Chinese University Creates Sora-like Video Diffusion Transformer, Paper Accepted by ICLR 2024
The release of OpenAI’s Sora on February 16 marked a huge breakthrough in the domain of video generation. Leveraging Diffusion Transformer architecture, Sora distinguishes itself from the majority of mainstream methods (extended from 2D Stable Diffusion) on the market.
The reasons behind Sora’s insistence on using diffusion transformers can be found in a paper published in ICLR 2024 (VDT: General-purpose Video Diffusion Transformers via Mask Modeling) around the same time.

This endeavor, led by a research team from Renmin University of China (RUC) in collaboration with the University of California, Berkeley, the University of Hong Kong, and others, was first unveiled to the public on the arXiv website in May 2023. The team proposed a transformer-based unified framework for video generation - Video Diffusion Transformer (VDT), and provided detailed explanations for the adoption of transformers.
l Paper Title:VDT: General-purpose Video Diffusion Transformers via Mask Modeling
l Website:Openreview: https://openreview.net/pdf?id='''Un0rgm9f04
l arXiv address: https://arxiv.org/abs/2305.13311
l Project Address:VDT: General-purpose Video Diffusion Transformers via Mask Modeling
l Code Address:https://github.com/RERV/VDT
1. Advantages and Innovations of VDT
Researchers say that VDT has the following advantages in the domain of video generation:
Unlike U-Net, which is primarily designed for images, transformers harness their robust tokenization and attention mechanisms to capture long-range or irregular temporal dependencies. Therefore, they are better at processing temporal data.
For video diffusion to align with the real world, the model must learn (or memorize) world [n1] knowledge, such as spatiotemporal relationships and physical laws. Thus, model capacity is a crucial component of video diffusion. Transformers have proven to be highly scalable, as evidenced by models like PaLM with up to 540 billion parameters, while the largest 2D U-Net model at the time was only 2.6 billion parameters (SDXL). This makes transformers more suitable for tackling the challenges of video generation compared to 3D U-Net.
The field of video generation encompasses tasks such as unconditional generation, video prediction, interpolation, and text-to-image generation. Previous research largely focused on individual tasks, often requiring the incorporation of specialized modules for downstream fine-tuning. Additionally, these tasks involve diverse conditioning information, which may vary across different frames and modalities, necessitating a powerful architecture capable of handling varying input lengths and modalities. The introduction of transformers enables the unification of these tasks.
The innovations of VDT primarily include the following aspects:
The application of transformers to diffusion-based video generation demonstrates the immense potential of transformers in the field of video generation. VDT excels in its ability to capture temporal dependencies, enabling the generation of temporally consistent video frames, including simulating the physics and dynamics of 3D objects over time.
The proposal of a unified spatiotemporal masking mechanism enables VDT to handle various video generation tasks, achieving widespread application of the technology. VDT’s flexible handling of conditioning information, with simple token spatial concatenation, effectively unifies information of different lengths and modalities. Moreover, through integration with the proposed spatiotemporal masking mechanism, VDT becomes a general-purpose video diffuser for harnessing a range of video generation tasks, including unconditional generation, subsequent frame prediction, interpolation, image-to-video generation, and video frame completion, without modifying the model structure.
2. Detailed Analysis of VDT’s Structure
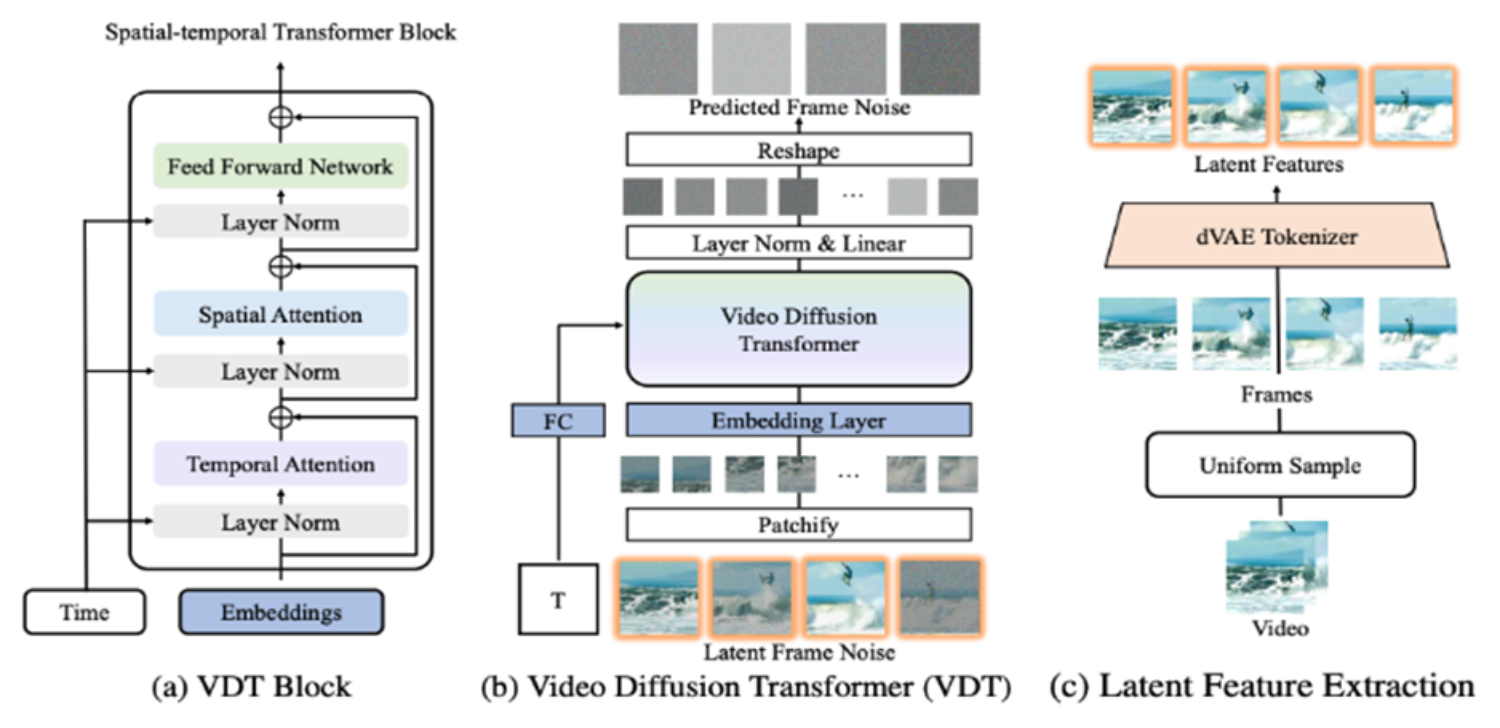
The VDT framework bears striking resemblances to that of Sora, encompassing the following components:
Input/Output Features: The objective of VDT is to generate a video clip ∈ RF ×H×W×3, consisting of F frames of size H × W. However, using raw pixels as input for VDT can lead to extremely heavy computation, particularly when F is large. To address this issue, VDT takes inspiration from LDM and projects the video into a latent space using a pre-trained VAE tokenizer from LDM. This speeds up VDT by reducing the input and output to latent feature/noise F ∈ RF ×H/8×W/8×C, consisting of F frame latent features of size H/8 × W/8. Here, 8 is the downsample rate of the VAE tokenizer, and C denotes the latent feature dimension.
Linear Embedding: Following the approach of Vision Transformers, VDT divides the latent video feature representation into non-overlapping patches of size N×N.
Spatio-Temporal Transformer Block: Inspired by the success of space-time self-attention in video modeling, VDT inserts a temporal attention layer into the transformer block to obtain the temporal modeling ability. Specifically, each transformer block comprises a multi-head temporal-attention layer, a multi-head spatial-attention layer, and a fully connected feedforward network.
Comparing Sora’s latest technical report, it can be observed that VDT and Sora exhibit only subtle differences in implementation details.
First, VDT adopts a method where attention mechanisms are separately applied in the temporal and spatial dimensions, whereas Sora merges the temporal and spatial dimensions to handle them through a single attention mechanism. This separated attention approach is quite common in the video domain and is often viewed as a compromise under memory constraints. The choice of separated attention in VDT is also driven by considerations of limited computational resources. Sora’s robust video dynamics capabilities may stem from its holistic spatio-temporal attention mechanism.
Secondly, unlike VDT, Sora also considers the integration of text conditions. Previous research has explored text condition integration based on Transformers (e.g., PIXART-α). Here, it is speculated that Sora may further incorporate cross-attention mechanisms into its modules. Of course, directly concatenating text and noise frames as conditional inputs is also a potential approach.
During the research process of VDT, the research team replaced the commonly used backbone network U-Net with transformers. This not only validates the effectiveness of transformers in video diffusion tasks, demonstrating advantages in scalability and continuity enhancement but also stimulates further consideration of the potential value Transformation.
With the success of GPT and the popularity of autoregressive (AR) models, researchers have begun to explore deeper applications of transformers in the field of video generation, pondering whether they can provide new methods for achieving visual intelligence. One closely related task in the video generation domain is video prediction. The idea of predicting the next video frame as a path to visual intelligence may seem simple, but it is actually a problem that many researchers are collectively concerned with.
Given this, researchers hope to further adapt and optimize their models for video prediction tasks. Video prediction can also be viewed as conditional generation, where the given conditional frames are the preceding frames of the video. VDT primarily considers the following three conditional generation methods:
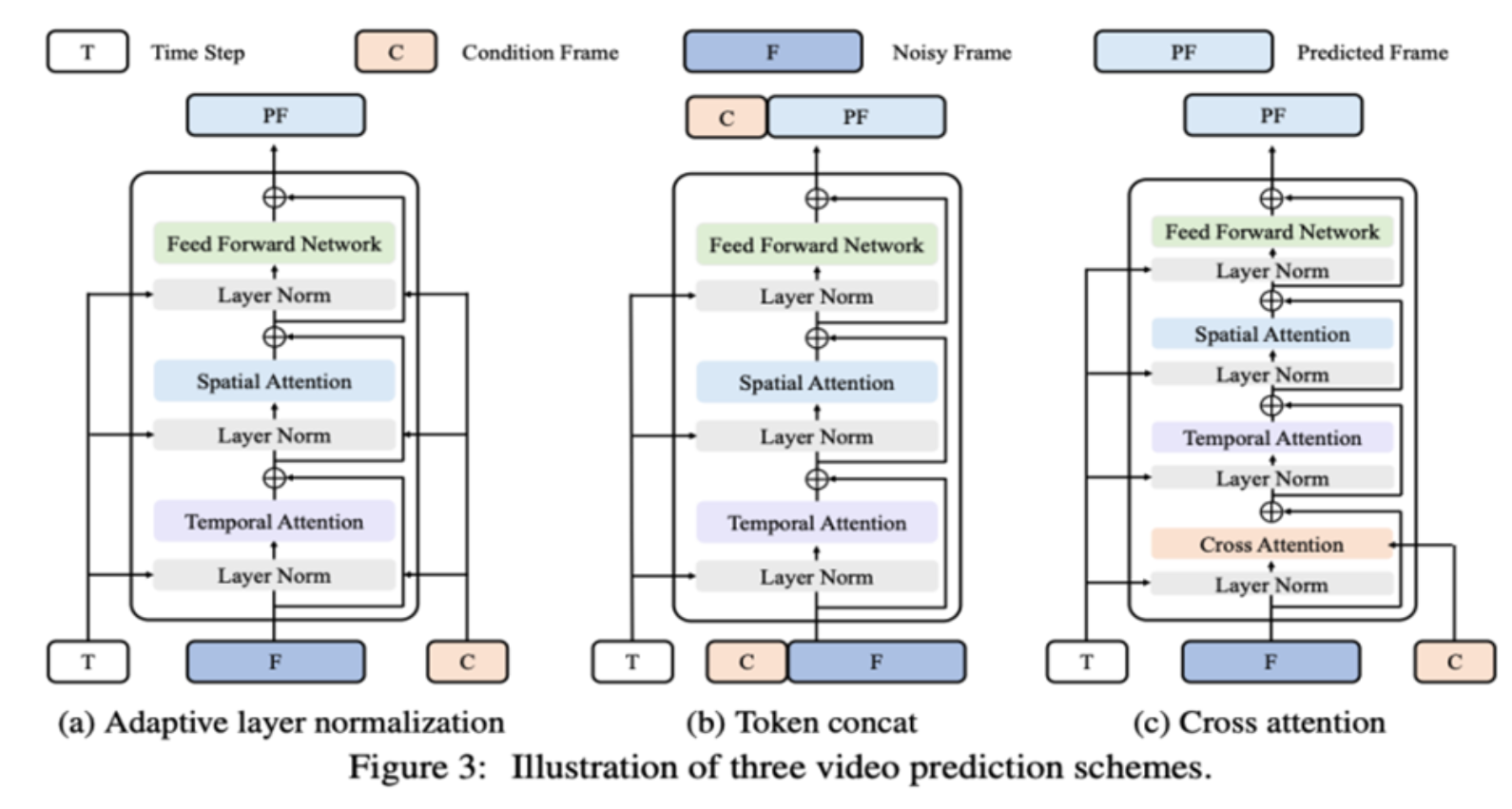
