学院新闻
人大高瓴人工智能学院在Nature子刊上发表多模态预训练研究成果
日期:2022-06-02访问量:6月2日,中国人民大学高瓴人工智能学院卢志武教授、孙浩长聘副教授、以及院长文继荣教授作为共同通讯作者在国际综合期刊《自然·通讯》(英文名:Nature Communications,简称Nat Commun)上发表题为“Towards Artificial General Intelligence via a Multimodal Foundation Model”的研究论文,文章第一作者为博士生费楠益。《自然·通讯》是《自然》杂志旗下的子刊之一,主要出版自然科学各领域的高质量研究成果,强调发表新颖、重要、高质量及读者感兴趣的研究。该刊于2010年4月创刊,2021年的影响因子为14.919,5年平均影响因子为15.805。

人工智能的基本目标是模仿人类的核心认知活动比如感知、推理等。虽然许多人工智能算法或模型在各个研究领域都取得了非常大的成功,但是受限于大量标注数据的获取或是没有足够的计算资源支撑在大规模数据上的训练,大多数的人工智能工作还是只局限于单个认知能力的习得。为了克服这些困难,并向通用人工智能迈出坚实的一步,作者以人类大脑处理多模态信息为灵感(如图1a),开发了一个多模态(视觉语言)基础模型,也即预训练模型。此外,为了让模型获得强大的泛化能力,作者提出训练数据中的图片与文本应遵循弱语义相关假设(如图1b),而不是图片区域与单词的精细匹配(强语义相关),因为强语义相关假设将导致模型丢失人们在为图片配文时暗含的复杂情感和思考。通过在爬取自互联网的大规模图文对数据上进行训练,作者得到的多模态基础模型显示出强大的泛化能力和想象能力。作者在多模态预训练模型可解释性上的尝试也说明这些能力很有可能从源头上归因于弱语义相关的数据假设。
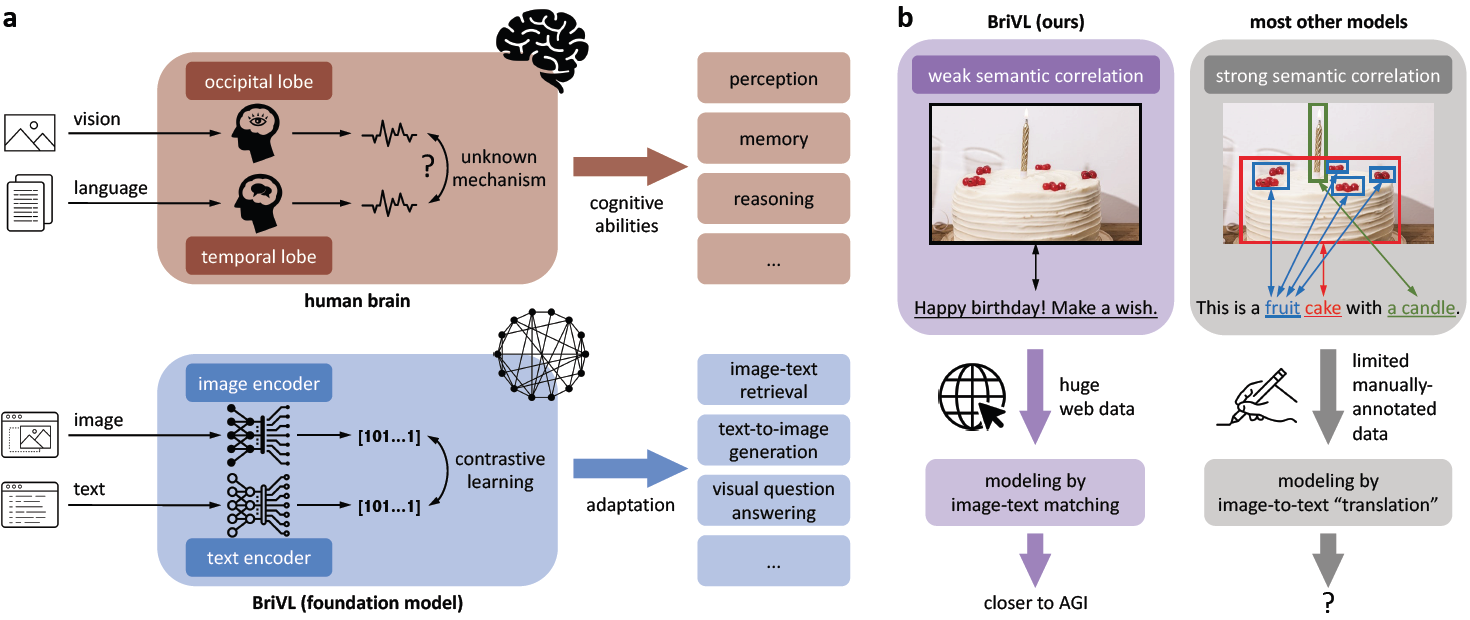
图1:基于弱语义相关假设的BriVL模型。a.我们的BriVL模型和人脑在处理视觉语言信息上的对比。b.建模弱语义相关数据和建模强语义相关数据的对比。
该工作作为文澜项目的重要成果,不仅开发了一个相对资源节约以及方便部署的多模态基础模型,更是在模型可解释性上进行了尝试。通过固定模型参数的神经网络可视化、文生成图等手段,作者直观展示了多模态基础模型的模态对齐空间,即模型对文本的强大想象力(如图2)。在各项下游任务的可视化中,该多模态基础模型甚至展现出一些常识理解的能力。该工作中提出的基于momentum机制的模型设计有望降低研究者对计算资源的需求,模态分离的双塔设计也提高了模型的可扩展性和落地效率。另外,多模态基础模型也会为许多AI+领域提供新的思路,比如利用多模态信息更好地进行诊断,或者辅助神经科学家进行人脑多模态机制的研究。

图2:基于倒转VQGAN的BriVL模型文生成图结果。VQGAN和BriVL在整个过程中均固定不变。
论文信息:
Title: Towards Artificial General Intelligence via a Multimodal Foundation Model
Authors: Nanyi Fei, Zhiwu Lu*, Yizhao Gao, Guoxing Yang, Yuqi Huo, Jingyuan Wen, Haoyu Lu, Ruihua Song, Xin Gao, Tao Xiang, Hao Sun* and Ji-Rong Wen* (* corresponding authors)
作者:费楠益,卢志武*,高一钊,杨国兴,霍宇琦,温静远,卢浩宇,宋睿华,高欣,向滔,孙浩*,文继荣*
论文链接:https://www.nature.com/articles/s41467-022-30761-2
代码链接:https://github.com/neilfei/brivl-nmi
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox