学院新闻
高瓴人工智能学院师生7篇论文被国际学术会议WSDM录用
日期:2021-10-14访问量:10月12日,中国计算机学会(CCF)推荐的B类国际学术会议WSDM2021论文接收结果公布。中国人民大学高瓴人工智能学院师生有7篇论文被录用。第15届国际互联网搜索与数据挖掘会议(The 15th International Conference on Web Search and Data Mining, WSDM 2022)将于2022年2月21日-2月25日在美国亚利桑那州凤凰城召开。WSDM是信息检索与数据挖掘领域的国际顶级会议,由SIGIR、SIGKDD、SIGMOD和SIGWEB四个专委会协调筹办,在互联网搜索、数据挖掘领域享有较高学术声誉。本次会议共收到来自786 篇长文投稿,仅有159篇长文被录用,录用率约20.23%。
2021年1月至今,高瓴人工智能学院已发表或被录用CCF A类国际期刊或和会议论文67篇、CCF B类期刊和论文34篇。

论文介绍
论文题目:Improving Session Search by Modeling Multi-Granularity Historical Query Change
作者:左笑晨,窦志成,文继荣
通讯作者:窦志成
论文概述:在会话搜索中,利用用户和搜索引擎之间的历史交互来提高文档检索的效率是十分重要的。但并非所有历史信息都有助于候选文档的排序。实际上,用户在修改每一个查询的过程中经常会表达自己的偏好,这可以帮助我们在历史交互中捕捉有用的信息。受此启发,本文对历史查询重塑进行建模以提高文档排序的效果。具体地,本文在词级别和语义级别刻画每组相邻查询的变化。在对词级别查询变化进行建模时,模型计算三种类型的词权重,包括保留词权重、添加词权重和移除词权重。随后利用词权重对每个查询与候选文档做细粒度交互。在对语义级别的查询变化建模时,模型通过整合不同类型词权重获得的每个历史查询的表示来刻画用户的整体意图。为了提高查询重塑建模的效果,模型还引入查询重塑分类作为辅助任务。
论文题目:A Neighborhood-Attention Fine-grained Entity Typing for Knowledge Graph Completion
作者:卓建欢,朱倩男,岳银亮,赵雨虹,韩维思
通讯作者:朱倩男,岳银亮
论文概述:知识图谱作为重要资源已被广泛应用于信息检索,推荐系统,自然语言处理等各领域。但知识图谱通常面临着不完整的现象。知识补全旨在利用知识图谱的结构化信息预测知识图谱中丢失的三元组,已然成为知识图谱领域的研究热点。而实体类型预测是补全知识图谱的有效手段。目前实体类型预测的方法大多利用实体自身的结构化特征补全实体的类型,但这些方法无法充分预测细粒度的实体类型之间的层次关系,比如/location/location包含/location/uk_civil_parish类型。为解决上述问题,本文融合实体的邻域信息,提出了一种类型感知的注意力神经网络用于预测实体的细粒度类型。具体的,该方法设计了类型驱动的注意力机制,针对不同的实体类型,为实体邻居分配不同的权重分布,并以不同权重分布集成邻居实体以获得实体针对某类型的特征表示。最后通过该邻域特征与实体类型的匹配得分来预测实体是否属于该类型。此外,为提高模型鲁棒性,本文提出了一种平滑函数用于邻域稀疏的实体。本文在知识图谱Freebase和Yago上进行的实体类型预测实验,实验结果表明实体邻居上的不同权重分布可以体现实体细粒度类型之间的层次化结构。同时,与其他实体类型预测模型相比,本文提出的方法取得了较好的类型预测性能。
论文题目:Improving Personalized Search with Dual-Feedback Network
作者:邓琛龙,周雨佳,窦志成
通讯作者:窦志成
论文概述:个性化搜索通过建模历史用户行为提高了搜索结果的质量。近年来,许多基于深度学习的方法大大提高了个性化搜索的性能。然而,现有的方法大多只关注正向用户行为信号的建模,导致用户兴趣的建模不完全。同时,用户的搜索行为隐藏了大量的显性或隐性的反馈信息。例如,点击并停留一定时间代表显性的积极反馈,而跳过行为则代表由各种原因造成的隐性消极反馈。直观地说,这些信息可以用来构建更完整、更真实的用户兴趣。在本文中,我们提出了一个双反馈建模框架,该框架集成了多粒度用户反馈信息,以增强用户当前的搜索意图。具体地说,我们提出了一个反馈提取网络,以细化多个阶段的双反馈表示。为了提高用户的实时搜索质量,我们设计了一个双反馈特征门控模块来捕捉用户在当前会话中的实时反馈。我们在两个真实的数据集上进行了大量的实验,实验结果表明,我们的方法可以有效地提高个性化搜索的性能。
论文题目:Leveraging Multi-view Inter-passage Interactions for Neural Document Ranking
作者:付成真,胡恩瑞,冯乐天,窦志成,贾岩涛,陈雷,于璠,曹朝
论文概述:经典的transformer模型将输入序列的长度限制在512,无法直接应用于通常包含更长上下文的文档排序场景。为此,许多研究考虑对文档进行段落切分,并依据细粒度的段落级别的相关性信号实现文档排序。然而,这类模型大多对切分后的各个段落单独建模,缺乏对段落间长距离语义依赖关系的捕捉,导致文档与问题匹配的不准确性。为此,在本文中,我们提出基于多视角建模跨段落语义交互的排序模型MIR,将段落内和段落间的语义关联以互补的方式结合在一起。前者捕捉每个段落内部的局部语义关系,而后者捕捉不同段落之间的全局语义依赖关系。此外,我们通过多视角的注意力模式来刻画这种全局关系,允许语义信息在词语(token)、句子(sentence)和段落(passage)三种粒度上实现传播和交互。其中,词语层面的交互有助于捕捉长距离语义依赖并生成全局上下文表示;句子和段落级别的交互有助于捕获全局语义一致性并隐式归纳文档主题。最终,这些不同粒度的表示被汇聚为文档语义表示以用于排序。我们在MS MARCO和TREC DL两个基准数据集上进行了实验。实验结果表明,MIR比现有的针对段落建模的方法有明显的效果提升。
论文题目:HeteroQA: Learning towards Question-and-Answering through Multiple Information Sources via Heterogeneous Graph Modeling
作者:高莘,张寓驰,王永亮,董扬,陈秀颖,赵东岩,严睿
通讯作者:严睿,赵东岩
论文概述:社区问答(CQA)是一项被定义明确的任务,可用于许多场景,例如电子商务和一些在线用户社区。在这些社区中,用户可以发表文章、发表评论、提出问题和回答问题。在这些异构信息源中,每个信息源都有自己特殊的结构和上下文(例如在文章或相关问题上的评论或答案)。现有的大多数 CQA 方法仅结合文章或维基百科来提取知识并回答用户的问题。然而,这些CQA方法并没有充分挖掘社区中的异构信息源,这些异构信息源(MIS)可以为用户的问题提供更多的相关知识。因此,我们提出了一种问题感知异构图模型,利用异构信息源自动生成答案。为了评估我们提出的方法,我们在两个数据集上进行了实验:其中MSM_plus是基准数据集 MS-MARCO 的修改版本,还有第一个大规模社区问答数据集 AntQA, 其中包含四种类型的异构信息源。在这两个数据集上的大量实验表明,我们的模型在所有指标方面都优于所有基线模型。
论文题目:A Cooperative Neural Information Retrieval Pipeline with Knowledge Enhanced Automatic Query Reformulation
作 者:李祥圣,毛佳昕,马为之, 刘奕群,吴之璟,张敏,马少平,王钊伟,何秀强
论文概述:搜索引擎中的查询词往往比较短且存在意图模糊等问题,深度检索模型直接利用用户的原始查询进行建模存在局限性。我们在深度检索模型之上,加入了一个查询改写模块,使得查询改写与深度检索模型共同优化。该框架首先对原始查询进行改写,再将改写后的查询提交到检索模型中进行训练。查询改写模块利用强化学习,旨在于优化查询词使得检索模型效果提升,检索模型旨在于优化排序性能,两者相互迭代学习。该框架可以应用到任意的检索模型中,我们采用固定参数的方法,交替地训练查询改写模型与检索排序模型,使得两者效果共同提升。且实验发现,通过引入知识信息对查询改写模块进行完善,可以进一步促进深度排序模型的排序效果。
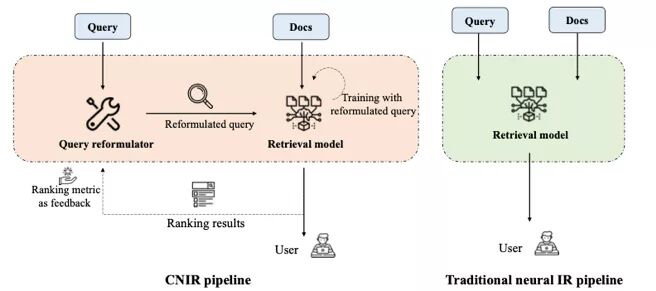
图:基于查询改写的深度检索模型框架与传统检索模型框架
论文题目:Learning Discrete Representations via Constrained Clustering for Effective and Efficient Dense Retrieval
作 者:詹靖涛,毛佳昕,刘奕群,郭嘉丰,张敏,马少平
论文概述:虽然向量检索已经取得了不错的排序性能,但是已有的向量检索模型的存储开销和时间开销都很大。这主要是由于大多数工作都需要存储稠密向量并且进行近邻搜索(NNS)。因此,我们提出一个新颖的检索模型RepCONC。RepCONC通过有约束聚类(Constrained Clustering)来端到端地联合优化dual-encoders和Product Quantization来学习离散的表示。在检索时,RepCONC使用近似近邻搜索(ANNS)来进行高效地检索。有约束聚类是对量化过程的建模,它约束稠密向量被均匀地分配到不同的量化中心。我们理论上说明了该约束的重要性,使用最优传输理论推导出了近似的解,并用到了模型训练中。我们在MS MARCO段落检索和文档检索数据集上进行实验。实验结果表明,RepCONC在排序性能、存储效率、时间效率上都显著优于各种不同的检索模型。
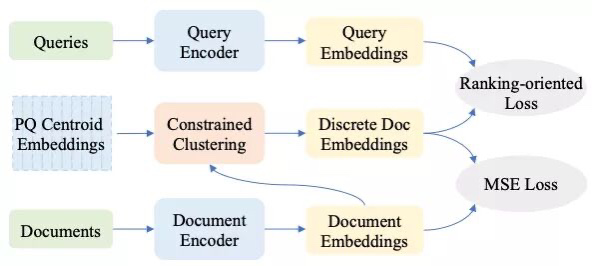
图:RepCONC训练流程图
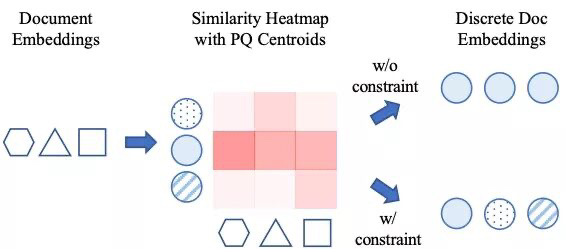
图:Constrained Clustering示意图
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox