:魏哲巍
论文概述:这篇论文我们研究了独立事件采样的一类基本问题,名为“子集采样”。具体而言,考虑一个由n个不同事件S={x_1, …, x_n}组成的集合,其中每个事件x_i都有一个相关概率p_i。子集采样问题旨在采样一个S的子集,使得每个x_i以概率p_i独立地被包含在S中。一个朴素的解决方案是为每个事件抛一次硬币,这需要O(n)的采样时间。但我们希望算法的采样时间与预期输出大小(即元素概率之和)同阶,而元素概率之和在许多应用中可能明显小于n。许多任务中需要频繁地子集采样,并且子集采样相关问题已经被研究超过十年。目前大部分子集采样的工作都基于静态假设,即事件个数和事件的概率都不会改变。这些工作要么需要较长的采样时间要么需要较长的更新时间,所以实际应用中亟需一个能满足动态更新要求的子集采样算法。这篇论文我们提出第一个最优子集采样算法,采样时间和更新时间都达到了理论最优的复杂度。理论分析和实验结果都证明了我们的算法的优越性。
论文介绍
论文题目:MGNN: Graph Neural Networks Inspired by Distance Geometry Problem (Research Track)
作者:崔冠宇, 魏哲巍
通讯作者:魏哲巍
论文概述:图神经网络(GNN)是机器学习领域的研究热点。现有的 GNN 模型主要分为两类:谱域 GNN 和空域 GNN。谱域模型通过设计多项式图滤波器来建模,而空域模型则采用消息传递机制。为了增强谱域模型的表达能力和通用性,可以设计具有更好逼近能力的基。对于空域模型,尽管有模型试图将其与几何概念和物理对象联系起来,但是目前仍然缺乏从这两个角度分析其通用性的研究。本文从图神经网络分类阶段中的分类器对全等的嵌入矩阵(即两个嵌入矩阵对应向量对之间的距离相等)不敏感的性质受到启发,提出了一种名为 MetricGNN(MGNN)的空域模型。我们指出,如果一个图神经网络模型能够生成与任何给定嵌入矩阵全等的嵌入矩阵,那么它就具备空域通用性,而这与距离几何问题(DGP)密切相关。为了解决 DGP 这个 NP-Hard 问题,我们提出了基于弹簧网络(Spring Network)和多维标度(Multi-Dimensional Scaling)问题的能量函数优化方法,使得我们的模型能够处理同配和异配图。最后,我们采用迭代方法优化能量函数,并在合成和真实数据集上进行了实验,评估了我们模型的有效性。
论文介绍
论文题目:Clenshaw Graph Neural Networks (Research Track)
作者:郭雨荷,魏哲巍
通讯作者:魏哲巍
论文概述:图卷积网络(GCNs)使用栈式堆叠的消息传递模块,是图表示学习中基础的空域方法,而在异配图上具有优势的多项式滤波器则来自与图卷积不同的谱域角度。本文中,我们引入ClenshawGCN,它通过一个简单的残差模块(包括二阶负残差与初始残差),将谱域模型的特性注入到空间模型中。我们证明了ClenshawGCN能模拟任意Chebyshev基下的任意多项式滤波器。实验表明,这样一个融合空域、谱域二者特性的模型能够结合双方的优势。
论文介绍
论文题目:Delving into Global Dialogue Structures: Structure Planning Augmented Response Selection for Multi-turn Conversations (Research Track)
作者:付廷琛*,赵学亮*,严睿
通讯作者:严睿
论文概述:目前,基于大规模预训练的语言模型的迅速发展,开放领域对话模型可以根据历史背景选择符合语境的回复。然而,它们通常将对话历史直接连接起来,作为模型的输入,这种扁平化的处理方式,忽略了不同对话轮次之间的关联关系。在这项工作中,我们提出了动态对话模型,在该模型中,我们引入了一种动态流机制来对文本流进行建模,并用来捕获跨语言话语的信息动态,发现语料集之中的特征对话结构知识。
论文介绍
论文题目:Hierarchical Invariant Learning for Domain Generalization Recommendation (Research Track)
作者:张泽宇,高赫阳,杨镐,陈旭
通讯作者:陈旭
论文概述:大多数跨域推荐需要目标域信息或者源域与目标域的重叠信息来进行域适应。然而在现实世界中,目标域可能缺乏这些信息。本文将该问题定义为域泛化问题,并提出了相应的模型。此外,我们阐述了它与零样本推荐、预训练推荐和冷启动推荐之间的关系,并区分于基于内容的推荐。我们提出了HIRL+模型来解决这一问题。我们提出了层次不变学习的方法,以排除域层级和环境层级的特定模式,并在泛化空间中找到通用模式。为了使环境层级更为灵活、精细和平衡,我们提出了一个可学习的环境分配方法。为了提高模型对域泛化分布偏移的鲁棒性,我们设计了一种对抗式的环境调整方法。此外,我们还在真实世界的数据集上进行了实验,验证了模型的有效性,并对域间距和域多样性进行了进一步的研究。
论文介绍
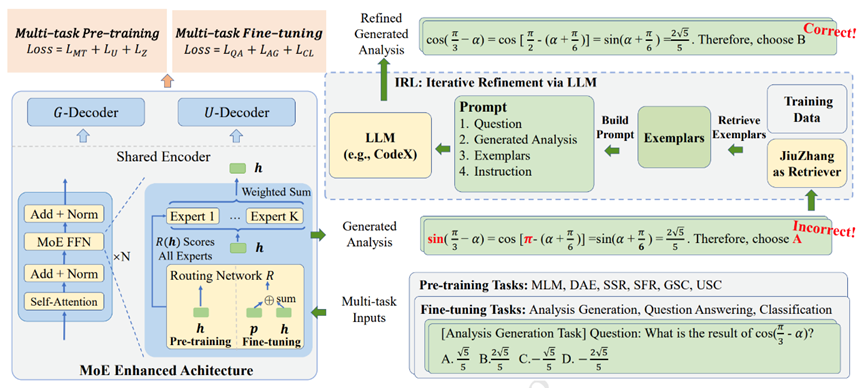
论文题目:JiuZhang 2.0: A Unified Chinese Pre-trained Language Model for Multi-task Mathematical Problem Solving (Applied Data Science Track)
作者:赵鑫,周昆,张北辰,龚政,陈志朋,周远航,文继荣,沙晶,王士进,刘聪,胡国平
通讯作者:赵鑫
论文概述:自动解决数学问题是一种人们一直所期望的机器智能能力。虽然预训练语言模型(PLMs)最近在数学推理方面取得了许多研究进展,但它们并没有被专门设计成一个多任务的求解器,因此在实际应用中面临着高昂的多任务部署成本(例如需要为每个任务部署一个模型)以及在复杂数学问题上表现不佳的问题。基于上述问题,本文提出了JiuZhang 2.0,一种专门用于解决多种数学相关任务的统一中文预训练语言模型。我们的想法是保持一个参数量适中的模型,并利用跨任务的知识共享模块来提高多任务设置下的模型容量。具体来讲,我们构建了一个混合专家(MoE)架构来建模数学文本,以捕捉不同任务之间的共同数学知识。为了训练MoE架构,本文设计了多任务持续预训练和多任务微调策略来让模型适应多任务设置。这些训练策略能够有效地分解不同任务数据中的知识,并通过专家网络建立跨任务知识共享。为了进一步提高模型解决不同复杂任务的通用能力,我们利用大型语言模型(LLMs)作为补充模型,通过上下文学习迭代改进我们的PLM生成的解决方案。在八个任务上的离线评估和在线A/B测试中都证明了我们模型在数学问题解决方面的有效性。
论文介绍
论文题目:Controllable Multi-Objective Re-ranking with Policy Hypernetworks (Applied Data Science Track)
作者:陈思睿*,王原*,温子敬,李志宇,张昌硕,张骁,林泉,朱成,徐君
通讯作者:王原,张骁
论文概述:机器学习模型在在线部署阶段常面临着目标需求变化的问题,如何在无需重训练的前提下在线的调整机器学习模型参数,以保证模型面对变化环境的可控性已成为当前机器学习理论研究与实际应用的关键问题之一。本文以电商中的重排问题为应用场景,关注排序物品列表的用户偏好、多样性、新颖性等多个目标的需求变化,探究在线模型的可控性问题。现有重排方法通常采用静态模型,在离线训练阶段确定目标偏好权重并在在线部署期间保持不变,当需要修改偏好权重时,须重新训练模型,这无法保证模型的实时可控性。同时,最合适的目标偏好权重可能因用户群体或时间变化(例如:节日促销期间)而大相径庭。本文提出了一种名为可控多目标重排(CMR)的框架,它结合了一个超网络,可根据不同的偏好权重在线的生成重排模型的参数。通过这种方式,CMR能够根据在线环境的目标需求变化动态的调整偏好权重,而无需重新训练模型。此外,CMR集成了基于Actor-Evaluator框架的训练—验证框架,Evaluator为CMR提供了可靠的实际测试平台。基于淘宝App实际数据进行的离线实验表明,CMR通过将其作为底层模型改进了几种流行的重排模型,使其获得了实时控制能力;在线A/B测试验证了CMR的有效性和灵活性。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox