Multimodal Pre-Training Research Paper From GSAI Was Pulished By Nature Communications
On June 2nd, a research paper titled “Towards artificial general intelligence via a multimodal foundation model”from GSAI was published by Nature Communications. Professor Zhiwu Lu, Tenured Associate Professor Hao Sun, and Executive Dean of GSAI, Professor Ji-Rong Wen are the co-corresponding authors, and Ph.D. student Nanyi Fei is the first author. Nature Communications is one of the Nature Portfolio journals, which publishes high-quality research from all areas of the natural sciences. Papers published by the journal aim to represent important advances of significance to specialists within each field. Nature Communications launched in April 2010, having a 2-year impact factor 17.694 (2022).

The fundamental goal of artificial intelligence (AI) is to mimic the core cognitive activities of human including perception and reasoning. Although tremendous success has been achieved in various AI research fields, the extremely high requirements on data availability, computational resources, and algorithm efficiency resulted in most of existing works to have only single-cognitive ability. To overcome this limitation and take a solid step towards artificial general intelligence (AGI), the authors develop a foundation model (i.e., pre-training model) inspired by human brain's processing of multimodal information (see Figure 1a). To gain the generalization power, the authors propose to pre-train the foundation model with weak semantic correlation data rather than expecting exact alignment between image regions and words (see Figure 1b), because complex human emotions and thoughts would be lost if strong semantic correlation data is used. Trained on large-scale image-text pairs crawled from the Internet, the multimodal foundation model shows strong generalization and imagination abilities. The authors' attempt at model interpretability also suggests that these abilities are likely to be attributed to the weak semantic correlation data assumption.
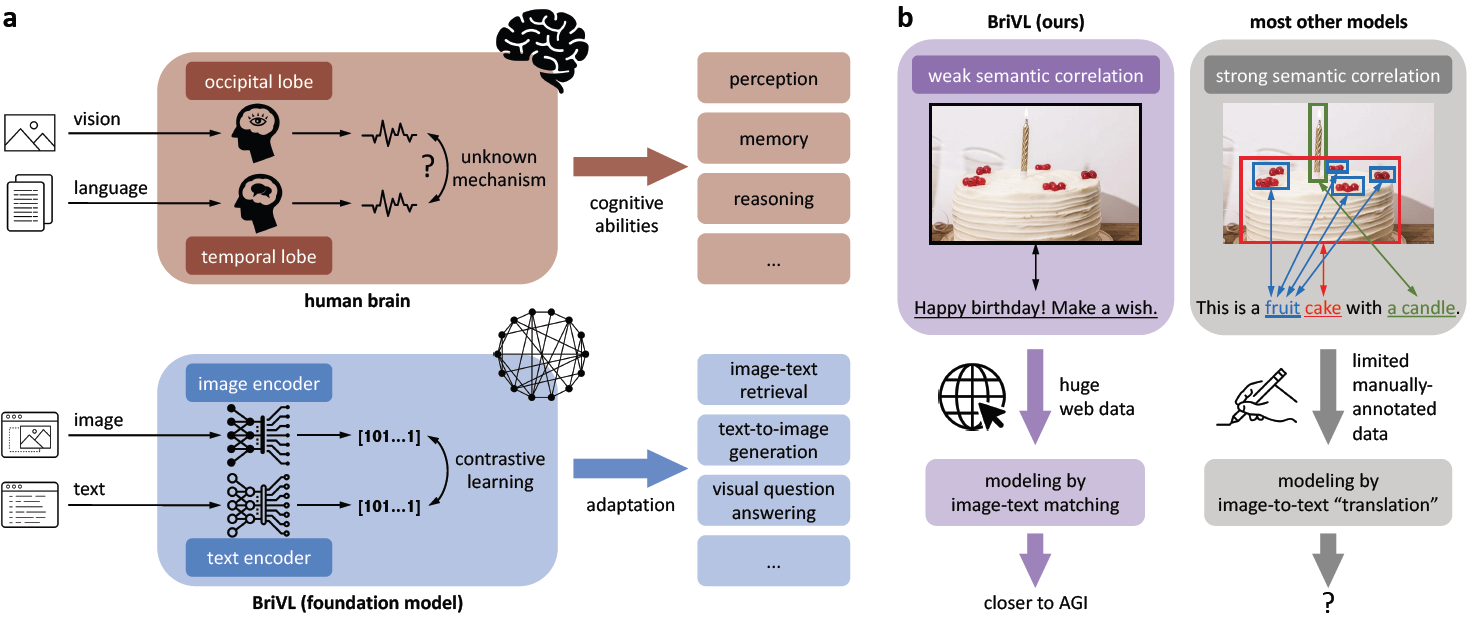
Figure 1: Overarching concept of our BriVL model with weak training data assumption. a. Comparison between the human brain and our multimodal foundation model BriVL for coping with both vision and language information. b. Comparison between modeling weak semantic correlation data and modeling strong semantic correlation data.
This work is an important result of the WenLan project. The authors not only develop a relatively resource-saving and easy-to-deploy multimodal foundation model, but also make an attempt at the model interpretability. By neural network visualization and text-to-image generation, the authors visually reveal how a multimodal foundation model understands language and how it makes imagination or association about words and sentences (see Figure 2). Extensive experiments on other downstream tasks show the cross-domain learning/transfer ability of BriVL and it even appears to acquire abilities in imagination and reasoning. The model design based on the momentum mechanism proposed in this work is expected to reduce researchers' demand for computational resources, and the two-tower design also improves the scalability of the model. Moreover, multimodal foundation models will also be helpful in many AI+ fields, such as using multimodal information for better diagnosis or assisting neuroscientists in the study of multimodal mechanisms in human brains.

Figure 2: Text-to-image generation examples by VQGAN inversion with our BriVL. VQGAN and BriVL are both frozen during the process.
Paper Information
Title: Towards artificial general intelligence via a multimodal foundation model
Authors: Nanyi Fei, Zhiwu Lu*, Yizhao Gao, Guoxing Yang, Yuqi Huo, Jingyuan Wen, Haoyu Lu, Ruihua Song, Xin Gao, Tao Xiang, Hao Sun* and Ji-Rong Wen* (* corresponding authors)
Paper Link: https://www.nature.com/articles/s41467-022-30761-2
Code Link: https://github.com/neilfei/brivl-nmi