学院新闻
高瓴人工智能学院11篇长文被国际学术会议ACM CIKM录用
日期:2021-08-10访问量:8月8日,中国人民大学高瓴人工智能学院师生有11篇长文被国际学术会议ACM CIKM(2021)录用。第30届国际计算机学会信息与知识管理大会(The 30th ACM International Conference on Information and Knowledge Management, CIKM 2021)将于今年11月1日-11月5日在线召开。CIKM是CCF推荐的B类国际学术会议,是信息检索和数据挖掘领域顶级学术会议之一。本届会议共收到投稿1251篇,其中录用论文271篇,录取率约为21.7%。
2021年1月至今,高瓴人工智能学院已发表或被录用CCF A类国际期刊和会议论文51篇、CCF B类期刊和论文19篇;以人大师生为第一作者或通讯作者发表的论文数量为62篇。

论文介绍
论文题目:PSSL: Self-supervised Learning for Personalized Search with Contrastive Sampling
作者:周雨佳,窦志成,朱余韬,文继荣
通讯作者:窦志成
论文概述:个性化搜索由于能够根据用户历史行为构造用户画像,因此在改善用户搜索体验方面发挥着至关重要的作用。前人研究已在通过查询日志提取个人信号和学习用户表征方面取得了很大进展。然而,基于神经网络的个性化搜索极其依赖于足够的数据来训练用户模型,数据稀疏性是现有个性化搜索方法学习高质量用户表征不可避免的挑战。此外,过分强调最终排序质量可能导致数据表征粗糙,且会损害模型的泛化性。为了解决这些问题,我们提出一个带有自监督学习的个性化搜索框架来增强数据表征。具体来说,我们采用对比抽样方法从查询日志中的用户行为序列中提取成对的自监督信息,并设计4个辅助任务来对排序模型中使用的句子编码器和序列编码器进行预训练,任务通过对比损失进行优化,以缩小相似用户序列、查询和文档之间的距离。在两个数据集上的实验结果表明,与现有基线模型相比,我们提出的模型排序提升显著。
论文介绍
论文题目:Learning Implicit User Profiles for Personalized Retrieval-Based Chatbot
作者:钱泓锦,窦志成,朱余韬,马跃元,文继荣
通讯作者:窦志成
论文概述:本文中,我们探讨了个性化聊天机器人的问题。个性化聊天机器人是一个用户的虚拟聊天助手。个性化聊天机器人的关键特征是它与用户具有一致的个性。当它被委派响应他人的消息时,它可以像用户一样说话。当前有许多个性化机器人的工作,但其中大多数使用显示的用户档案,包括个性描述或基于键值的个人信息。然而,在实际场景中,用户可能不愿意编写详细的个性描述。另外,获得大量显示的用户档案需要大量的标注。为了解决这个问题,我们提出了一种基于检索的个性化聊天机器人模型IMPChat,它从用户的对话历史中学习隐式用户档案。我们认为隐式用户档案在可获取性和灵活性方面优于显式用户档案。IMPChat通过分别对用户的个性化语言风格和个性化偏好建模来学习隐式用户档案。为了学习用户的个性化语言风格,我们根据用户的历史回复,从浅到深精心构建语言模型;为了模拟用户的个性化偏好,我们探索了用户的每个问答对对下的条件关系。个性化偏好是动态的和上下文感知的:在聚合个性化偏好时,我们为与当前问题相关的那些历史问答对分配更高的权重。我们将每个回答候选分别与个性化语言风格和个性化偏好进行匹配,并融合两个匹配信号来确定最终的排序分数。我们在两个大规模数据集进行了充分的实验,结果表明我们的方法优于所有基线模型。
论文介绍
论文题目:USER: A Unified Information Search and Recommendation Model based on Integrated Behavior Sequence
作者:姚菁,窦志成,谢若冰,路彦雄,王志平,文继荣
通讯作者:窦志成
论文概述:搜索和推荐是用户获取信息最常用的两种方式,两个任务的目标都是满足用户的信息需求。目前,很多网络平台和移动App同时提供了搜索和推荐服务,为同时解决这两个任务提出了需求也提供了机会。然而,现有的大部分平台仍然使用独立的搜索模型和推荐模型来提供两种服务,没有利用两个任务之间的依赖和关联。在这篇文章中,我们提出“对两个任务联合建模有助于提升两个任务以及用户的综合满意度”。我们首先将用户的搜索行为和推荐中的浏览行为整合成一个异质性的行为序列,然后我们用一个联合模型(USER)从这个整合的行为序列中挖掘用户兴趣来同时解决两个任务。我们提出的联合模型具有几个优势:(1) 合并了搜索和推荐日志可以缓解数据稀疏性的问题;(2) 基于整合的行为序列,我们可以获得更准确的用户画像;(3) 我们可以捕捉两个任务间潜在的关联来促进两个任务。我们利用真实网络平台上的数据进行了实验,结果证明我们的联合模型优于独立的搜索模型和推荐模型。
论文介绍
论文题目:Contrastive Learning of User Behavior Sequence for Context-Aware Document Ranking
作者:朱余韬,聂建云,窦志成,张鑫宇,杜潘,左笑晨,蒋昊
通讯作者:窦志成
论文概述:搜索会话中的上下文信息已被证明有益于捕捉用户搜索意图。现有研究以不同方式探索会话中的用户行为序列,以增强查询建议或文档排序。然而,用户行为序列往往被视为反映用户行为的明确而准确的信号。实际上,用户对同一意图的查询可能会有所不同,并且可能会点击不同的文档。为了学习更稳健的用户行为序列表示,我们提出了一种基于对比学习的方法,该方法考虑了用户行为序列的可能变化。具体来说,我们提出了三种数据增强策略来生成用户行为序列的相似变体,并将它们与其他序列进行对比。这样做时,模型被迫在可能的变化方面更加稳健。优化的序列表示被合并到文档排序中。在两个真实查询日志数据集上的实验表明,我们提出的模型显着优于最先进的方法,这证明了我们的方法在上下文感知文档排名方面的有效性。
论文介绍
论文题目:Top-N Recommendation with Counterfactual User Preference Simulation
作者:杨梦月,戴全宇,董振华,陈旭,何秀强,汪军
通讯作者:陈 旭
论文概述:本文提出利用反事实的方法来提升推荐系统的性能。具体来讲,本文首先构建适用于推荐算法的因果图,其次通过变分推断的方法求解外生变量的后验分布,最后通过采样的方法模拟新的用户数据。为了更好的服务于优化目标,本文采用了强化学习的方式来提升采样的效果,最后本文从理论上给出一定的分析,解释模型不同组建设计的合理性。
论文介绍
论文题目:Counterfactual Review-based Recommendation
作者:熊坤,叶文文,陈旭,张永峰,赵鑫,胡斌彬, Zhiqiang Zhang and Jun Zhou
通讯作者:陈 旭
论文概述:本文提出利用反事实的方法来建模用户的评论行为。根据观察到的样本,本文希望回答“如果用户不关心某个特征,那么他对某个商品对的喜好排序是怎么样的?”这一反事实问题。为了回答这一问题,本文设计了一种求解临界点的方法来找到用户兴趣的边界。根据模型的求解结果,本文可以生成基于排序的商品解释,从而推动可解释推荐领域的发展。
论文介绍
论文题目:Jointly Optimizing Query Encoder and Product Quantization to Improve Retrieval Performance(该论文系与清华大学合作)
作者:詹靖涛,毛佳昕,刘奕群,郭嘉丰,张敏,马少平
论文概述:尽管向量检索(Dense Retrieval)已经取得了不错的排序性能,之前的相关研究通常采用暴力搜索。在实际的网页搜索场景中,暴力搜索会带来大量存储和时间开销,因此几乎是无法接受的。为了解决这样的问题,我们提出JPQ。JPQ使用乘积量化(Product Quantization)来压缩存储并提升检索速度。为了保证检索性能不因为量化而损失,JPQ端到端地联合优化查询编码器和乘积量化的参数。我们在两个公开的大规模检索数据集上评测JPQ。实验结果表明,在不同设置下,JPQ都显著优于现有的向量压缩方法。与之前使用暴力搜索的向量检索模型相比,JPQ几乎不会影响排序性能,并且把索引大小压缩了30倍,提高了10倍的CPU检索速度和2倍的GPU检索速度。

图:MSMARCO Passage上不同模型的检索性能—索引大小对比图 (JPQ的索引大小是ColBERT的索引的1/186)
论文介绍
论文题目:Evaluating Relevance Judgments with Pairwise Discriminative Power(该论文系与清华大学合作)
作者:储著敏,毛佳昕,张帆,刘奕群,Tetsuya Sakai,张敏,马少平
论文概述:随着不同级别、不同标注准则的标注数据日趋增多,相关性标注的评价工作也遇到了新的挑战。传统的基于标注一致性的评价指标(例如Kappa、Krippendorff’s alpha)无法应对跨级别标注的问题,“可靠但无效”的现象一直存在;以Discriminative Power为代表的基于排序评价指标效能的评价方式,在跨级别的比较中也存在“取值漂移”的问题,同时依赖于一系列已存在的排序runs也让其泛用性受到影响。
为应对这一挑战,我们创新性地提出了PDP(Pairwise Discriminative Power)指标。PDP通过对于潜在排序列表的不确定性进行衡量,从而达到评估相关性标注质量的效果。具体地,我们通过引入适量的相关性偏好标注,对于每个文档对之间的偏好概率进行衡量,进而得到各潜在排序列表的概率,亦即排序的不确定性。通过一系列详尽的合成数据集和真实数据集的实验,我们验证了PDP对于评价相关性标注质量的有效性,并且随着标注级别的增加,相较于出现一定性能下降的其他评价指标,PDP依然能有着稳定的表现。真实数据集上的结果也说明PDP指标能够很好地比较不同的标注设置,同时也通过实验论证了传统指标所存在的问题。实验部分,我们同时也对于所需引入的相关性偏好标注数量进行了分析和讨论。
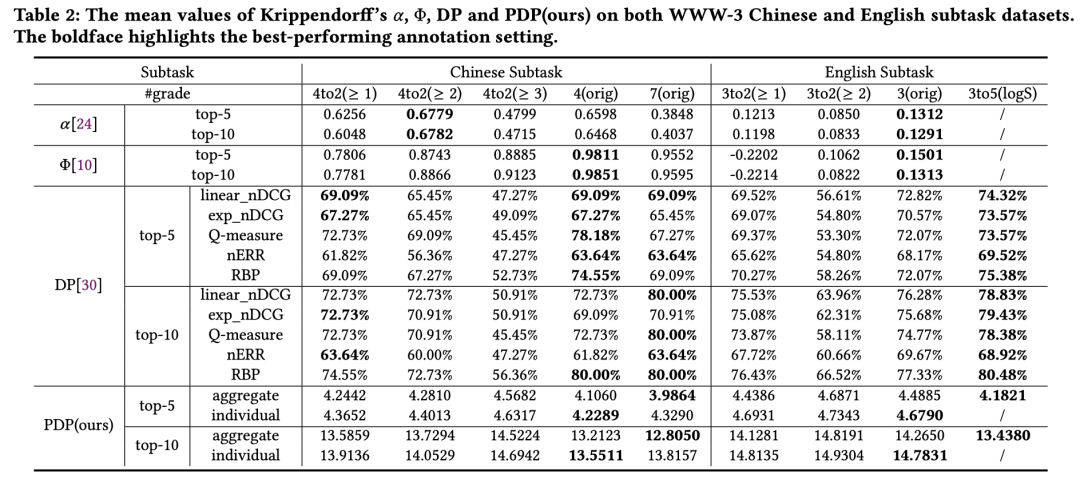
表:PDP与传统指标在真实数据集上的表现
论文介绍
论文题目:Incorporating Query Reformulating Behavior into Web Search Evaluation(该论文系与清华大学合作)
作者:陈佳,刘奕群,毛佳昕,张帆,Tetsuya Sakai,马为之,张敏,马少平
论文概述:搜索评价在信息检索 (IR) 研究中发挥着重要的作用,但已有的大多数评价指标基于的用户模型主要关注浏览和点击行为。由于用户的感知满意度也可能受到其搜索意图的影响,根据各种搜索意图来构建不同的用户模型可能有助于设计更好的评价指标。在实际场景中,用户意图通常是不可观测的隐变量。然而用户的查询重构行为却是可以被观测的,可能在一定程度上反映了他们的搜索意图,并且与用户对特定查询的感知满意度高度相关。为了研究查询重构、搜索意图和用户满意度之间的关系,我们对一个公开的Field Study数据集进行了研究,发现用户的查询重构行为是一个很好的、可推断其搜索意图的代理信号。因此,考虑查询重构行为可能有助于设计更好的网页搜索评价指标。在本文中,我们提出了一组基于用户查询重构行为的评价指标(Reformulation-Aware Metrics,RAMs)来改进现有的基于点击模型的评价指标。基于两个公开会话数据集的实验结果表明,与现有评估指标相比,RAMs与用户真实满意度的相关性更高。在鲁棒性测试中,我们发现即使只有一小部分满意度训练标签可用时,RAMs仍可以取得良好的性能。进一步的实验表明,RAMs可以在训练好参数后直接应用于新数据集中进行离线评估。本项工作展示了结合细粒度的搜索上下文因素来设计更好的评估指标的可能性,对未来优化评价指标的方向提供了一定的指导。
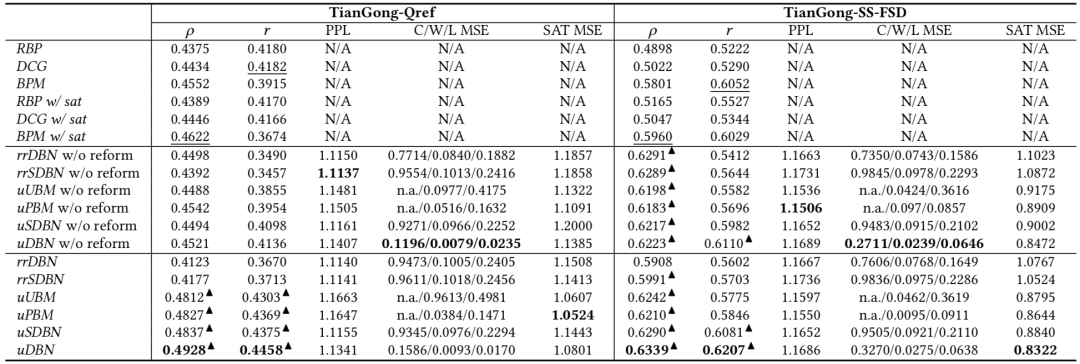
表:在TianGong-SS-FSD和TianGong-Qref两个数据集上的满意度预测效果对比
论文介绍
论文题目: POSSCORE: A Simple Yet Effective Evaluation of Conversational Search with Part of Speech Labelling(该论文系与诺丁汉大学合作)
作者:Zeyang Liu, Ke Zhou, 毛佳昕, Max Wilson
论文概述:如何有效地评价对话式搜索(Conversational search)系统一直是一个有挑战性的问题。由于对话式搜索系统提供给用户的搜索结果是以自然语言的方式呈现的,可能的搜索结果有是无限的,因此我们无法利用人工标注的方式对无限多个可能的搜索结果进行相关性标注。在本文中,我们提出了一种简单而有效的对话式搜索评价指标POSSCORE。该方法在基于embedding的评价指标的基础上,进一步考虑了词性标注(part of speech, POS)信息。该工作第一次在对话式搜索评价中引入了句法信息。实验结果表明,我们提出的方法与用户偏好具有较强的相关性,评价性能相较于已有方法取得了显著的提升。
联系
- ai@ruc.edu.cn | 86-10-62511257
- 北京市海淀区中关村大街59号中国人民大学
- copyright 2021 中国人民大学高瓴人工智能学院
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox