学院新闻
我院师生论文被CCF A类会议SIGKDD录用
日期:2022-05-20访问量:5月19日,中国计算机学会(CCF)推荐的A类国际学术会议SIGKDD 2022论文接收结果公布。中国人民大学高瓴人工智能学院师生有11篇论文被录用。国际知识发现与数据挖掘大会 (ACM SIGKDD Conference on Knowledge Discovery and Data Mining,简称KDD) 是数据挖掘领域的顶级会议,也是中国人民大学A+类学术会议。KDD 2022 的Research Track录用率为14.99%,Applied Data Science Track录用率为25.90%。

论文介绍
论文题目:Instant Graph Neural Networks for Dynamic Graphs (Research Track)
作者:郑艳萍,王涵之,魏哲巍,刘家俊,王思博
通讯作者:魏哲巍
论文概述: 图神经网络(GNN)是一种建模图结构数据的强大技术,已被广泛用于社交推荐、股票预测、分子合成等各种应用。然而,现有的GNN模型主要限于静态图。对于现实生活中普遍存在的动态图,这些静态方法必须在每个图快照中重复计算整个图的表示矩阵。这种策略有两个明显的缺点:1)表示矩阵具有明显延迟,不能反映图中的瞬时变化;2)在每次快照中重复计算整个图的表示矩阵是非常耗时的,严重限制了可扩展性。如何在大规模动态图上实时地计算表示矩阵仍然是一个开放的问题。
在本文中,我们提出了一个实时GNN模型,InstantGNN,该方法增量地计算图表示矩阵,从而避免耗时、重复的计算。因此,InstantGNN能够在不牺牲精度的情况下,实时更新大规模动态图的表示矩阵。此外,我们的方法提出了一个自适应的训练策略,指导模型在它能取得最大性能收益的时候进行重训练。最后,我们在大型真实世界和合成图上进行了广泛的实验,实验结果表明InstantGNN在效率方面优于最先进的基线。
论文介绍
论文题目:Sampling-based estimation of the number of distinct values in distributed environment (Research Track)
作者:李家郡,魏哲巍,丁博麟,戴谢宁,路璐,周靖人
通讯作者:魏哲巍
论文概述: 在数据库和数据挖掘任务中,估计不同元素个数(NDV)是各种应用中的一个基本问题。现有估计NDV的方法大致有利用摘要扫描全表的方法和基于采样的方法。基于扫描的方法有较高的I/O代价和较低的近似误差,基于采样的方法具有较强的可扩展性和较大的误差。在海量数据分布式环境下,基于扫描的方法不实用,但基于采样的方法又会带来令人望而却步的通信成本。本工作结合采样方法和扫描方法的优点,在分布式环境下,传递数据摘要,避免了巨大的通信代价,提出了一种新的基于摘要的分布式NDV估计方法,该方法在一定的假设下实现了基于分布式抽样的NDV估计的亚线性通信代价。我们的方法利用基于摘要的算法来估计分布式流模型中样本频率的频率,这与大多数经典的基于采样的NDV估计器是兼容的。此外,我们还为我们的方法在最坏情况下最小化通信成本的能力提供了理论证据。大量的实验表明,与现有的基于采样和摘要的方法相比,我们的方法节省了大量的通信开销。
论文介绍
论文题目:Graph Neural Networks with Node-wise Architecture (Research Track)
作者:王帧,魏哲巍,李雅亮,邝炜瑞,丁博麟
论文概述:近来,针对图神经网络的神经架构搜索因其能够为给定图数据寻找最优架构而越发流行。然而,正如本文和近期的相关工作所展示的,寻找到的一个最优架构被应用到所有样本(在图数据的语境下即节点)上,很可能不足以应对丰富多样的节点局部模式。因此,我们提议为图神经网络在节点粒度上做神经架构搜索。诚然,简单地将神经架构搜索方法应用到每个节点上是不可行的,因为存在规模问题以及无法为测试节点在该阶段就确定其架构的问题。为了解决上述挑战,我们提出了一个框架,其中一个参数化的控制器会根据每个节点的局部模式,来决定其图神经架构。我们从神经网络的深度、聚合算子、分辨率三个角度设立了控制器,从而实例化提出的框架。然后我们详细地介绍如何同时训练骨干的图神经网络以及各控制器,使得他们能够相互合作。经验性地,我们通过分别展示这三个控制器带来的性能提升,来佐证为每个节点确定神经架构的有效性。进一步地,我们提出的框架在十个真实数据集中的五个上面都显著优于当前最先进的方法。这些数据集的多样性造成此前没有基于图卷积的方法能够同时在这些数据集上一致地展示出性能优势。这一结果进一步说明为每个节点确定神经架构能够提升图神经网络应对多种多样图数据的能力。
论文介绍
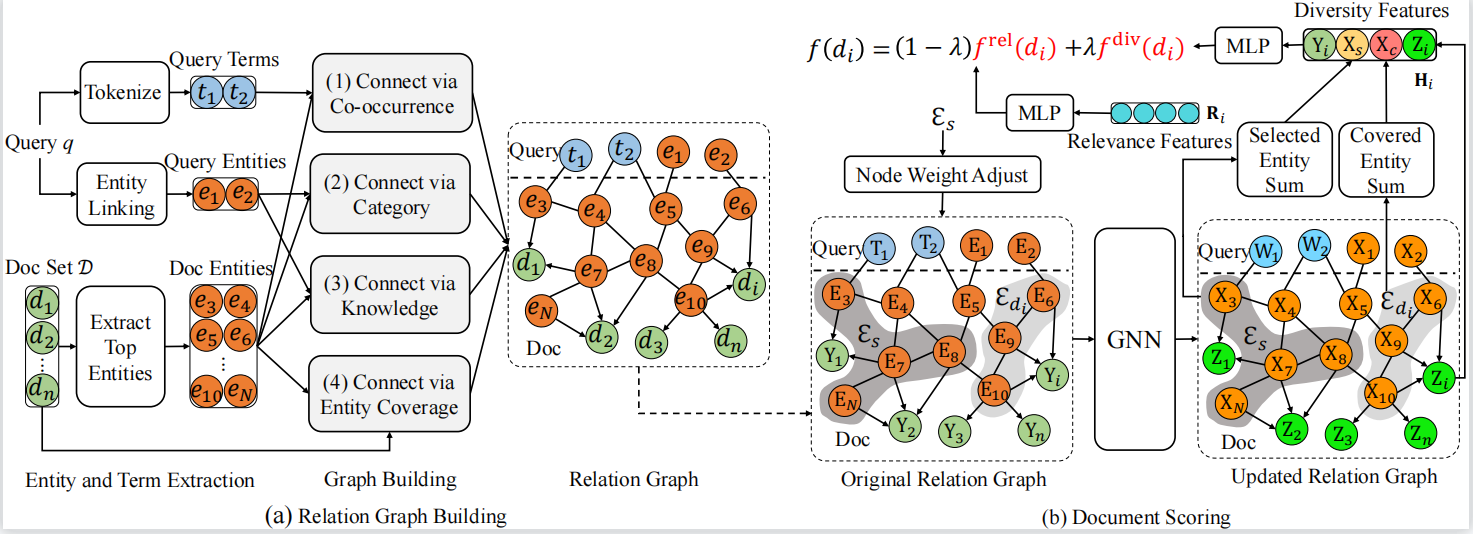
论文题目:Knowledge Enhanced Search Result Diversification (Research Track)
作者:苏展,窦志成,朱余韬,文继荣
通讯作者:窦志成
论文概述: 搜索结果多样化旨在为给定查询提供相关且多样化的文档。大多数现有方法主要基于文本或预先训练的表示来建模文档多样性,然而查询和文档的某些潜在的关系很难由模型仅从内容中捕获。鉴于知识库可以提供良定义的实体和实体之间的显式关系,我们利用知识对文档和查询之间的关系进行建模,并提出一种知识增强的搜索结果多样化方法KEDIV。具体而言,我们构建了一个查询特定的关系图,从实体角度对复杂的查询-文档关系进行建模。然后将图神经网络和节点权重调整算法应用于关系图,在每个选择步骤中可以获得上下文感知的实体表示和文档表示。用于多样化排序的特征由关系图的更新后的节点表示生成。通过这种方式,我们可以利用实体丰富的信息来建模文档在搜索结果多样化方面的多样性。在常用的数据集上的实验结果表明,所提出的方法可以优于现有方法。
论文介绍
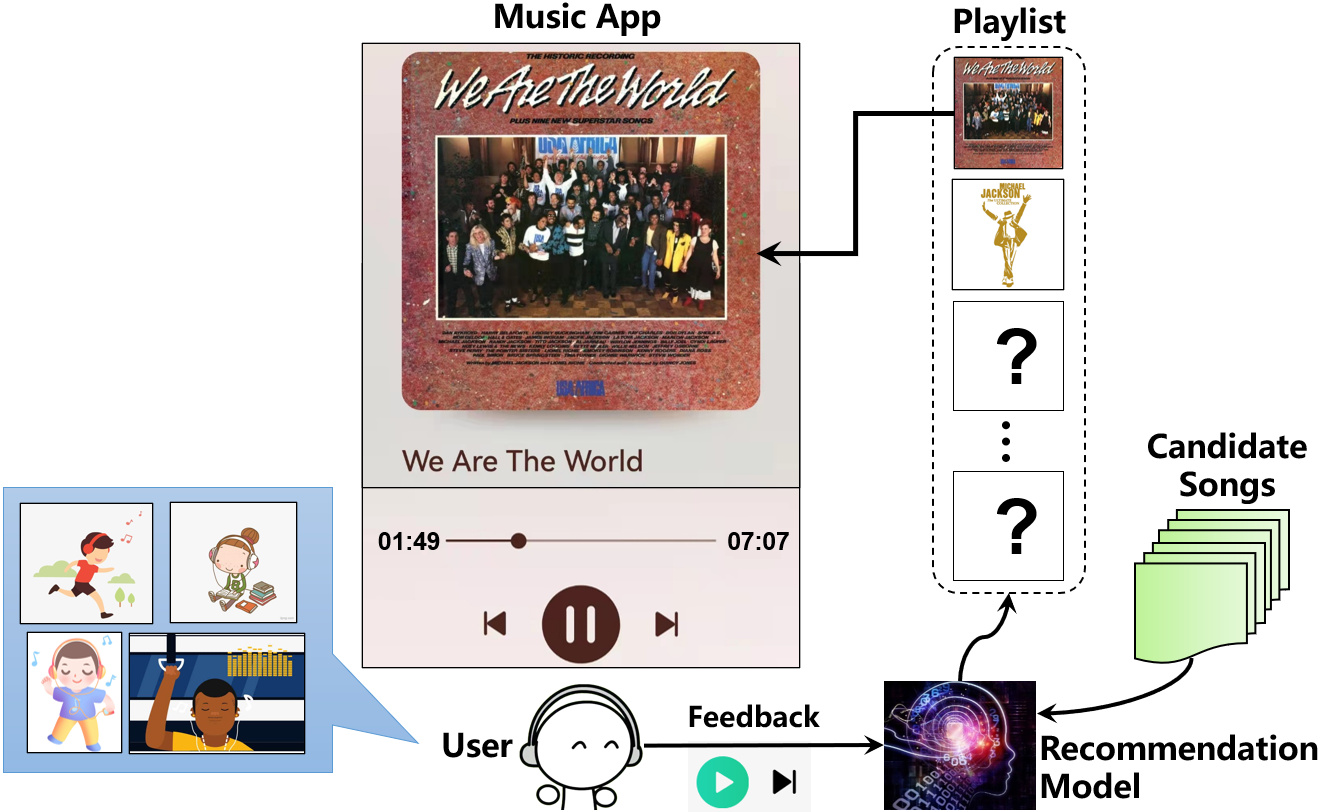
论文题目:Counteracting User Attention Bias in Music Streaming Recommendation via Reward Modification (Research Track)
作者:张骁*,戴孙浩*,徐君,董振华,戴全宇,文继荣
通讯作者:徐君
论文概述:在音乐APP等流媒体应用中,推荐的歌曲常在用户失去注意力的情形下连续播放,这导致训练样本中包含大量错误的用户正反馈(称为注意力偏差)。已有方法直接利用收集到的全部反馈或启发式的删除潜在错误反馈,这将引发反馈数据分布的漂移并损害模型训练的收敛率。本文提出了一种可消除用户注意力偏差的神经竞争赌博机算法(Neural Dueling Bandit,NDB)。NDB维护两个神经网络:注意力网络通过反事实学习方法建模用户专注度并对奖励进行修正;随机映射网络基于修正后奖励进行歌曲推荐并通过无梯度方式探索无限动作空间。理论上,证明了修正后奖励的统计无偏性,且学习到的赌博机策略具有最优的亚线性后悔界保证。音乐推荐数据上的实验结果验证了所提出算法的有效性与高效率。
论文介绍
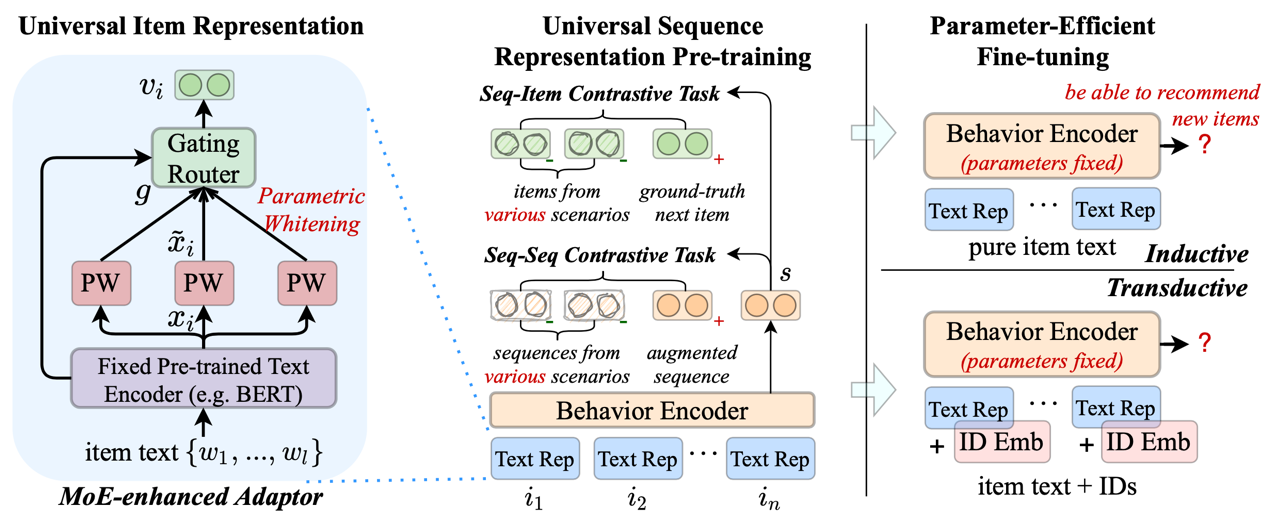
论文题目:Towards Universal Sequence Representation Learning for Recommender Systems (Research Track)
作者:侯宇蓬*,牟善磊*,赵鑫,李雅亮,丁博麟,文继荣
通讯作者:赵鑫
论文概述:为了开发有效的序列推荐模型,现有研究主要采用序列表示学习(SRL)方法,设计各种序列编码器来捕捉用户行为的序列特征。但大多数现有的 SRL 方法都依赖于显式的商品 ID,这使得模型难以迁移到新的推荐场景(例如冷启动推荐)。面对这些问题,我们提出了面向推荐系统的通用序列表示学习方法 UniSRec。为了学习更通用的序列表示,UniSRec 利用商品的相关文本来学习跨领域和跨平台的可迁移表示。为了学习通用商品表示,我们设计了基于参数白化和混合专家增强适配器的轻量级架构。为了学习通用序列表示,我们进行多域负样本采样并引入两种对比学习任务。预训练后的通用序列表示模型可以在归纳(inductive)和转导(transductive)设置下,参数高效地迁移到新的推荐场景。在真实世界数据集上进行的大量实验验证了所提出方法的有效性。特别地,我们的方法在跨平台设置中获得性能提升,展示了所提出的通用 SRL 方法的优异可迁移性。
论文介绍
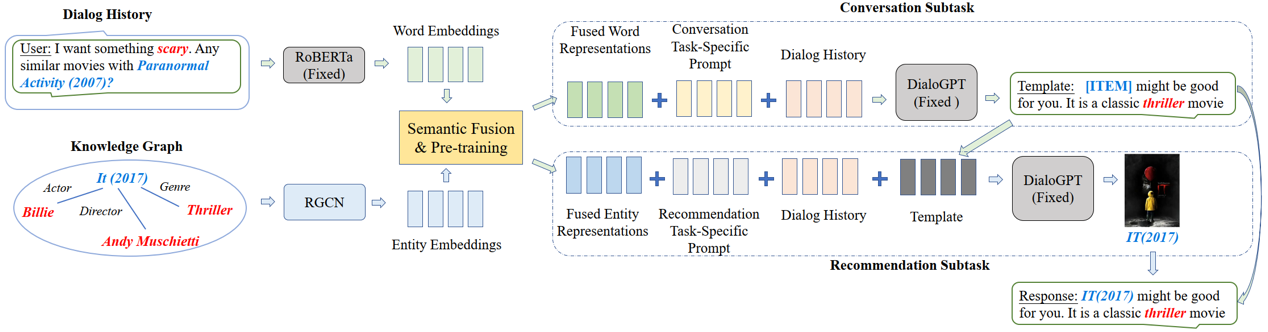
论文题目:Towards Unified Conversational Recommender Systems via Knowledge-Enhanced Prompt Learning (Research Track)
作者:王晓磊*,周昆*,文继荣,赵鑫
通讯作者:赵鑫
论文概述:对话推荐系统(CRS)旨在通过交互式的对话向用户推荐高质量的商品,它通常包括推荐和对话两个模块。现有工作在两个模块之间共享知识和表示,或者设计策略对齐两者的语义。然而,这些方法仍然依赖于不同的模型来分别实现这两个模块,使得他们难以无缝集成。本文基于知识增强的提示学习统一建模对话和推荐这两个模块,分别设计了特定的提示来激发预训练模型完成不同任务。具体而言,我们在提示中加入了语义融合的单词或实体表示,以提供相关的上下文和背景知识。此外,我们还将生成的回复模板作为推荐任务提示的一部分,从而进一步强化了两个任务之间的信息交互。在两个公开数据集上的实验验证了本文方法的有效性。
论文介绍
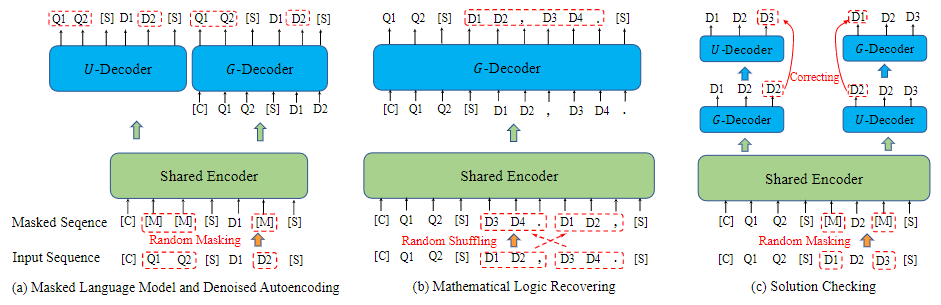
论文题目:JiuZhang: A Chinese Pre-trained Language Model for Mathematical Problem Understanding (Applied Data Science Track)
作者:赵鑫,周昆,龚政,张北辰,周远航,沙晶,陈志刚,王士进,刘聪,文继荣
论文概述:本文提出了第一个中文的数学预训练语言模型——九章,以针对解决数学题理解和表征等相关任务。因为数学题目中既包含许多公式和数字等特殊符号,又蕴含复杂的数学逻辑和背景知识。我们模拟人类的学习过程,采用三阶段的课程学习方法:先针对字符信息进行token-level的预训练,再设计formula-level预训练任务以增强对逻辑关系的理解,最后采用类似对抗训练的自纠错任务强化模型。我们的九章模型在下游九个数学相关任务上均取得了较好的效果,包括分类、检索、问答和生成任务。
论文介绍
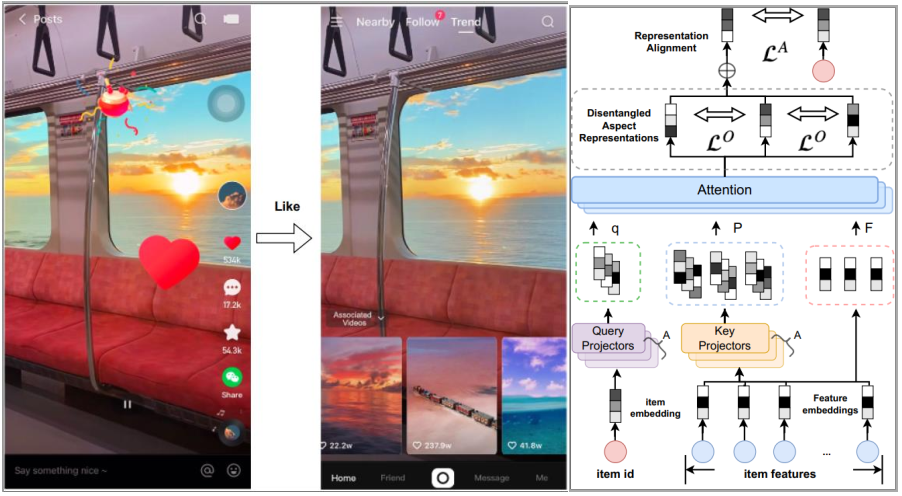
论文题目:Feature-aware Diversified Re-ranking with Disentangled Representations for Relevant Recommendation (Applied Data Science Track)
作者:林子涵*,王辉*,毛景树,赵鑫,王珵,江鹏,文继荣
通讯作者:赵鑫
论文概述:相关推荐是一种特殊的推荐场景,当用户对某个商品表达兴趣时(如点赞、购买),为用户推荐更多的与该商品(称为触发商品)相关的商品。此场景下,由于关注推荐的相关性,更容易导致推荐结果的同质化而带来信息茧房,因此除了考虑推荐商品和触发商品之间的相关性,更应该考虑推荐结果间的多样化。然而,现有的多样化推荐方法主要实现了商品级别的多样性,在相关性的约束下,这种粗粒度的商品级别的多样性效果较差。此外,现有的简单的特征感知推荐方法在表征特征时忽视了商品特征中存在的冗余或噪音问题。考虑以上这些问题,我们提出了一个基于解离表示的多样化重排序框架来实现特征级别细粒度的多样化。该框架由两个主要模块组成:自注意力编码器(DAE)和自平衡的兼顾多方面(multi-aspect)的排序器。在DAE中,我们使用多头注意力机制从丰富的商品特征中学习解离的不同aspect的特征表示。在排序器中,我们设计了一种针对不同aspect的排序机制,能够自适应地平衡每个aspect层面的相关性和多样性。我们从快手短视频平台上收集相关推荐场景下的数据集进行了离线评估,并将我们的重排序框架部署在快手极速版App相关推荐应用下,对推荐效果进行了在线A/B测试,推荐质量和用户体验的显著改进验证了我们方法的有效性。
论文介绍
论文题目:RetroGraph: Retrosynthetic Planning with Graph Search (Research Track)
作者:解曙方, 严睿,韩鹏, 夏应策, 吴郦军, Chenjuan Guo, Bin Yan, 秦涛
通讯作者:严睿
论文概述:逆合成路线规划是人工智能的重要应用方向,对化学和药物研发有重要作用。通常的处理方法是将其建模为搜索问题。近年来,基于深度学习驱动的逆合成规划算法受到大量关注。但是这些算法都是用基于树结构的搜索。我们发现树结构搜索虽然在许多领域都有很好的效果,但在本问题上并非最优。这是因为逆合成问题存在大量的重复结构,包括不同合成目标之间的重复和同一目标内部的重复。因此,我们提出了一个基于图结构的搜索算法,其中的重复节点被压缩在一起。同时,我们提出了基于图神经网络 (GNN)的代价预测模型以引导搜索。在USPTO 数据集上,我们当前最好模型提高了2.6% 的搜索成功率。
论文介绍
论文题目:Personalized Chit-Chat Generation for Recommendation Using External Chat Corpora (Applied Data Science Track)
作者:陈畅与,王希廷,矣晓沅,吴方照,谢幸,严睿
通讯作者:严睿
论文概述:闲聊被证明可以有效地让用户参与人机交互。我们通过用户研究发现,为新闻文章生成适当的闲聊可以帮助扩大用户兴趣并增加用户阅读新闻文章的概率。基于这一观察,我们提出了一种为新闻推荐生成个性化闲聊的方法。与现有的个性化文本生成方法不同,我们的方法只需要使用外部的聊天语料库,也就是说,不要求聊天语料与推荐数据集中的用户和新闻有直接对应关系。这是通过设计一种弱监督方法来实现的,该方法将新闻推荐模型学习的知识进行迁移来估计用户对闲聊帖子的个性化兴趣。基于上述提到的用户兴趣的估计方法,我们提出了一种强化学习框架来生成个性化聊天。我们通过广泛的实验,包括自动的离线评估和用户研究,证明了我们方法的有效性。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox