学院新闻
我院师生论文被CCF A类会议ACL录用
日期:2022-03-02访问量:2月24日,国际学术会议ACL 2022论文接收结果公布,中国人民大学高瓴人工智能学院师生有6篇论文被录用。国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称ACL)是自然语言处理领域顶级学术会议,在世界范围内每年召开一次,2022年是第60届会议,将于5月22-27日在爱尔兰首都都柏林以线上线下混合形式举行。

论文介绍
论文题目:MISC: A Mixed Strategy-Aware Model integrating COMET for Emotional Support Conversation
作者:涂权,李嫣然,崔建伟,王斌,文继荣,严睿
通讯作者:严睿
论文概述:将现有方法应用于情感支持对话(为求助者提供有价值的帮助)有两个主要限制:(a)他们通常使用对话级别的粗粒度情感标签,无法捕捉到用户的即时心理状态; (b) 大部分研究者只注意在回复中表达共情,而不是考虑使用对话策略来逐渐降低用户的精神压力。为了解决这些问题,我们提出了一种新颖的模型MISC(Mixed Strategy-Aware Model integrating COMET),它首先基于COMET来捕获用户的细粒度心理状态,然后结合混合策略生成回复。基准数据集上的实验结果证明了我们方法的有效性,并揭示了细粒度情感理解和混合策略建模的好处。
论文介绍
论文题目:Finding the Dominant Winning Ticket in Pre-Trained Language Models
作者:龚卓成,贺笛,Yelong Shen,刘铁岩,Weizhu Chen,赵东岩,文继荣,严睿
通讯作者:严睿,赵东岩
论文概述:预训练模型是机器学习和自然语言处理中的一个重要方向。虽然预训练方法 在众多自然语言处理任务上性能突出,但其参数量也远远超出了传统模型。我们认为,在针对任务的微调阶段,对预训练模型进行全参数更新是不必要的。通过实验我们发现,在预训练模型内部存在一个极小的结构化的子网络,只需要更新这个子网络的参数,就能取得和全参数更新一样的性能表现,并且这个子网络很大程度上在不同的下游任务之间共享。
论文介绍
论文题目:Keywords and Instances: A Hierarchical Contrastive Learning Framework Unifying Hybrid Granularities for Text Generation
作者:李明哲,林谢雄,陈秀颖,昌晋雄,张祺深,王峰,王太峰,刘忠义,褚崴,赵东岩,严睿
通讯作者:赵东岩,严睿
论文概述:对比学习在生成任务中取得了令人瞩目的成功,它能够缓解“曝光偏差”问题并有区别地利用不同质量的参考。现有的工作大多侧重于实例级别的对比学习,不区分每个单词的贡献。而关键字作为文本的要点,它能够主导这种受到一定限制的映射关系。因此,我们提出了一种分层对比学习方法,可以统一输入文本中的混合粒度的语义。具体来说,我们首先通过正负对的对比关系构建关键字图结构,并迭代地完善关键字表示。然后,我们在实例级别和关键字级别上分别构建内部对比。最后,为了弥补各个独立对比级别之间的差距并解决常见的对比消失的问题,我们提出了一种层间对比机制,该机制能够衡量正负关键字节点与实例分布之间的差异。实验表明,我们的模型在改写、对话生成和故事生成任务方面优于基线模型。
论文介绍
论文题目:ProphetChat: Enhancing Dialogue Generation with Simulation of Future Conversation
作者:刘畅,谭旭,陶重阳,付振新,赵东岩,刘铁岩,严睿
通讯作者:赵东岩,严睿
论文概述:经典的生成式对话模型利用对话历史信息来生成回复。然而,由于一句对话通常可以由多个不同的候选回复恰当地回答,因此仅基于对话历史信息生成合适的回复并不容易。从直觉上看,如果聊天机器人能够提前“预见”用户在收到回复后将要谈论的内容(即对话未来),并将其作为额外信息辅助生成回复,那么它可能可以生成一个更丰富充实的回复。为此,我们提出了一个名为 ProphetChat 的新型对话生成框架,该框架通过在生成阶段模拟对话未来从而增强回复生成的能力。为了使聊天机器人能够预见对话未来,我们基于一个经典的对话生成模型和一个对话选择模型设计了一个类似于集束搜索的对话模拟策略来模拟可能的对话未来。然后,我们同时利用对话历史信息和模拟出的对话未来信息共同生成更加丰富充实的回复。在两个常用的的开放域对话数据集上的实验表明,ProphetChat 相比强力的基线模型可以生成更好的回复,这充分证明了我们的方法的有效性。
论文介绍
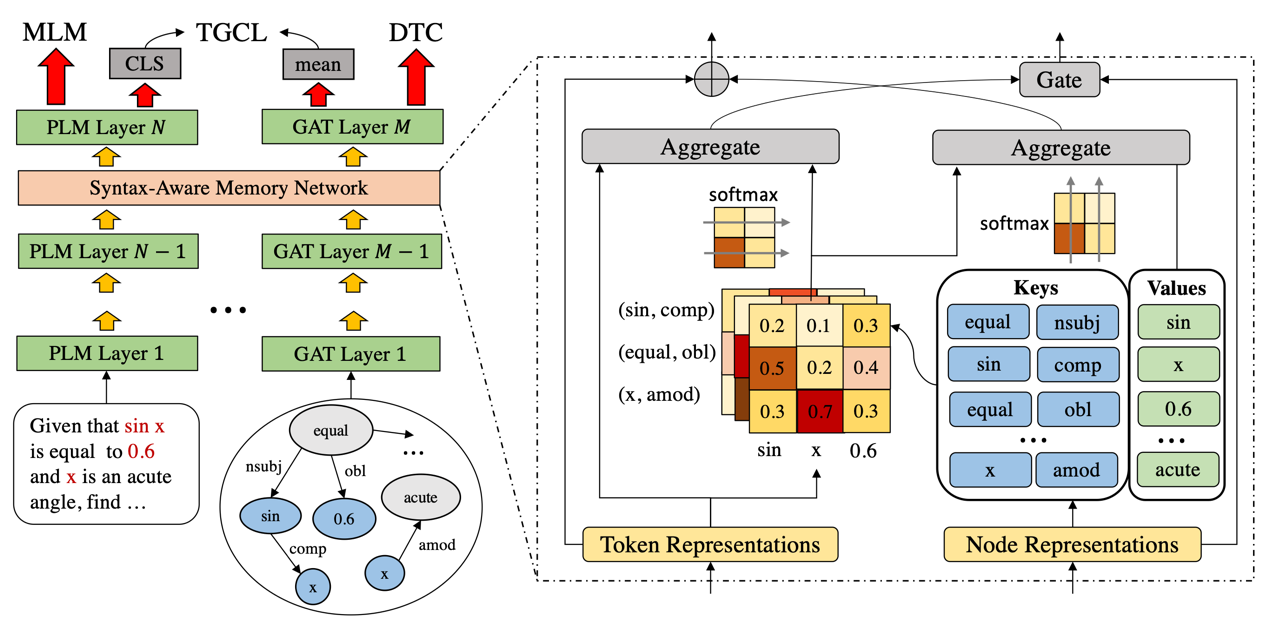
论文题目:Continual Pre-training of Language Models for Math Problem Understanding with Syntax-Aware Memory Network
作者:龚政*,周昆*,赵鑫,沙晶,王士进,文继荣
通讯作者:赵鑫
论文概述:预训练语言模型(PLM)当前在各个自然语言理解任务上都取得了卓越的性能。本文主要关注于如何提升PLM对数学问题文本的理解能力。相比于常规文本,数学问题中包含了文本描述和数学公式两部分,这两部分含有天然的语义差距,但包含的信息都对彼此至关重要。本文设计了一种Syntax-Aware的结构来帮助模型建模公式中包含的结构信息以及和文本描述之间的关联。本文进一步设计了合适的预训练任务来帮助模型学习以及融合文本描述和数学公式的语义。
论文介绍
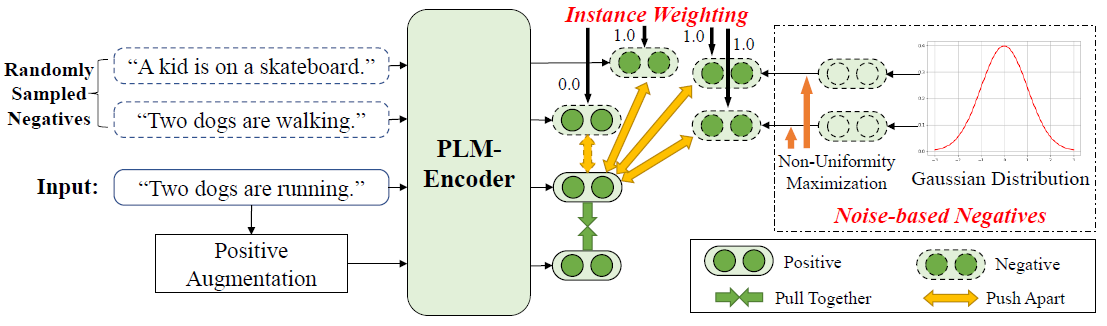
论文题目:Debiased Contrastive Learning of Unsupervised Sentence Representations
作者:周昆,张北辰,赵鑫,文继荣
通讯作者:赵鑫
论文概述:对比学习近年来被广泛用于对预训练模型进行微调以得到高质量的句子表示,其通过对齐语义相似的正例的表示并同时推远语义无关的负例的表示以优化所有句子表示的语义空间。然而已有的工作往往利用随机采样的方法获取负例,这就可能受部分有偏的负例影响,如“假负例”和“各向异性表示”等。为解决该问题,本文提出了一种去偏的对比学习框架,其不仅惩罚了可能的假负例,且生成基于噪声的负例来进一步缓解表示各向异性带来的影响。我们的方法可以应用于BERT/RoBERTa-base/large上,并在7个语义相似度任务上均带来了提升。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox