学院新闻
我院师生论文被CCF A类会议SIGIR 2023录用
日期:2023-04-13访问量:4月5日,中国计算机学会(CCF)推荐的A类国际学术会议SIGIR 2023论文接收结果公布。中国人民大学高瓴人工智能学院师生有9篇论文被录用。第46届国际计算机学会信息检索大会会议(ACM SIGIR Conference on Research and Development in Information Retrieval,简称SIGIR )是由ACM举办的信息检索领域的顶级会议,在世界范围内每年召开一次,2023年录用率为20.1%。

论文介绍
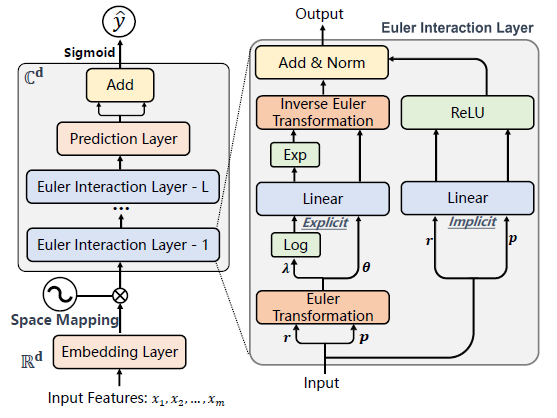
论文题目:EulerNet: Adaptive Feature Interaction Learning via Euler's Formula for CTR Prediction
作者:田震,白婷,赵鑫,文继荣,曹朝
通讯作者:白婷,赵鑫
论文概述:在CTR预测任务中,学习有效的高阶特征交互非常关键。然而,在线电子商务平台中计算具有大量特征的高阶特征交互非常耗时。大多数现有的方法遵循手动设计预定义的最大阶数,并从中进一步过滤掉无用特征交互这一范式。尽管它们降低了由高阶特征组合的指数增长引起的高计算成本,但由于受限特征交互阶数的不充分学习,它们的表现依然受限。保持模型能力并同时保持其计算效率是一个尚未得到充分解决的技术挑战。为了解决这个问题,我们提出了一个自适应特征交互学习模型-EulerNet,其通过欧拉公式进行空间映射,在复数向量空间中学习特征交互。EulerNet将特征交互的幂运算转换为复数特征的模长和相位间的简单线性组合,从而实现了以一种高效的方式自适应地学习任意阶特征交互。此外,EulerNet将隐式和显式特征交互集成到一个统一的体系结构中,实现了它们的相互增强,大大提高了模型的性能。EulerNet可以以数据驱动的方式从数据中自动地学习最优的特征交互,而不依赖于预先设计的特征交互形式或阶数。三个公开数据集上的大量实验已经证明了我们方法的有效性和效率。
论文介绍
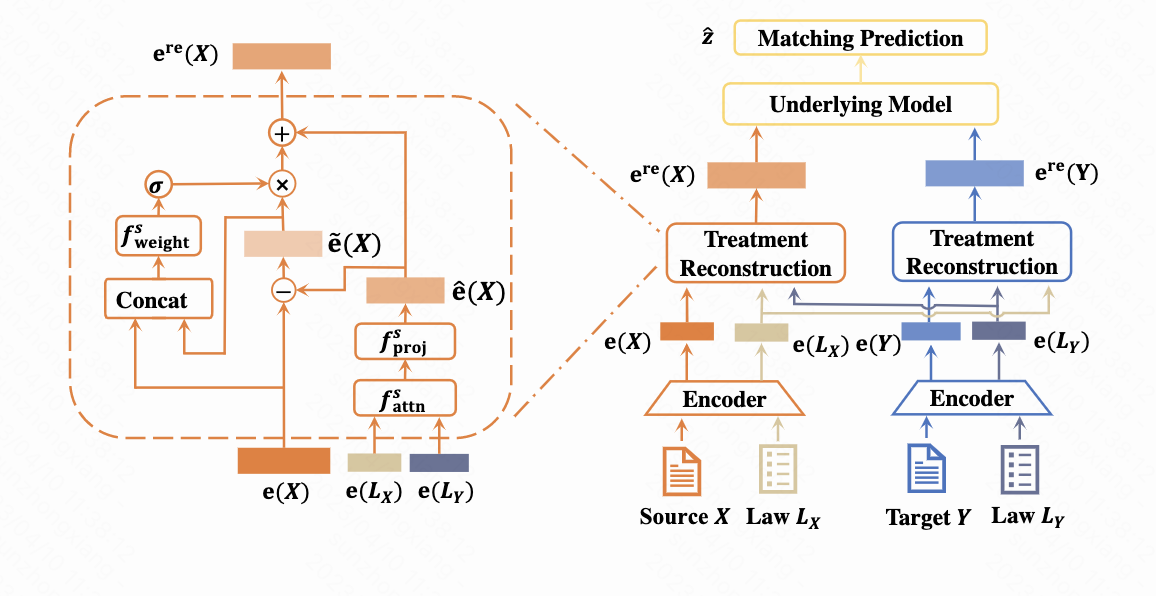
论文题目:Law Article-Enhanced Legal Case Matching: a Causal Learning Approach
作者:孙忠祥,徐君,张骁,董振华,文继荣
通讯作者:徐君
论文概述:司法案件匹配在智能法律系统中发挥了重要作用。语义文本匹配模型已被应用于长文本文件的匹配任务中。这些通用的匹配模型仅仅基于法律案件进行预测,而忽略了法律条文在法律案件匹配中的重要作用。在现实世界中,因为法律案件的内容和判决是在法律条文的基础上形成的,匹配结果(如相关性标签)会受到法律条文的极大影响。从因果关系的角度来看,匹配结果会受到法律案例中引用的法律条文的中介作用,以及法律案例中的关键情节(如详细的事实描述)的直接影响。 根据这一观察,本文提出了一个名为Law-Match的模型无关的因果学习框架,在该框架下,法律案件的匹配模型是通过依据相应的法律条文来学习的。给定一对法律案件和相关的法律条文,Law-Match将法律条文的视为工具变量(IVs),将法律案件视为 treatments。利用IV回归,处理方法可以分解为与法律相关和与法律无关的部分,分别反映出中介和直接效应。然后,这两部分以不同的权重结合起来,共同支持最终的匹配预测。我们表明,该框架与模型无关,一些法律案件的匹配模型可以作为基础模型应用。综合实验表明,Law-Match在三个公共数据集上的表现超过了最先进的基线。
论文介绍
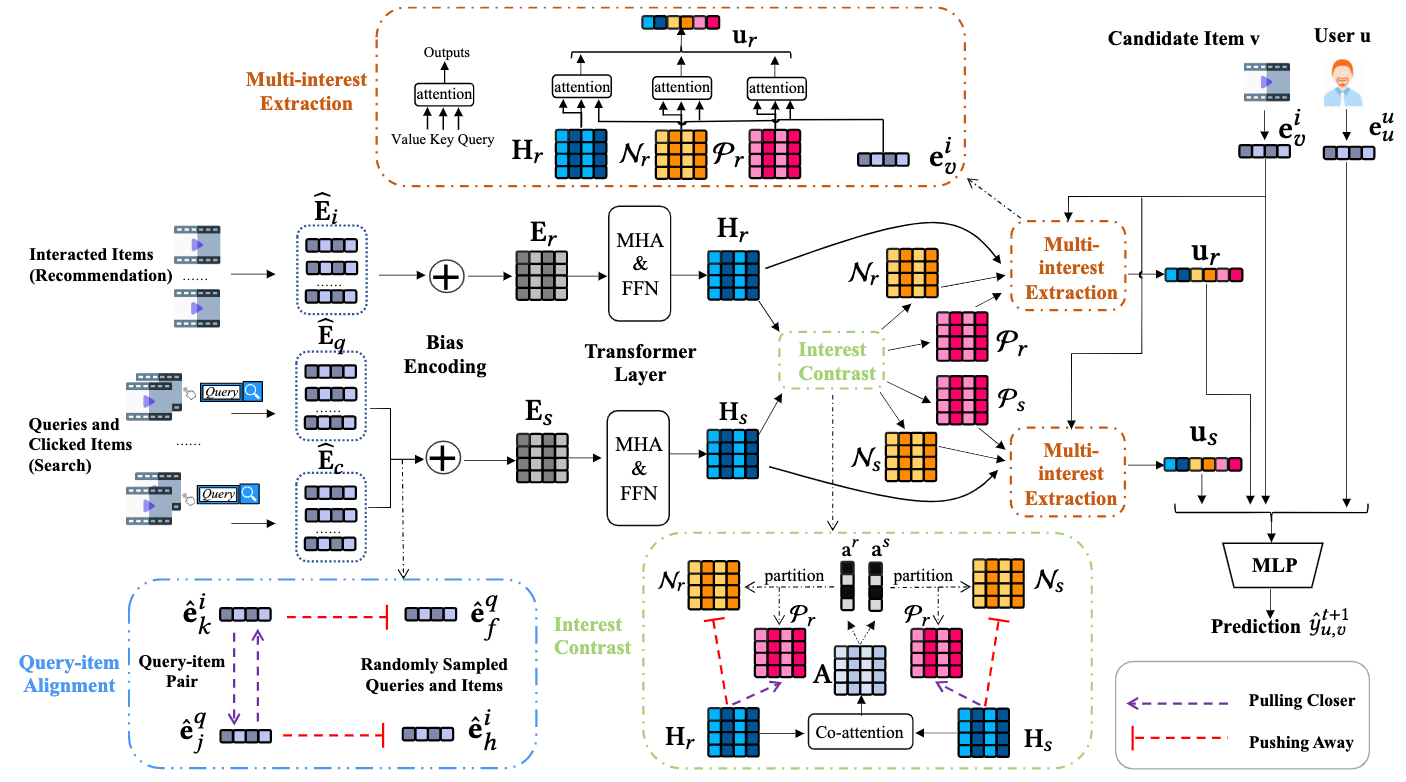
论文题目:When Search Meets Recommendation: Learning Disentangled Search Representation for Recommendation
作者:思子华,孙忠祥,张骁,徐君,臧晓雪,宋洋,盖坤,文继荣
通讯作者:张骁,徐君
论文概述:现代互联网在线服务提供商,比如在线购物平台,往往会同时提供搜索和推荐服务来满足不同的用户需求。目前少有方法探究如何将用户使用搜索和推荐服务的历史融合起来。大部分现存工作要么简单地将搜索和推荐的行为分别处理,或者联合地通过将它们融合进行优化,这些做法都忽略了一个重要的事实,即搜索和推荐行为中蕴含的用户意图可能会显著不同。在这篇文章中,我们提出了一个搜索数据强化的框架(叫做SESRec)用来做序列推荐,该框架利用了用户的搜索兴趣来辅助推荐任务,方式为解构搜索和推荐行为中的相似与不相似的表征。更具体地说,SESRec首先将搜索文本和物品的向量进行了“对齐”(align),这是基于计算用户搜索行为间相似度进行的。两个transformer解码器被用来分别学习搜索和推荐行为独立的表征。接着,一个对比学习任务被设计来监督搜索和推荐行为之间相似与不相似表征的学习。最终,我们通过一个有三个不同角度的注意力机制来抽取用户兴趣。在工业数据集和公开数据集上的大量实验验证了SESRec能够一致地超过当前最优的基线模型。分析实验进一步验证了SESRec能够成功地解构用户搜索和推荐中的相似与不相似的兴趣。
论文介绍
论文题目:Session Search with Pre-trained Graph Classification Model
作者:马晟杰,陈冲,毛佳昕,田奇,江旭晖
通讯作者:毛佳昕,田奇
论文概述:随着用户越来越多地依赖搜索引擎来获取所需信息,搜索任务往往变得更加多样化和复杂化。许多情况下,单个查询无法满足用户的信息需求,导致他们提交更多的查询,直到他们满意或停止搜索,这个过程被称为会话搜索(session search)。常规的方法通常是将搜索会话建模为扁平的文本序列,但这样会忽略查询、文档和数据中存在的相关实体和主题之间的复杂语义拓扑关系。从从细粒度的角度观察,会话中的不同数据类型具有的不同特征属性可能会对用户行为产生不同程度的影响。因此本文设计了一种使用名为SessionGraph(SG)的异质图表示方法来表示会话检索信息,并通过基于异质图池化的GNN模型编码SG的图分类模型,得到候选文档相关性得分。为强化GNN的表征能力,本文还为模型设计了一种预训练策略,通过最大化SG中不同类型的局部节点嵌入与相应类型的全局嵌入之间的互信息MI。我们通过在公开数据集上的实验,验证了本工作的有效性。
论文介绍
论文题目:M2EU: Meta Learning for Cold-start Recommendation via Enhancing User Preference Estimation
作者:吴振超,周骁*
通讯作者:周骁
论文概述:推荐系统向具有少量交互信息的用户或项目提供推荐时,常会遇到冷启动问题。为了解决冷启动问题,基于元学习的方法在近年来发挥了较好的作用。 在元学习框架下,先在预训练阶段使模型学习全体用户偏好,然后利用少量交互信息微调模型局部参数以适用于目标用户。然而,我们认为,在冷启动场景下仅利依赖用户自身交互信息可能不足以很好地捕捉用户偏好。为了解决这个问题,我们提出了一种新的元学习方法。该方法先基于固有属性和交互信息来识别相似用户,再嵌入这些相似用户信息来丰富当前冷启动用户的表示。其中,相似用户信息的聚合是通过一种基于评分方差的注意力机制。为了更好地建模用户偏好,我们根据评分设计了不同的神经层来生成用户或项目表示,并利用权重共享策略来避免对某些评分对应的embedding层参数学习不充分的问题。在采用mini-batching策略的元训练中,我们采用增量学习方案为所有任务学习一组泛化参数。在公共基准数据集上的实验结果表明,M2EU在各种冷启动场景和非冷启动场景中都优于其它先进方法。

论文介绍
论文题目:Distributionally Robust Sequential Recommendation
作者:周睿,吴贤,邱昭鹏,郑冶枫,陈旭
通讯作者:陈旭
论文概述:近年来,对用户序列行为进行建模的方法已被证明在提高推荐性能方面效果显著。然而,以往的研究大多数都假设训练和测试数据集的分布是一致的,这可能与现实中用户兴趣偏好的多样性和复杂性相矛盾,从而限制了模型在真实场景下的推荐性能。为了缓解这一问题,本文提出了一种鲁棒的序列推荐框架,以克服训练和测试集之间潜在的分布差异。具体而言,本文首先通过样本重加权以模拟不同的训练数据分布。然后,最小化这些分布下的最大损失,以此优化“最坏情况”下的损失,从而提高模型的鲁棒性。考虑到上述行为可能会引入太多权重参数而使模型难以优化,本文提出了硬性和软性策略对训练样本进行聚类,并为每个类别赋予权重。最后,本文通过分析上述极小极大目标的泛化误差来从理论角度更好地解释所提出的框架,并基于三个真实数据集进行了大量实验,以证明所提出框架的有效性。
论文介绍
论文题目:Towards a More User-Friendly and Easy-to-Use Benchmark Library for Recommender Systems(Resource Paper)
作者:徐澜玲*,田震*,张高玮,张君杰,王磊,郑博文,李依凡,唐嘉凯,张泽宇,侯宇蓬,潘星宇,赵鑫,陈旭,文继荣
通讯作者:赵鑫,陈旭
论文概述:作为一个拥有从数据处理、模型开发、算法训练到科学评测的一站式全流程托管框架,伯乐从 2020 年 11 月 15 日 正式发布起,开源影响与日俱增,致力于推进推荐系统开源社区的发展。在本文中,我们团队对伯乐进行了重大更新,使其作为一个综合的推荐基准库,更加用户友好和易于使用。我们主要在三个方面进行了扩展,即基准模型/数据集、基准框架和基准配置。此外,我们提供了更全面的使用文档和方便查阅的常见问题解答来提升用户体验。最后,我们系统性地为开源代码库的开发者提供了参考指南。这些更新使得推荐算法更容易被复现,并与推荐系统的最新进展保持同步。可以通过以下链接查看我们此次的更新内容:https://github.com/RUCAIBox/RecBole#update。

论文介绍
论文题目:JDsearch: A Personalized Product Search Dataset with Real Queries and Full Interactions (Resource Paper)
作者:刘炯楠,窦志成,唐国瑜,Sulong Xu,龙波
通讯作者:窦志成
论文概述:近年来,个性化产品搜索的方向的研究备受关注,多种模型被提出。为了评估模型的有效性,以往的研究主要利用在亚马逊推荐数据集上人工构造的数据集进行实验。但是,该数据集中没有真正的用户查询——数据集中的查询是根据产品的类别信息人工生成的伪查询。我们认为,在现实情况下,用户可能会发出更复杂的查询,而不是简单的基于类别的查询。这会导致在该模拟数据集上的实验结果可能与真实场景下的用户满意度不同。此外,亚马逊数据集排除了冷用户和尾部产品,因此无法使用该数据集评测针对这类用户和产品的模型(如few-shot模型)。此外,亚马逊数据集被分为几个子类别,每个子类别数据集中,只保留属于同一个类别的产品。然而,我们认为在不同类别中建模用户的购买模式对于个性化产品搜索方法是至关重要的。由于亚马逊数据集的这些缺点,我们认为有必要发布一个基于真实用户行为的新数据集,以支持未来的个性化产品搜索研究。在本文中,我们发布了一个基于在线购物平台京东的真实用户数据的个性化产品搜索数据集,其中包含大约170,000个用户,12,000,000个产品和26,000,000次交互。在该数据集中我们记录了用户在一年内所有交互过的产品和发出的查询,因此这个数据集可以最大限度地反映真实的用户行为。同时,我们也从各个产品/用户/用户兴趣等角度分析数据集,并评估了有代表性的个性化产品搜索模型的结果,验证该数据集进行实验的可行性。
论文介绍
论文题目:Robust Causal Inference for Recommender System to Overcome Noisy Confounders(短文)
作者:张智恒,戴全宇,陈旭,董振华,唐睿明
论文概述:将因果推断融入推荐系统的方法近年来引起了越来越多的关注。因果语言用于回答假设性问题,例如:当向用户推荐产品时,可能的反馈是什么?目前主流的各种无偏估计方法包括:逆倾向得分(IPS)、双重稳健(DR)等。然而,这些方法严重依赖于混淆变量精确可观测的假设, 这在真实世界的场景中通常不成立。本文提出了一种新颖的对抗训练方法AT-IPS来处理噪声混淆变量。该方法通过对抗性噪声定义混淆变量的可行区域,然后在此区域内联合训练倾向模型和预测模型。本对AT-IPS的准确性和鲁棒性进行了理论分析,并证明了其在半合成和真实数据集上比其他流行的方法表现更好。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox