学院新闻
我院师生论文被国际学术会议ACM CIKM录用
日期:2022-08-08访问量:近日,中国人民大学高瓴人工智能学院师生有13篇论文(11篇长文、1篇资源论文、1篇短文)被国际学术会议ACM CIKM(2022)录用。第31届国际计算机学会信息与知识管理大会(The 31th ACM International Conference on Information and Knowledge Management, CIKM 2022)将于今年10月17日-10月21日在线召开。CIKM是CCF推荐的B类国际学术会议,在信息检索和数据挖掘领域享有较高的学术声誉。

论文介绍
论文题目:Dually Enhanced Propensity Score Estimation in Sequential Recommendation(长文)
作者:徐晨,徐君,陈旭,董振华,文继荣
通讯作者:徐君
论文概述:序列推荐系统基于大量隐式用户反馈数据训练其模型,并且当某些物品系统性地被曝光在用户面前时,用户行为可能会受到这些偏差的影响。本文提出了基于逆倾向性得分(IPS)的无偏学习来解决这个问题。IPS方法的关键是在给定历史信息的情况下准确估计曝光的用户物品对的概率。在这些方法中,倾向得分估计通常仅限于从物品的角度来估计,即将反馈数据视为与用户交互的物品序列。然而,IPS的估计也可以从用户的角度将反馈数据视为与物品交互的用户序列。我们发现,这两种观点可以联合增强顺序推荐中的倾向得分估计。受观察结果的启发,我们建议从用户和物品的两个角度估计倾向得分,称为对偶增强倾向得分估计(Dually Enhanced Propensity Score Estimation,简写为DEPS)。具体而言,给定目标用户物品对以及相应的物品和用户交互序列,DEPS首先构建序列因果图来表示用户物品对的观察概率。根据该图,基于同一组用户反馈数据,分别从物品和用户的角度估计两个互补的倾向性得分。最后,设计两个transformer,利用这两个倾向性得分进行最终的偏好预测。理论分析了DEPS的无偏性和方差。在三个公开的基准和一个专有的工业数据集上的广泛实验结果表明,DEPS可以显著优于最先进的基线。实证分析还表明,DEPS可以用作于任何序列推荐模型的去偏框架,在该框架下,其他序列推荐模型的性能也可以得到进一步提升。
论文介绍
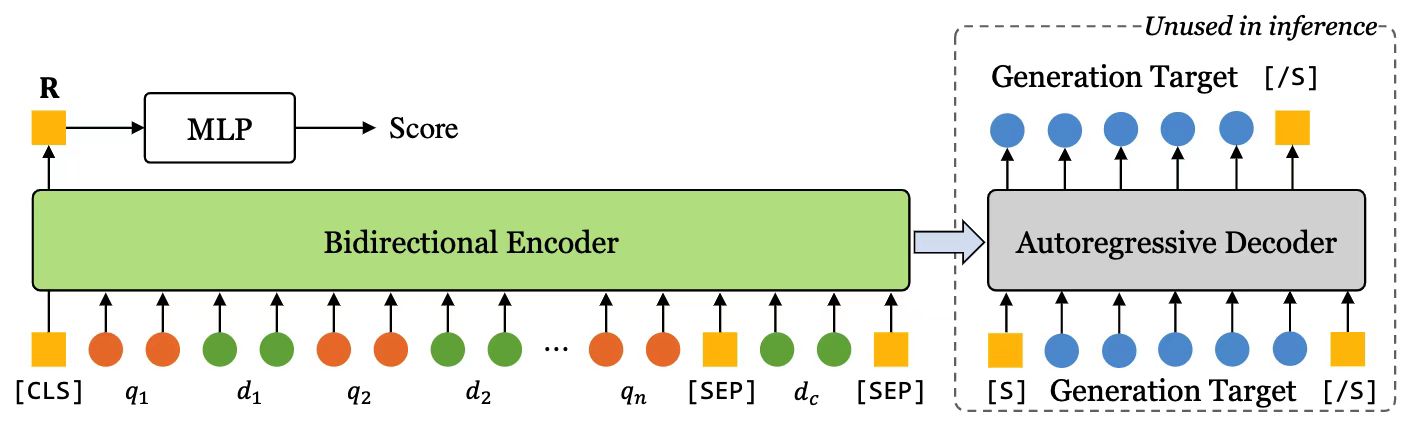
论文题目:Enhancing User Behavior Sequence Modeling by Generative Tasks for Session Search(长文)
作者:陈浩楠,窦志成,朱余韬,曹朝,程小华,文继荣
通讯作者:窦志成
