Five GSAI Articles Accepted by the international academic conference of ACM CIKM
Five articles by Gaoling School of Artificial Intelligence(GSAI), Renmin University of China, have recently been accepted by the international academic conference of ACM CIKM(2020). The 29th ACM International Conference on Information and Knowledge Management (CIKM 2020) will be held online from October 19th to October 23rd, 2020. As a category B conference recommended by CCF, CIKM is one of the top academic conferences in the field of information retrieval and data mining. This year, CIKM received a total of 920 paper submissions, with only 193 being accepted, making the acceptance rate about 21%.
Relevant Articles
Title:Diversifying Search Results using Self-Attention Network
Authors: Xubo Qin(PhD at RUC), Zhicheng Dou , Ji-Rong Wen
Cooresponding Author: Prof. Zhicheng Dou
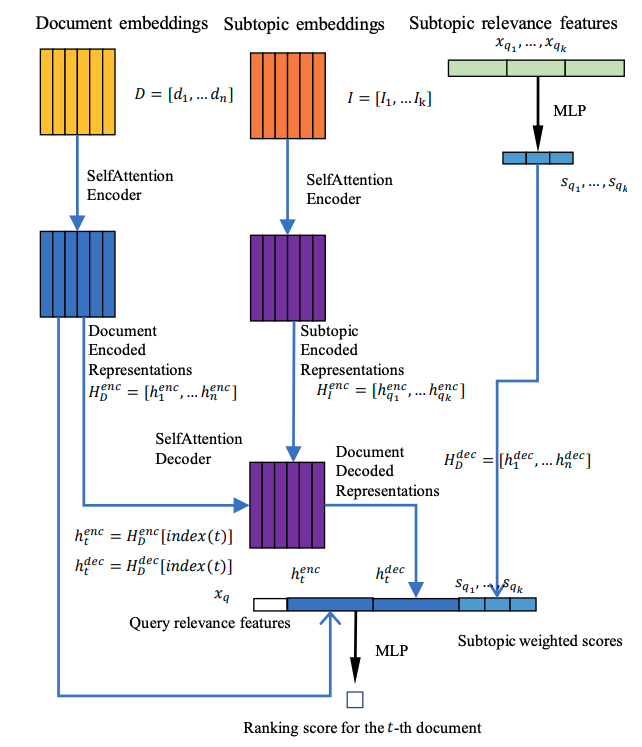
Abstract: Search results returned by search engines need to be diversified in order to satisfy different information needs of different users. Several supervised learning models have been proposed for diversifying search results in recent years. Most of the existing supervised methods greedily compare each candidate document with the selected document sequence and select the next local optimal document. However, the information utility of each candidate document is not independent with each other, and research has shown that the selection of a candidate document will affect the utilities of other candidate documents. As a result, the local optimal document rankings will not lead to the global optimal rankings. In this paper, we propose a new supervised diversification framework to address this issue. Based on a self-attention encoder-decoder structure, the model can take the whole candidate document sequence as input, and simultaneously leverage both the novelty and the subtopic coverage of the candidate documents. We call this framework Diversity Encoder with Self-Attention (DESA). Comparing with existing supervised methods, this framework can model the interactions between all candidate documents and return their diversification scores based on the whole candidate document sequence. Experimental results show that our proposed framework outperforms existing methods. These results confirm the effectiveness of modeling all the candidate documents for the overall novelty and subtopic coverage globally, instead of comparing every single candidate document with the selected sequence document selection.
Title:PSTIE: Time Information Enhanced Personalized Search
Authors:Zhengyi Ma(Master student at RUC),Zhicheng Dou,Guanyue Bian,Ji-Rong Wen
Cooresponding Author: Prof. Zhicheng Dou
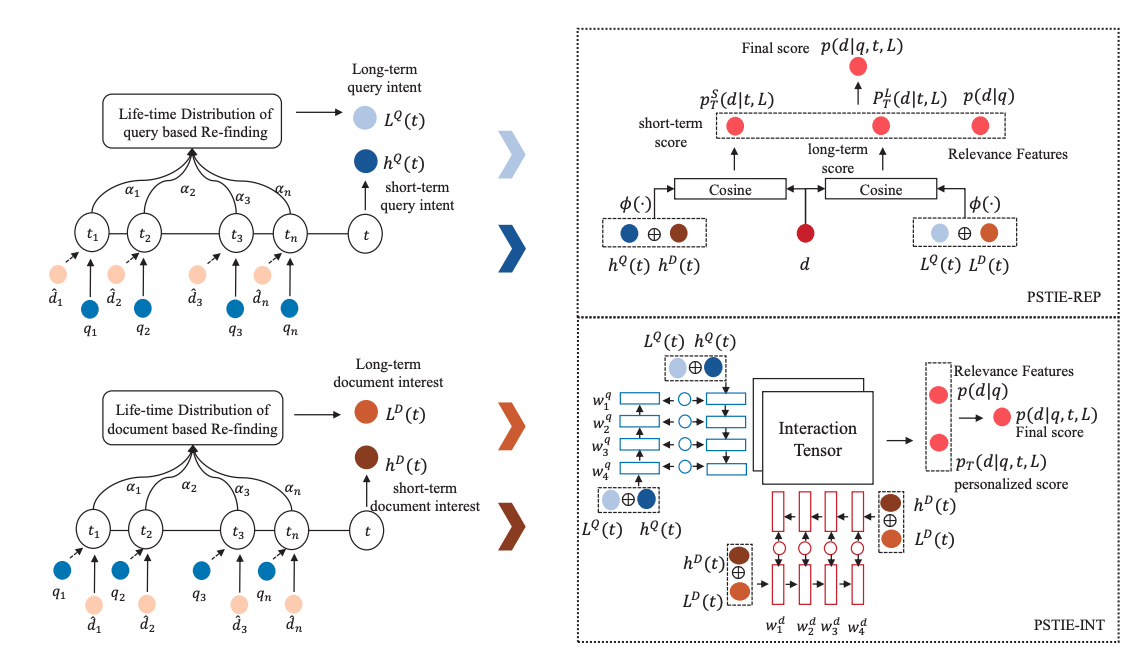
Abstract: Personalized search aims to improve the search quality by re-ranking the candidate document list based on user's historical behavior. Existing approaches focus on modeling the order information of user's search history by sequential methods such as Recurrent Neural Network (RNN). However, these methods usually ignore the fine-grained time information associated with user actions. In fact, the time intervals between queries can help to capture the evolution of query intent and document interest of users. Besides, the time intervals between past actions and current query can reflect the re-finding tendency more accurately than discrete steps in RNN. In this paper, we propose PSTIE, a fine-grained Time Information Enhanced model to construct more accurate user interest representations for Personalized Search. To capture the short-term interest of users, we design time-aware LSTM architectures for modeling the subtle interest evolution of users in continuous time. We further leverage time in calculating the re-finding possibility of users to capture the long-term user interest. We propose two methods to utilize the time-enhanced user interest into personalized ranking. Experiments on two datasets show that PSTIE can effectively improve the ranking quality over state-of-the-art models.
Title:Learning to Match Jobs with Resumes from Sparse Interaction Data using Multi-View Co-Teaching Network
Authors:Shuqing Bian(PhD student at RUC),Xu Chen,Xin Zhao,Kun Zhou, Yupeng Hou, Yang Song, Ji-Rong Wen
Cooresponding Author: Prof. Xin Zhao
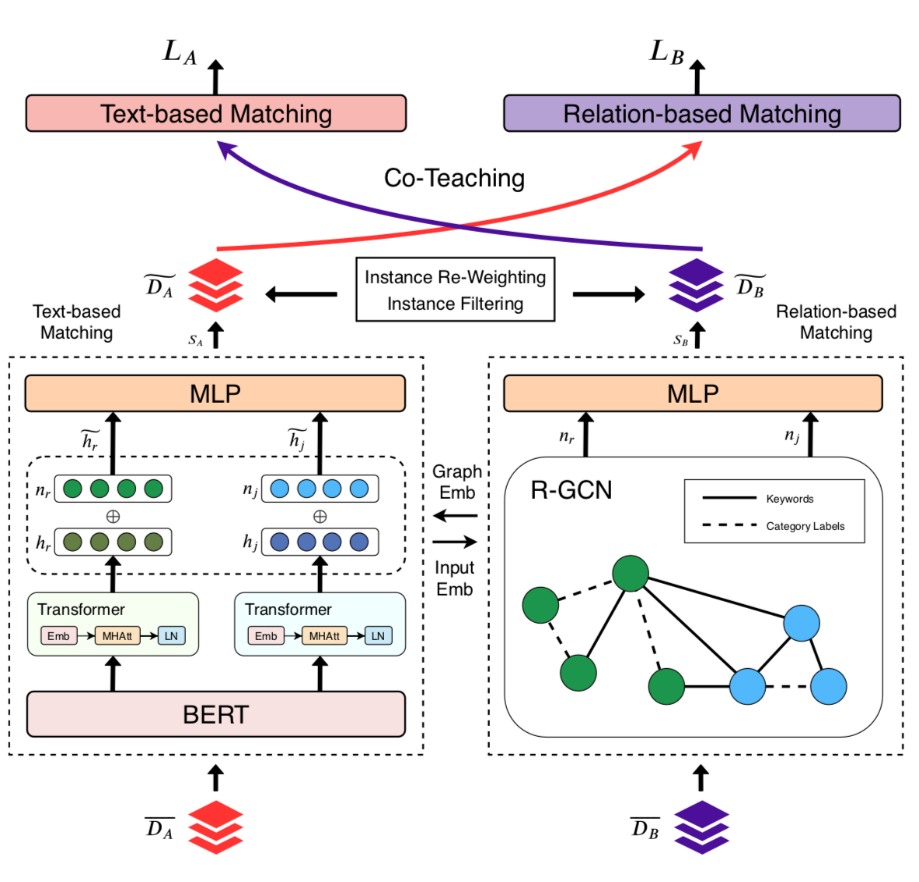
Abstract: With the ever-increasing growth of online recruitment data, job-resume matching has become an important task to automatically match jobs with suitable resumes. This task is typically casted as a supervised text matching problem. Supervised learning is powerful when the labeled data is sufficient. However, on online recruitment platforms, job-resume interaction data is sparse and noisy, which affects the performance of job-resume match algorithms. To alleviate these problems, in this paper, we propose a novel multi-view co-teaching network from sparse interaction data for job-resume matching. Our network consists of two major components, namely text-based matching model and relation-based matching model. The two parts capture semantic compatibility in two different views, and complement each other. In order to address the challenges from sparse and noisy data, we design two specific strategies to combine the two components. First, two components share the learned parameters or representations, so that the original representations of each component can be enhanced. More importantly, we adopt a co-teaching mechanism to reduce the influence of noise in training data. The core idea is to let the two components help each other by selecting more reliable training instances. The two strategies focus on representation enhancement and data enhancement, respectively. Compared with pure text-based matching models, the proposed approach is able to learn better data representations from limited or even sparse interaction data, which is more resistible to noise in training data. Experiment results have demonstrated that our model is able to outperform state-of-the-art methods for job-resume matching.
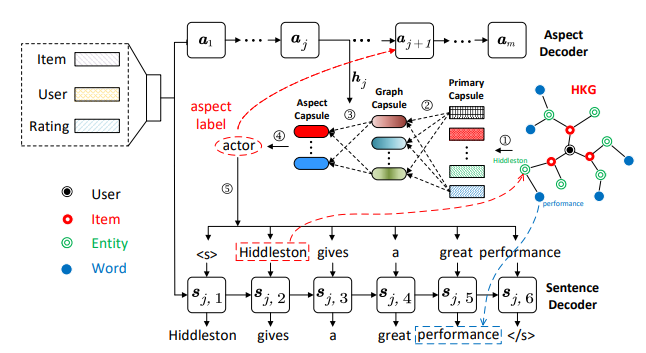
Title:Knowledge-Enhanced Personalized Review Generation with Capsule Graph Neural Network
Authors:Junyi Li(Ph.D. student at RUC),Siqing Li,Xin Zhao,Gaole He, Zhicheng Wei, Jing Yuan, Ji-Rong Wen
Cooresponding Author: Prof. Xin Zhao
Abstract: Personalized review generation (PRG) aims to automatically produce review text reflecting user preference, which is a challenging natural language generation task. Most of previous studies do not explicitly model factual description of products, tending to generate uninformative content. Moreover, they mainly focus on word-level generation, but cannot accurately reflect more abstractive user preference in multiple aspects. To address the above issues, we propose a novel knowledge-enhanced PRG model based on capsule graph neural network~(Caps-GNN). We first construct a heterogeneous knowledge graph (HKG) for utilizing rich item attributes. We adopt Caps-GNN to learn graph capsules for encoding underlying characteristics from the HKG. Our generation process contains two major steps, namely aspect sequence generation and sentence generation. First, based on graph capsules, we adaptively learn aspect capsules for inferring the aspect sequence. Then, conditioned on the inferred aspect label, we design a graph-based copy mechanism to generate sentences by incorporating related entities or words from HKG. To our knowledge, we are the first to utilize knowledge graph for the PRG task. The incorporated KG information is able to enhance user preference at both aspect and word levels. Extensive experiments on three real-world datasets have demonstrated the effectiveness of our model on the PRG task.
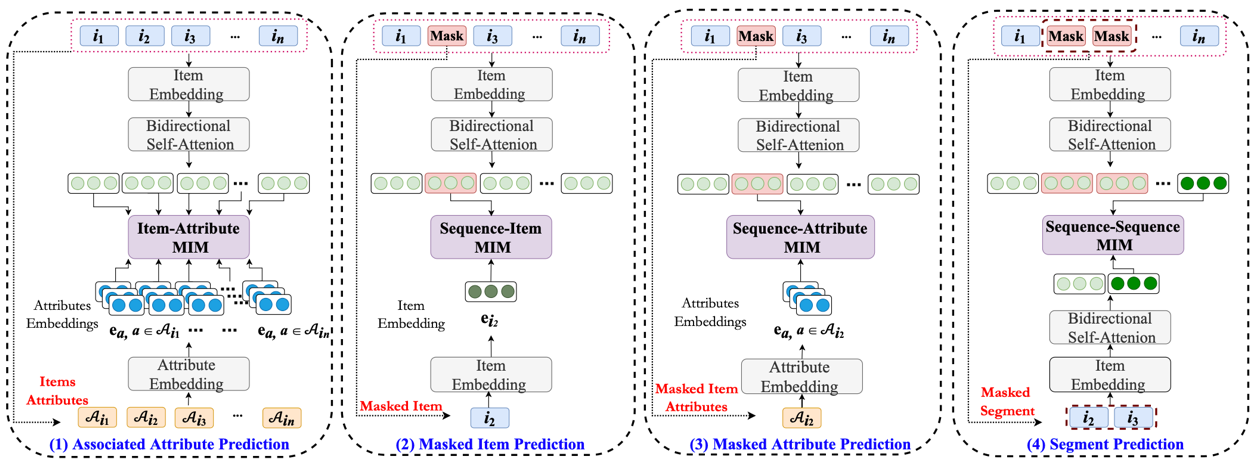
Title:S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization
Authors:Kun Zhou(Ph.D. student at RUC),Hui Wang(Master student at RUC),Xin Zhao,Yutao Zhu, Sirui Wang, Fuzheng Zhang, Ji-Rong Wen
Cooresponding Author: Prof. Xin Zhao
Abstract: Recently, significant progress has been made in sequential recommendation with deep learning. Existing neural sequential recommendation models usually rely on the item prediction loss to learn model parameters or data representations. However, the model trained with this loss is prone to suffer from data sparsity problem. Since it overemphasizes the final performance, the association or fusion between context data and sequence data has not been well captured and utilized for sequential recommendation. To tackle this problem, we propose the model S^3-Rec, which stands for Self-Supervised learning for Sequential Recommendation, based on the self-attentive neural architecture. The main idea of our approach is to utilize the intrinsic data correlation to derive self-supervision signals and enhance the data representations via pre-training methods for improving sequential recommendation. For our task, we devise four auxiliary self-supervised objectives to learn the correlations among attribute, item, subsequence, and sequence by utilizing the mutual information maximization (MIM) principle. MIM provides a unified way to characterize the correlation between different types of data, which is particularly suitable in our scenario. Extensive experiments conducted on six real-world datasets demonstrate the superiority of our proposed method over existing state-of-the-art methods, especially when only limited training data is available. Besides, we extend our self-supervised learning method to other recommendation models, which also improve their performance.