Adaptive Layer Normalization: A direct approach to achieve video prediction is to integrate conditional frame features into the layer normalization of the VDT Block, similar to how we integrate time information into the diffusion process.
Cross-Attention: Researchers also explore the use of cross-attention as a video prediction scheme, where conditional frames serve as keys and values, while the noisy frame serves as the query. This allows for the fusion of conditional information with the noisy frame. Prior to entering the cross-attention layer, the features of conditional frames are extracted using a VAE tokenizer and are patchfied. Additionally, spatial and temporal position embeddings are added to help VDT learn corresponding information within the conditional frames.
Token Concatenation: Since the VDT model adopts pure transformer architectures, using conditional frames directly as input tokens is a more intuitive approach. Researchers achieve this by concatenating conditional frames (latent features) and noisy frames at the token level, which are then fed into VDT. Subsequently, they split the output frame sequence of VDT and used the predicted frames for the diffusion process, as shown in Figure 3 (b). Researchers find that this approach demonstrates the fastest convergence speed and provides better performance in the final results compared to the first two methods. Moreover, researchers find that even when using fixed-length conditional frames during training, VDT can still accept conditional frames of arbitrary lengths as input and output consistent predicted features.
Under the framework of VDT, to achieve video prediction tasks, no modifications need to be made to the network structure; only changes to the model’s inputs are required. This discovery raises an intuitive question: can we further leverage this scalability to extend VDT to more diverse video generation tasks, such as generating videos from images, without introducing any additional modules or parameters?
By reviewing VDT’s functionalities in unconditional generation and video prediction, the only difference lies in the types of input features. Specifically, inputs can either be pure noise latent features or concatenations of conditions and noise latent features. Subsequently, researchers introduce Unified Spatial-Temporal Mask Modeling to unify conditional inputs, as shown in Figure 4.
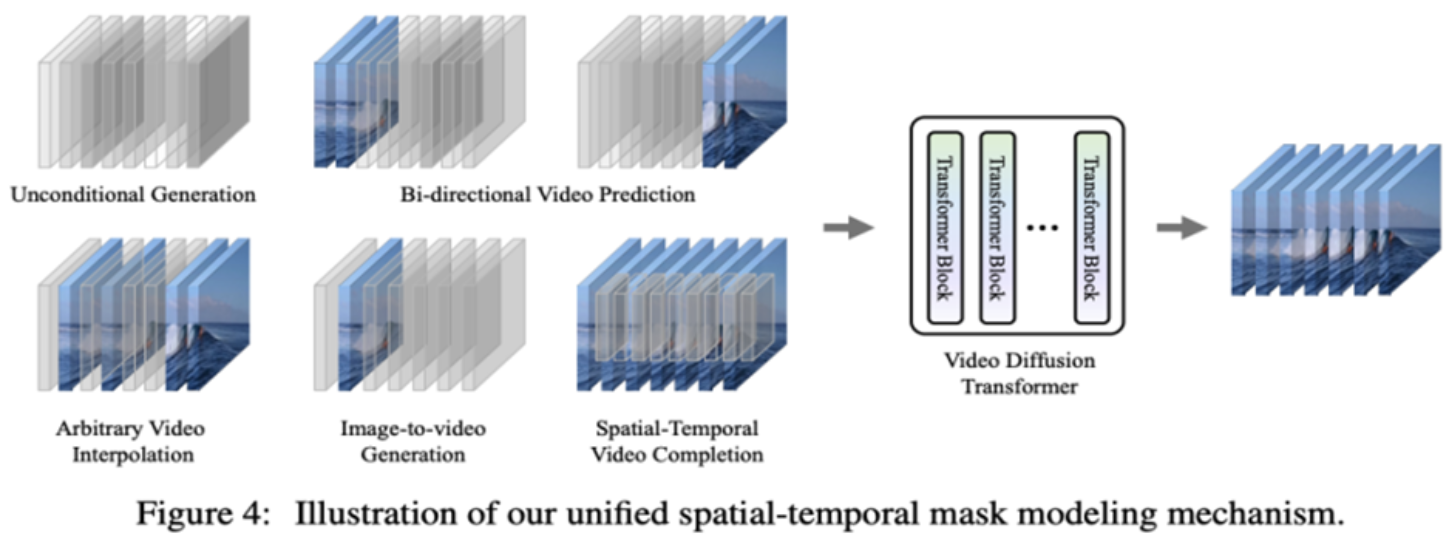
3. Performance Evaluation of VDT
Through the aforementioned methods, the VDT model not only seamlessly handles unconditional video generation and video prediction tasks but also extends to a broader range of video generation domains, such as video frame interpolation, by simply adjusting input features. This demonstration of flexibility and scalability showcases the powerful potential of the VDT framework, providing new directions and possibilities for future video generation technologies.

Interestingly, in addition to text-to-video, OpenAI also demonstrated Sora’s impressive performance in other tasks, including image-based generation, video prediction, and fusion of different video clips, which are very similar to downstream tasks supported by the Unified Spatial-Temporal Mask Modeling proposed by researchers. Additionally, references to Kaiming’s MAE are also cited, suggesting that Sora likely employs a training method similar to MAE at the lower levels.
Researchers also explored the simulation of simple physical laws by the generative model VDT. They conducted experiments on the Physion dataset, where VDT used the first 8 frames as conditional frames and predicted the next 8 frames. In the first example (top two rows) and the third example (bottom two rows), VDT successfully simulated physical processes, including a ball moving along a parabolic trajectory and a ball rolling on flat ground and colliding with a cylinder. In the second example (middle two rows), VDT captured the velocity/momentum of the ball as it stopped before colliding with the cylinder. This demonstrates that the Transformer architecture is capable of learning certain physical laws.

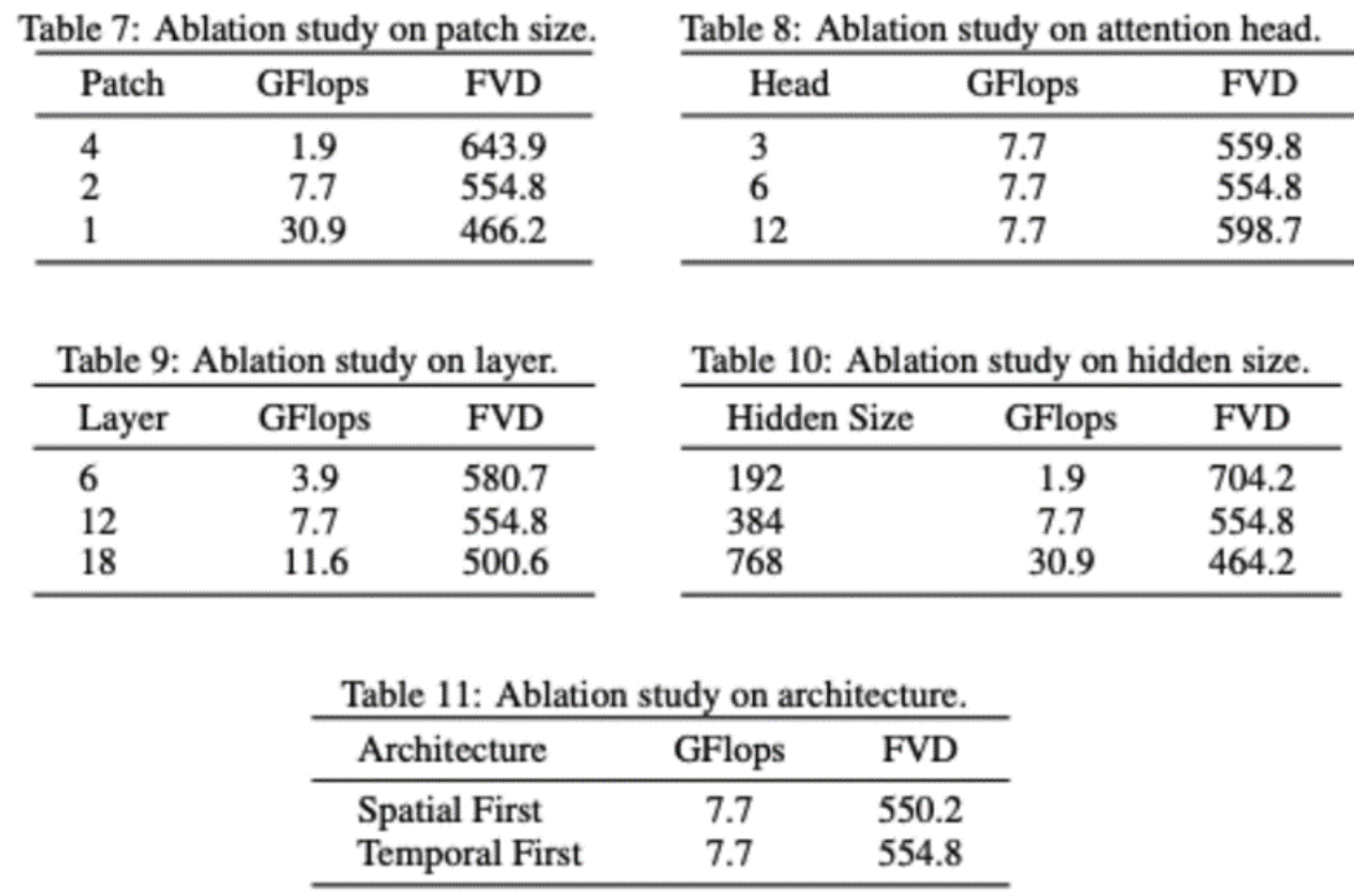
Researchers also conducted some ablation studies on the VDT model’s structure. The results indicate that reducing the patch size, increasing the number of layers, and increasing the Hidden Size can further improve the model’s performance. The position of temporal and spatial attention and the number of attention heads have minimal impact on the model’s results. With the same GFlops, some design trade-offs are needed, and overall, there is no significant difference in the model’s performance. However, increasing GFlops leads to better results, demonstrating the scalability of VDT or Transformer architecture.
The effectiveness and flexibility of VDT demonstrate the efficacy of transformer structures in video generation. Due to limitations in computational resources, VDT was only experimented on a few small-scale academic datasets. We look forward to future research exploring new directions and applications in video generation technology based on VDT and hope that Chinese companies will soon launch domestic Sora models.