论文概述:用户的搜索任务变得越来越复杂,往往需要提出多个查询语句并与搜索结果多次交互。最近的研究表明,对会话中的历史用户行为进行建模可以帮助理解当前的搜索意图。现有的会话级别搜索排序模型主要对当前会话序列(从第一个行为到当前查询)进行编码,并使用高维表示来计算排序分数。但是,当前会话序列中通常存在一些噪声(对于推断搜索意图无用的行为),可能会影响编码表示的质量。为了帮助编码当前用户行为序列,我们提出使用解码器以及未来序列的信息和补充查询的信息。具体来说,我们设计了三个可以帮助编码器推断实际搜索意图的生成任务:(1)预测未来的查询语句,(2)预测未来的点击文档,以及(3)预测补充查询语句。我们使用编码器-解码器结构的方法,使用多任务学习的方式学习这些生成任务以及排序任务。在两个公共搜索日志上的大量实验表明,我们的模型优于所有现有的基线模型,并且设计的生成任务实际上可以帮助排序任务。此外,额外的实验还表明,我们的方法可以很容易地应用于各种基于 Transformer 的编码器-解码器模型并提高它们的性能。
论文介绍
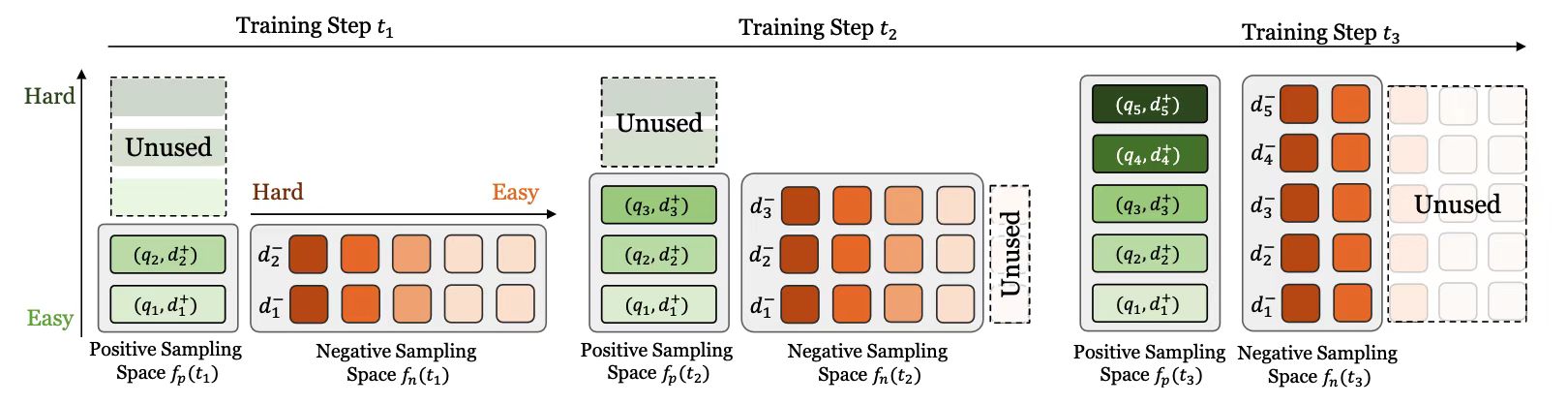
论文题目:From Easy to Hard: A Dual Curriculum Learning Framework for Context-Aware Document Ranking(长文)
作者:朱余韬,聂建云,苏熠暄,陈浩楠,张鑫宇,窦志成
通讯作者:窦志成
论文概述:在会话搜索中,上下文信息对于捕获用户的查询意图是非常重要的。现有的工作已经尝试了各种方法对用户的查询行为序列进行建模,从而提高文档排序的效果。在这些模型的训练过程中,样本(即“查询上下文-文档“对)通常是按照随机采样的顺序进行学习的。而实际上,理解不同样本的查询意图或判断相应的文档相关性有着不同的难度。简单地将不同难度的样本混合在一起并随机采样的方式显然会对模型的学习产生干扰。在本工作中,我们提出了一种课程学习的框架,其中模型可以按照从易到难的方式学习查询上下文和文档之间的匹配关系。具体来说,我们针对正负样本分别设计了一个课程来控制其学习难度。对于正样本,模型在早期训练时只能使用简单样本进行学习,而随着训练的进行,更难的样本也加入学习之中;对于负样本,我们则在早期允许所有样本参与学习,并在之后逐渐将简单样本丢弃。在两个真实的查询日志数据集上,我们的框架能够显著提高多种已有模型。这一结果验证了课程学习对于上下文感知的文档排序任务的有效性。
论文介绍
论文题目:A Relevant and Diverse Retrieval-enhanced Data Augmentation Framework for Sequential Recommendation(长文)
作者:卞书青,赵鑫,王锦鹏,文继荣
通讯作者:赵鑫
论文概述:在线平台中,学习序列用户行为语义信息对于准确预测用户兴趣至关重要。近年来,基于深度学习的序列推荐方法已广泛提出。然而,现实中由于数据的稀疏性,尤其是在冷启动场景中,现有的神经序列推荐模型在实践中可能表现不佳。为了解决这个问题,我们提出了模型 ReDA(Retrieval-enhanced Data Augmentation),基于检索增强的数据增强建模顺序用户行为。我们方法的主要思想是利用来自相似用户的相关信息来生成语义相关和多样化的序列表示。首先,我们训练一个基于神经网络检索器根据用户表示之间的语义相似性来检索增广用户,然后进行两类基于表示层的数据增强以生成增强的用户表示。此外,这些得到的增强数据被纳入到对比学习框架中。在公开和行业数据集上进行的大量实验证明了我们提出的方法优于现有的基线方法。
论文介绍
论文题目:Temporal Contrastive Pre-Training for Sequential Recommendation(长文)
作者:田长鑫,林子涵,卞书青,王锦鹏,赵鑫
通讯作者:赵鑫
论文概述:最近,基于预训练的推荐算法提出利用自监督信号来提高顺序推荐的性能。然而,大多数现有的预训练推荐系统只是简单地将用户的历史行为建模为一个序列,而没有充分考虑用户行为的时间模式。为了更好地建模用户行为的时间特征,我们针对序列推荐提出了对比的时间预训练方法(简称TCPSRec)。根据交互的时间信息,我们考虑将交互序列划分为更连贯的子序列,并基于此设计预训练目标。具体而言,TCPSRec对用户行为的不变性和周期性进行了建模。对于不变性,我们考虑序列内的全局不变性和序列内的局部不变性,分别捕捉长期偏好和短期意图。对于周期性TCPSRec在行为子序列级别对粗粒度周期和细粒度周期进行了建模。为此,我们设计了四个预训练目标,以有效地融合时间信息与项目表示。我们在美团真实数据集和五个公共数据集上的实验证明了我们预训练方法的有效性。
论文介绍
论文题目:Multimodal Meta-Learning for Cold-Start Sequential Recommendation(长文)
作者:潘星宇,陈昱硕,田长鑫,林子涵,王锦鹏,胡鹤,赵鑫
通讯作者:赵鑫,胡鹤
论文概述:在现实的推荐场景中,每天都有大量的新用户涌入,如何基于新用户极短的交互历史数据进行推荐是一个值得研究的问题,本文主要研究了在序列化推荐场景下用户冷启动的问题。我们将冷启动用户的推荐任务视为一个小样本学习任务,并引入元学习的思想,从已有的老用户数据中进行知识迁移,服务于新用户的推荐。这个知识迁移过程中的主要障碍是新老用户交互序列之间存在的特征差异,为此,我们提出了一种多模态元学习框架(Multimodal Meta-Learning,MML),通过引入电商外卖场景下丰富的多模态信息来缓解交互序列之间的差异,提升序列化推荐模型对冷启动用户的建模能力。我们在美团App首页推荐场景下进行了离线实验和线上AB test来验证模型效果。
论文介绍
论文标题:MGMAE: Molecular Representation Learning by Reconstructing Heterogeneous Graphs with A High Mask Ratio(长文)
作者:冯晋嘉,王桢,李雅亮,丁博麟,魏哲巍,许洪腾
通讯作者:魏哲巍
论文概述:Masked autoencoder(MAE)作为一种在计算机视觉和自然语言处理领域卓有成效的自监督学习模型,最近开始被应用于分子图表征学习。在本文中,我们将MAE应用于基于分子图的预训练Transformer模型中,致力于解决现有分子图预训练工作中忽略的两个问题。(1) 在模型中只有原子被抽象为图节点进行重建重建,化学键在推理过程中不作为图节点进行预测,使得模型无法区分相同原子的不同排列的分子。(2) 高比例的mask已经在计算机视觉领域已被证明是有益的,并且能够完成具有挑战性的重建任务。但由于分子图数据中的信息冗余较少,因此已有工作未能将这一方法在分子图上有效利用。为了解决这些问题,我们提出了一种新的框架,Molecular Graph Mask AutoEncoder(MGMAE)。首先,我们将每个分子图转换为原子-化学键异构图,使得重建任务中包含化学键属性,并设计此类图的单向位置编码。其次,我们提出了一种混合mask机制,以充分利用原子属性和空间特征之间的互补性。同时,我们通过利用图上拓扑邻居之间的相关性使用动态聚合的方式补偿mask embedding。因此,MGMAE可以以高比例mask原子、化学键和原子间的相对距离并让模型在重建任务中学习到分子图的潜在表示。在多个分子图公开数据集上的实验表明,我们的方法在大部分数据集上超越了目前所有的基线模型,展示了MGMAE在分子图性质预测任务中的竞争力。此外,额外的消融实验也证明了我们的方法中不同模块的有效性。
论文介绍
论文题目:Personalized Query Suggestion with Searching Dynamic Flow for Online Recruitment(长文)
作者:周子乐*,周骁*,李明哲,宋洋,张涛,严睿
通讯作者:严睿
论文概述:在这个信息指数增长的时代,使用查询建议技术来帮助用户在在线搜索过程中清楚地表达他们的需求,对搜索引擎来说已经变得越来越重要。一个查询建议系统的成功在于准确地理解和建模每个查询背后的用户搜索意图,这离不开利用动态的用户反馈行为和丰富的上下文信息进行个性化查询建议。然而,这一有价值的领域在很大程度上仍未被当前的查询建议系统所开发。在本研究中,我们提出了动态搜索流模型(DSFM),这是一个查询建议框架,能够利用动态流机制在招聘场景中逐步建模和细化用户搜索意图。这里引入了局部流和全局流的概念,分别用于捕获用户的实时意图和会话的整体影响。通过利用简历和职位要求中包含的丰富语义信息,DSFM实现了查询建议的个性化。此外,在训练过程中引入了加权对比学习,产生更广泛的有针对性的查询样本,并部分减轻暴露偏差。注意机制的采用使得选择最相关的信息构成最终的意向表征成为可能。在不同类别的真实数据集上的大量实验结果证明了我们提出的方法在在线招聘平台查询建议任务中的有效性。
论文介绍
论文题目:Gromov-Wasserstein Multi-modal Alignment and Clustering (长文)
作者:巩凤娇,聂宇舟,许洪腾
通讯作者:许洪腾
论文概述:多模态聚类的目的是以无监督的方式找到不同模态的数据所共享的聚类结构。目前,解决这个问题通常依赖于两个假设。1)多模态数据拥有相同的潜在分布,2)观察到的多模态数据排列对齐,没有任何模态缺失,但在实际中这两个假设很难同时得到保证,从而导致许多聚类方法不可行。在本工作中,我们开发了一种新的多模态聚类方法,它是基于最优传输距离的Gromovization,放宽了对上述两个假设的依赖。具体来说,对于相互对应关系未知的多模态数据,我们的方法是学习其kernel矩阵的Gromov-Wasserstein(GW)barycenter。在模块最大化原则的驱动下,GW barycenter有助于探索不同模态所共有的聚类结构,它与不同模态到不同聚类之间的GW距离有关,最优传输方案有助于实现多模态数据的联合对齐和聚类。实验结果表明,我们的方法在数据(部分)不对齐的情况下优于目前的多模态聚类方法。
论文介绍
论文题目:Sharper Utility Bounds for Differentially Private Models: Smooth and Non-smooth(长文)
作者:康艺霖,刘勇,李健,王伟平
通讯作者:刘勇
论文概述:本文通过引入伯恩斯坦条件,对基于梯度扰动的差分隐私算法的超额风险进行分析,在假设损失函数满足Lipschitz连续性、光滑性和Polyak-Łojasiewicz条件时得到了首个O(p^(0.5)/(nε))的高概率超额总体风险界。此外,如果利用α-HÖlder光滑性(适用于部分非光滑损失函数)对Lipschitz连续性和光滑性进行放松,上述风险界将退化为与O(n^(-α/(1+2α)))同阶。针对这个问题,本文利用归一化方法提出了梯度扰动差分隐私算法的一个变种,m-NGP。利用该算法,当损失函数满足α-HÖlder光滑性和Polyak-Łojasiewicz条件时,差分隐私模型的高概率超额总体风险界达到了O(p^(0.5)/(nε)),与假设放松前的结果相一致。此外,实验结果表明,相较于传统梯度扰动算法,m-NGP对模型性能和收敛速度均有提升。
论文介绍
论文题目:Evaluating Interpolation and Extrapolation Performance of Neural Retrieval Models(长文)
作者:詹靖涛,谢晓晖,毛佳昕,刘奕群,郭嘉丰,张敏,马少平
论文概述:在传统的评价框架下,神经网络排序模型会先进行训练,然后在测试集上进行评测并获取一个平均排序性能(例如NDCG);这个平均分数的高低决定了不同神经网络排序模型的优劣。然而,单独考虑平均性能忽视了模型在面对不同输入时的表现,例如,有的模型擅长“记忆”训练集从而在相似的输入上表现较好,有的模型擅长“抓住本质”并较好地泛化到与训练集不相似的输入上。这两方面的能力无法在单一的平均排序性能中体现。因此,我们提出要分开评测模型在面对与训练集相似和不相似输入时的表现,并把这两种性能称为“内插(interpolation)”和“外推(extrapolation)”。为了在现有数据集上评价这两方面的能力,我们提出了一种简单有效的基于相似度的数据集采样方法,并使用这个采样方法重新回顾了目前流行的神经网络排序模型。实验结果表明:不同模型在内插和外推方面表现差异很大,同时模型的相对优劣顺序在内插和外推上是不同的。因此,分别评测模型的内插和外推性能是非常有必要的。我们的工作为IR的排序研究提供了额外的评测工具,同时所提出的内插和外推概念可以激发更多的相关评价方法和更鲁棒的排序模型。
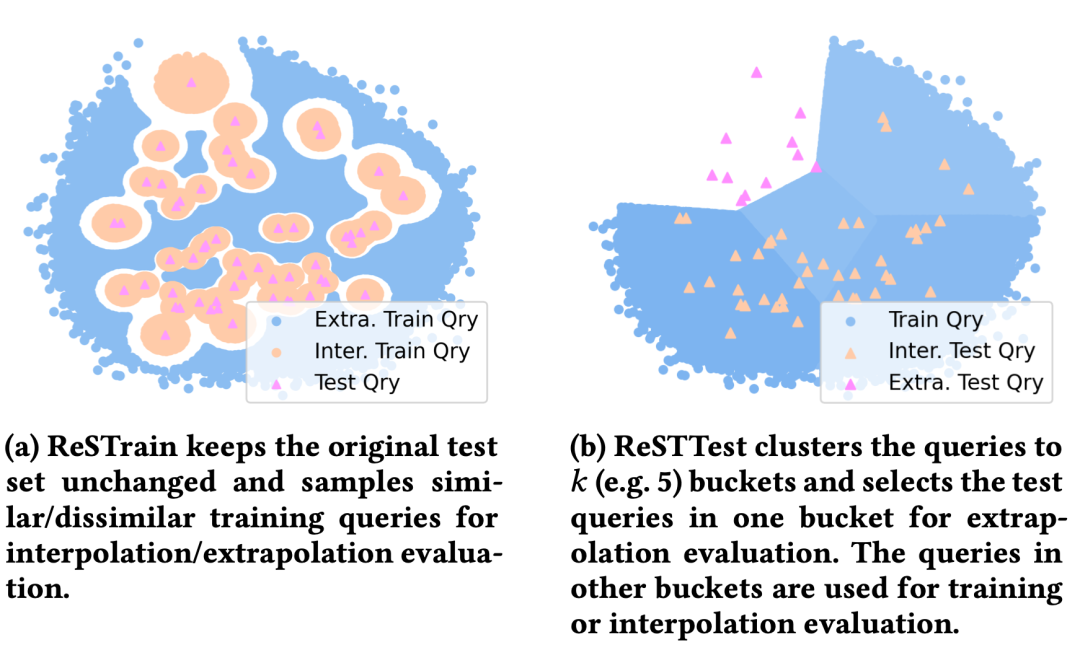
图:两种基于数据集重采样的内插/外推评价方法
论文介绍
论文题目:RecBole 2.0: Towards a More Up-to-Date Recommendation Library(Resource资源论文)
作者:赵鑫,侯宇蓬*,潘星宇*,杨晨,张泽宇,林子涵,张景森,卞书青,唐嘉凯,孙文奇,陈昱硕,徐澜玲,张高玮,田长鑫,牟善磊,范欣妍,陈旭,文继荣
通讯作者:陈旭
论文概述:为了更好地支持推荐系统领域的前沿研究,基于RecBole, 本文提出了一个全新的推荐算法库(RecBole2.0)。它由八个不同主题和架构的子包组成。首先,从数据角度出发,我们考虑了与数据问题相关的三个重要主题(即数据稀疏性、数据偏差和数据分布差异),并相应开发了五个包:元学习、数据增强、去偏、推荐公平性和跨域推荐。其次,从模型的角度出发,我们分别为基于transformer和GNN的模型开发了两个子包。RecBole2.0继承了初代的特点,集数据加载,模型训练,模型评测,超参搜索等功能于一体,极大的便捷了用户的使用,满足研究者的科研需要。目前项目已经在GitHub平台开源(https://github.com/RUCAIBox/RecBole2.0)。
论文介绍
论文题目:GReS: Graphical Cross-domain Recommendation for Supply Chain Platform(短文)
作者:荆智文,赵梓良,冯阳,马晓晨,吴楠,康生巧,张屿佳,杨成,郭浩
论文概述:供应链平台为下游行业提供大量原材料。与传统电子商务平台相比,由于有限的用户兴趣,供应链平台中的数据更加稀疏。为了解决数据稀疏性问题,可以应用跨域推荐,以通过源域提高目标域的推荐性能。然而,将跨域推荐应用于供应链平台直接忽略了供应链平台中商品的层次结构,从而降低了推荐性能。为了利用这一特性,本文以餐饮平台为例,提出了一种基于图的跨域推荐模型GReS。该模型首先构造树形结构的图来表示菜肴和配料的不同节点的层次结构,然后应用我们提出的融合了图卷积网络和预训练语言模型的Tree2vec方法将该图嵌入到向量空间中以进行推荐,该方法能够同时编码商品的结构信息和语义信息。在商业数据集上的实验结果表明,在供应链平台的跨域推荐方面,GReS显著优于其他基线方法。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox